 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleDecipher: Robust and Explainable Detection of LLM-Generated Texts with Stylistic Analysis
Oct 14, 2025With the increasing integration of large language models (LLMs) into open-domain writing, detecting machine-generated text has become a critical task for ensuring content authenticity and trust. Existing approaches rely on statistical discrepancies or model-specific heuristics to distinguish between LLM-generated and human-written text. However, these methods struggle in real-world scenarios due to limited generalization, vulnerability to paraphrasing, and lack of explainability, particularly when facing stylistic diversity or hybrid human-AI authorship. In this work, we propose StyleDecipher, a robust and explainable detection framework that revisits LLM-generated text detection using combined feature extractors to quantify stylistic differences. By jointly modeling discrete stylistic indicators and continuous stylistic representations derived from semantic embeddings, StyleDecipher captures distinctive style-level divergences between human and LLM outputs within a unified representation space. This framework enables accurate, explainable, and domain-agnostic detection without requiring access to model internals or labeled segments. Extensive experiments across five diverse domains, including news, code, essays, reviews, and academic abstracts, demonstrate that StyleDecipher consistently achieves state-of-the-art in-domain accuracy. Moreover, in cross-domain evaluations, it surpasses existing baselines by up to 36.30%, while maintaining robustness against adversarial perturbations and mixed human-AI content. Further qualitative and quantitative analysis confirms that stylistic signals provide explainable evidence for distinguishing machine-generated text. Our source code can be accessed at https://github.com/SiyuanLi00/StyleDecipher.
Model-Agnostic Sentiment Distribution Stability Analysis for Robust LLM-Generated Texts Detection
Aug 09, 2025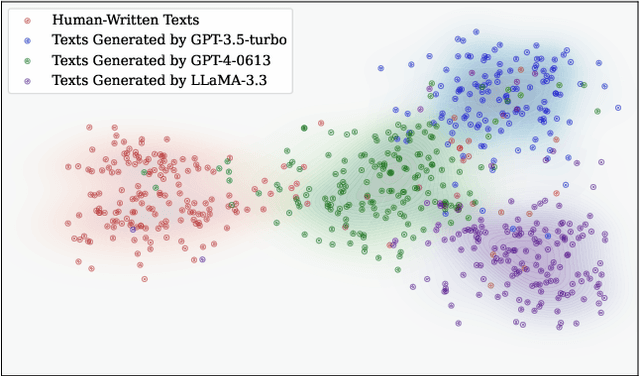

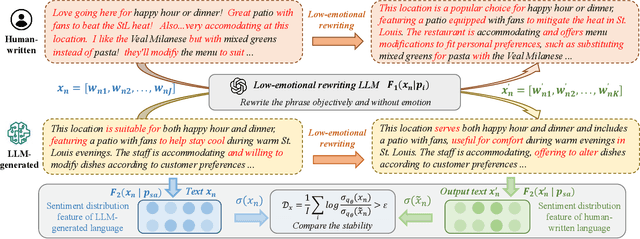

The rapid advancement of large language models (LLMs) has resulted in increasingly sophisticated AI-generated content, posing significant challenges in distinguishing LLM-generated text from human-written language. Existing detection methods, primarily based on lexical heuristics or fine-tuned classifiers, often suffer from limited generalizability and are vulnerable to paraphrasing, adversarial perturbations, and cross-domain shifts. In this work, we propose SentiDetect, a model-agnostic framework for detecting LLM-generated text by analyzing the divergence in sentiment distribution stability. Our method is motivated by the empirical observation that LLM outputs tend to exhibit emotionally consistent patterns, whereas human-written texts display greater emotional variability. To capture this phenomenon, we define two complementary metrics: sentiment distribution consistency and sentiment distribution preservation, which quantify stability under sentiment-altering and semantic-preserving transformations. We evaluate SentiDetect on five diverse datasets and a range of advanced LLMs,including Gemini-1.5-Pro, Claude-3, GPT-4-0613, and LLaMa-3.3. Experimental results demonstrate its superiority over state-of-the-art baselines, with over 16% and 11% F1 score improvements on Gemini-1.5-Pro and GPT-4-0613, respectively. Moreover, SentiDetect also shows greater robustness to paraphrasing, adversarial attacks, and text length variations, outperforming existing detectors in challenging scenarios.
LoRAP: Transformer Sub-Layers Deserve Differentiated Structured Compression for Large Language Models
Apr 15, 2024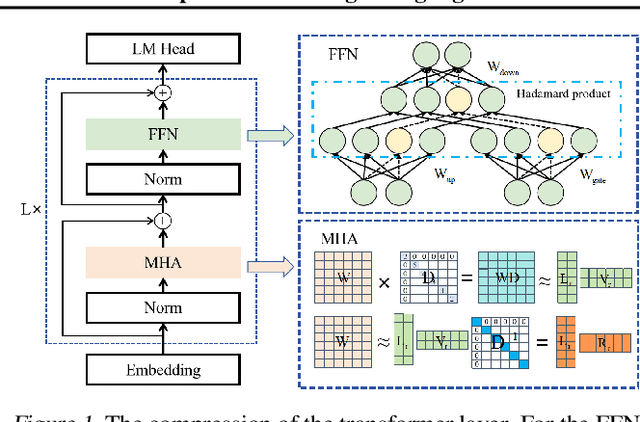



Large language models (LLMs) show excellent performance in difficult tasks, but they often require massive memories and computational resources. How to reduce the parameter scale of LLMs has become research hotspots. In this study, we make an important observation that the multi-head self-attention (MHA) sub-layer of Transformer exhibits noticeable low-rank structure, while the feed-forward network (FFN) sub-layer does not. With this regard, we design a mixed compression model, which organically combines Low-Rank matrix approximation And structured Pruning (LoRAP). For the MHA sub-layer, we propose an input activation weighted singular value decomposition method to strengthen the low-rank characteristic. Furthermore, we discover that the weight matrices in MHA sub-layer have different low-rank degrees. Thus, a novel parameter allocation scheme according to the discrepancy of low-rank degrees is devised. For the FFN sub-layer, we propose a gradient-free structured channel pruning method. During the pruning, we get an interesting finding that the least important 1% of parameter actually play a vital role in model performance. Extensive evaluations on zero-shot perplexity and zero-shot task classification indicate that our proposal is superior to previous structured compression rivals under multiple compression ratios.