 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeXposure-Claw: An Agentic System for DeFi Risk Supervision
Jun 17, 2026Decentralized finance exposes supervisors to fast-moving, networked credit risks. General-purpose LLM agents fit this setting poorly: they over-read weak evidence and recommend high-stakes interventions, while existing evaluations offer no regulator-aligned way to measure the resulting false alarms. We introduce DeXposure-Claw, a forecast-grounded agentic supervision system that routes LLM decisions through structured evidence: (1) DeXposure-FM, a graph time-series foundation model, forecasts future exposure networks; (2) deterministic monitors and stress scenarios then turn those forecasts into typed alerts, attribution signals, and scenario evidence; and (3) data-health and confidence gates constrain escalation before DeXposure-Claw emits auditable supervisory tickets with rationales. We further develop DeXposure-Bench, a six-axis evaluation harness, whose decision axis scores tickets against a regulator-aligned absolute-loss ground truth and an explicit false-intervention rate. Experiments on five years of weekly real data fully support our system. Code is at https://github.com/EVIEHub/DeXposure-Claw.
Auditing Asset-Specific Preferences in Financial Large Language Models: Evidence from Bitcoin Representations and Portfolio Allocation
Jun 01, 2026Large language models now power robo-advisors and trading agents, yet whether they carry built-in biases toward specific assets is largely untested. We ask three questions: do LLMs systematically prefer certain financial instruments; can an internal representation with causal leverage over those preferences be identified; and does that representation affect downstream financial decisions? We develop a three-level audit protocol and apply it to Bitcoin. First, a behavioral audit of eight frontier LLMs shows that Bitcoin's ranking among money-like instruments is frame-dependent: models place it around rank 5 of 8 as "reliable money" but near the top under crisis and autonomous-agent frames, and an attribute-swap experiment confirms rankings track functional properties, not names. Second, we open a model's internals: a search across thousands of sparse-autoencoder features in Gemma 3 identifies a dominant Bitcoin-selective feature. Amplifying it shifts the model toward the asset and suppressing it shifts the model away, even when "Bitcoin" never appears in the prompt. Third, we test financial consequences: amplification raises Bitcoin's portfolio share by 5.2 percentage points while suppression lowers it by 4.6 pp, with amplification reallocating within crypto and suppression cutting total crypto exposure. We characterize this as bounded behavioral leverage (leverage meaning causal influence over outputs, not financial leverage): an identifiable internal feature can be perturbed to move financial choices, but only within measurable limits. The framework links internal representations to external recommendations, validated with random controls and mechanism boundaries. As LLMs become autonomous financial agents, this is a first step toward a behavioral layer for emerging know-your-agent (KYA) standards: knowing what an agent prefers, and how far that preference can be moved.
Aligning to Illusions: Choice Blindness in Human and AI Feedback
Mar 09, 2026Reinforcement Learning from Human Feedback (RLHF) assumes annotator preferences reflect stable internal states. We challenge this through three experiments spanning the preference pipeline. In a human choice blindness study, 91% of surreptitiously swapped preferences go undetected, extending choice blindness to third-person evaluative comparison of unfamiliar text. Testing fifteen LLM judges as potential replacements, we find detection relies on shallow text matching rather than genuine self-monitoring: removing prior reasoning from context causes blindness to surge from near-zero to over 50%, while explicit social pressure induces near-universal compliance. In a dose-response experiment across two architectures from 86M to 2B parameters, one-sixth to one-third of labels must be corrupted before the reward signal halves, yet standard pairwise accuracy remains virtually unchanged. A Best-of-N evaluation confirms this translates to downstream policy degradation: at 50% corruption, reward-guided selection produces no improvement over random sampling, while the proxy model reports monotonically increasing scores. Together, these results reveal a preference construction problem: the signal entering RLHF is shaped by elicitation context in ways that neither human metacognition, LLM self-monitoring, nor standard evaluation metrics can detect.
