 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable N-gram Objective on Abstractive Summarization
Paper and Code
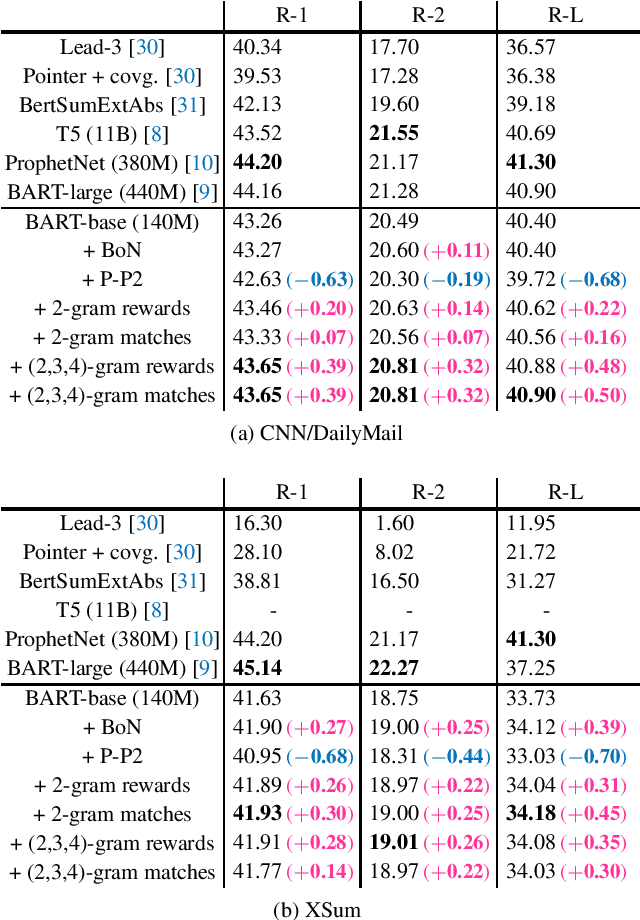

ROUGE is a standard automatic evaluation metric based on n-grams for sequence-to-sequence tasks, while cross-entropy loss is an essential objective of neural network language model that optimizes at a unigram level. We present differentiable n-gram objectives, attempting to alleviate the discrepancy between training criterion and evaluating criterion. The objective maximizes the probabilistic weight of matched sub-sequences, and the novelty of our work is the objective weights the matched sub-sequences equally and does not ceil the number of matched sub-sequences by the ground truth count of n-grams in reference sequence. We jointly optimize cross-entropy loss and the proposed objective, providing decent ROUGE score enhancement over abstractive summarization dataset CNN/DM and XSum, outperforming alternative n-gram objectives.