DeXposure-FM: A Time-series, Graph Foundation Model for Credit Exposures and Stability on Decentralized Financial Networks
Feb 03, 2026Credit exposure in Decentralized Finance (DeFi) is often implicit and token-mediated, creating a dense web of inter-protocol dependencies. Thus, a shock to one token may result in significant and uncontrolled contagion effects. As the DeFi ecosystem becomes increasingly linked with traditional financial infrastructure through instruments, such as stablecoins, the risk posed by this dynamic demands more powerful quantification tools. We introduce DeXposure-FM, the first time-series, graph foundation model for measuring and forecasting inter-protocol credit exposure on DeFi networks, to the best of our knowledge. Employing a graph-tabular encoder, with pre-trained weight initialization, and multiple task-specific heads, DeXposure-FM is trained on the DeXposure dataset that has 43.7 million data entries, across 4,300+ protocols on 602 blockchains, covering 24,300+ unique tokens. The training is operationalized for credit-exposure forecasting, predicting the joint dynamics of (1) protocol-level flows, and (2) the topology and weights of credit-exposure links. The DeXposure-FM is empirically validated on two machine learning benchmarks; it consistently outperforms the state-of-the-art approaches, including a graph foundation model and temporal graph neural networks. DeXposure-FM further produces financial economics tools that support macroprudential monitoring and scenario-based DeFi stress testing, by enabling protocol-level systemic-importance scores, sector-level spillover and concentration measures via a forecast-then-measure pipeline. Empirical verification fully supports our financial economics tools. The model and code have been publicly available. Model: https://huggingface.co/EVIEHub/DeXposure-FM. Code: https://github.com/EVIEHub/DeXposure-FM.
WeGA: Weakly-Supervised Global-Local Affinity Learning Framework for Lymph Node Metastasis Prediction in Rectal Cancer
May 15, 2025Accurate lymph node metastasis (LNM) assessment in rectal cancer is essential for treatment planning, yet current MRI-based evaluation shows unsatisfactory accuracy, leading to suboptimal clinical decisions. Developing automated systems also faces significant obstacles, primarily the lack of node-level annotations. Previous methods treat lymph nodes as isolated entities rather than as an interconnected system, overlooking valuable spatial and contextual information. To solve this problem, we present WeGA, a novel weakly-supervised global-local affinity learning framework that addresses these challenges through three key innovations: 1) a dual-branch architecture with DINOv2 backbone for global context and residual encoder for local node details; 2) a global-local affinity extractor that aligns features across scales through cross-attention fusion; and 3) a regional affinity loss that enforces structural coherence between classification maps and anatomical regions. Experiments across one internal and two external test centers demonstrate that WeGA outperforms existing methods, achieving AUCs of 0.750, 0.822, and 0.802 respectively. By effectively modeling the relationships between individual lymph nodes and their collective context, WeGA provides a more accurate and generalizable approach for lymph node metastasis prediction, potentially enhancing diagnostic precision and treatment selection for rectal cancer patients.
ABS-Mamba: SAM2-Driven Bidirectional Spiral Mamba Network for Medical Image Translation
May 12, 2025Accurate multi-modal medical image translation requires ha-rmonizing global anatomical semantics and local structural fidelity, a challenge complicated by intermodality information loss and structural distortion. We propose ABS-Mamba, a novel architecture integrating the Segment Anything Model 2 (SAM2) for organ-aware semantic representation, specialized convolutional neural networks (CNNs) for preserving modality-specific edge and texture details, and Mamba's selective state-space modeling for efficient long- and short-range feature dependencies. Structurally, our dual-resolution framework leverages SAM2's image encoder to capture organ-scale semantics from high-resolution inputs, while a parallel CNNs branch extracts fine-grained local features. The Robust Feature Fusion Network (RFFN) integrates these epresentations, and the Bidirectional Mamba Residual Network (BMRN) models spatial dependencies using spiral scanning and bidirectional state-space dynamics. A three-stage skip fusion decoder enhances edge and texture fidelity. We employ Efficient Low-Rank Adaptation (LoRA+) fine-tuning to enable precise domain specialization while maintaining the foundational capabilities of the pre-trained components. Extensive experimental validation on the SynthRAD2023 and BraTS2019 datasets demonstrates that ABS-Mamba outperforms state-of-the-art methods, delivering high-fidelity cross-modal synthesis that preserves anatomical semantics and structural details to enhance diagnostic accuracy in clinical applications. The code is available at https://github.com/gatina-yone/ABS-Mamba
GEOcc: Geometrically Enhanced 3D Occupancy Network with Implicit-Explicit Depth Fusion and Contextual Self-Supervision
May 17, 2024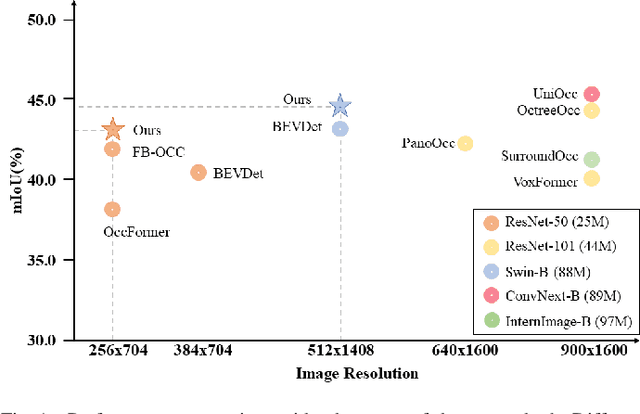



3D occupancy perception holds a pivotal role in recent vision-centric autonomous driving systems by converting surround-view images into integrated geometric and semantic representations within dense 3D grids. Nevertheless, current models still encounter two main challenges: modeling depth accurately in the 2D-3D view transformation stage, and overcoming the lack of generalizability issues due to sparse LiDAR supervision. To address these issues, this paper presents GEOcc, a Geometric-Enhanced Occupancy network tailored for vision-only surround-view perception. Our approach is three-fold: 1) Integration of explicit lift-based depth prediction and implicit projection-based transformers for depth modeling, enhancing the density and robustness of view transformation. 2) Utilization of mask-based encoder-decoder architecture for fine-grained semantic predictions; 3) Adoption of context-aware self-training loss functions in the pertaining stage to complement LiDAR supervision, involving the re-rendering of 2D depth maps from 3D occupancy features and leveraging image reconstruction loss to obtain denser depth supervision besides sparse LiDAR ground-truths. Our approach achieves State-Of-The-Art performance on the Occ3D-nuScenes dataset with the least image resolution needed and the most weightless image backbone compared with current models, marking an improvement of 3.3% due to our proposed contributions. Comprehensive experimentation also demonstrates the consistent superiority of our method over baselines and alternative approaches.
Spatial-Temporal Parallel Transformer for Arm-Hand Dynamic Estimation
Mar 30, 2022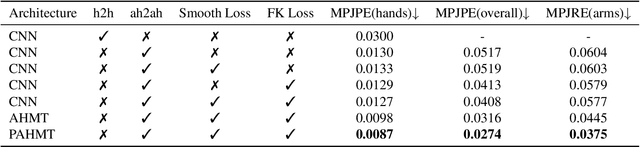
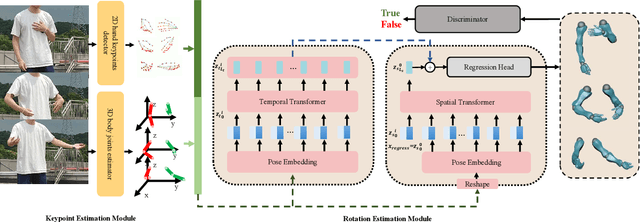

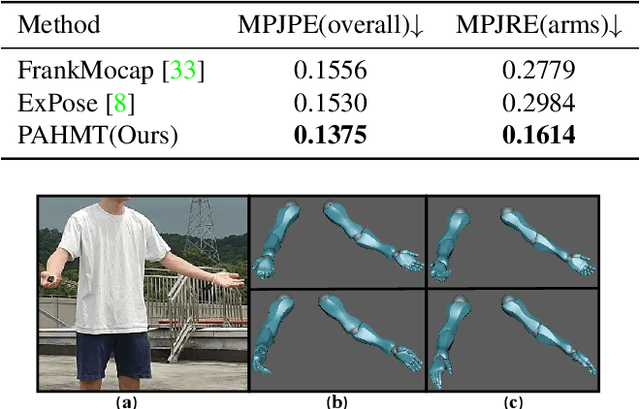
We propose an approach to estimate arm and hand dynamics from monocular video by utilizing the relationship between arm and hand. Although monocular full human motion capture technologies have made great progress in recent years, recovering accurate and plausible arm twists and hand gestures from in-the-wild videos still remains a challenge. To solve this problem, our solution is proposed based on the fact that arm poses and hand gestures are highly correlated in most real situations. To fully exploit arm-hand correlation as well as inter-frame information, we carefully design a Spatial-Temporal Parallel Arm-Hand Motion Transformer (PAHMT) to predict the arm and hand dynamics simultaneously. We also introduce new losses to encourage the estimations to be smooth and accurate. Besides, we collect a motion capture dataset including 200K frames of hand gestures and use this data to train our model. By integrating a 2D hand pose estimation model and a 3D human pose estimation model, the proposed method can produce plausible arm and hand dynamics from monocular video. Extensive evaluations demonstrate that the proposed method has advantages over previous state-of-the-art approaches and shows robustness under various challenging scenarios.