 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement-Guided Synthetic Data Generation for Privacy-Sensitive Identity Recognition
Apr 09, 2026High-fidelity generative models are increasingly needed in privacy-sensitive scenarios, where access to data is severely restricted due to regulatory and copyright constraints. This scarcity hampers model development--ironically, in settings where generative models are most needed to compensate for the lack of data. This creates a self-reinforcing challenge: limited data leads to poor generative models, which in turn fail to mitigate data scarcity. To break this cycle, we propose a reinforcement-guided synthetic data generation framework that adapts general-domain generative priors to privacy-sensitive identity recognition tasks. We first perform a cold-start adaptation to align a pretrained generator with the target domain, establishing semantic relevance and initial fidelity. Building on this foundation, we introduce a multi-objective reward that jointly optimizes semantic consistency, coverage diversity, and expression richness, guiding the generator to produce both realistic and task-effective samples. During downstream training, a dynamic sample selection mechanism further prioritizes high-utility synthetic samples, enabling adaptive data scaling and improved domain alignment. Extensive experiments on benchmark datasets demonstrate that our framework significantly improves both generation fidelity and classification accuracy, while also exhibiting strong generalization to novel categories in small-data regimes.
See What You Seek: Semantic Contextual Integration for Cloth-Changing Person Re-Identification
Dec 02, 2024



Cloth-changing person re-identification (CC-ReID) aims to match individuals across multiple surveillance cameras despite variations in clothing. Existing methods typically focus on mitigating the effects of clothing changes or enhancing ID-relevant features but often struggle to capture complex semantic information. In this paper, we propose a novel prompt learning framework, Semantic Contextual Integration (SCI), for CC-ReID, which leverages the visual-text representation capabilities of CLIP to minimize the impact of clothing changes and enhance ID-relevant features. Specifically, we introduce Semantic Separation Enhancement (SSE) module, which uses dual learnable text tokens to separately capture confounding and clothing-related semantic information, effectively isolating ID-relevant features from distracting clothing semantics. Additionally, we develop a Semantic-Guided Interaction Module (SIM) that uses orthogonalized text features to guide visual representations, sharpening the model's focus on distinctive ID characteristics. This integration enhances the model's discriminative power and enriches the visual context with high-dimensional semantic insights. Extensive experiments on three CC-ReID datasets demonstrate that our method outperforms state-of-the-art techniques. The code will be released at github.
OccludeNet: A Causal Journey into Mixed-View Actor-Centric Video Action Recognition under Occlusions
Nov 24, 2024The lack of occlusion data in commonly used action recognition video datasets limits model robustness and impedes sustained performance improvements. We construct OccludeNet, a large-scale occluded video dataset that includes both real-world and synthetic occlusion scene videos under various natural environments. OccludeNet features dynamic tracking occlusion, static scene occlusion, and multi-view interactive occlusion, addressing existing gaps in data. Our analysis reveals that occlusion impacts action classes differently, with actions involving low scene relevance and partial body visibility experiencing greater accuracy degradation. To overcome the limitations of current occlusion-focused approaches, we propose a structural causal model for occluded scenes and introduce the Causal Action Recognition (CAR) framework, which employs backdoor adjustment and counterfactual reasoning. This framework enhances key actor information, improving model robustness to occlusion. We anticipate that the challenges posed by OccludeNet will stimulate further exploration of causal relations in occlusion scenarios and encourage a reevaluation of class correlations, ultimately promoting sustainable performance improvements. The code and full dataset will be released soon.
Dynamic Association Learning of Self-Attention and Convolution in Image Restoration
Nov 09, 2023CNNs and Self attention have achieved great success in multimedia applications for dynamic association learning of self-attention and convolution in image restoration. However, CNNs have at least two shortcomings: 1) limited receptive field; 2) static weight of sliding window at inference, unable to cope with the content diversity.In view of the advantages and disadvantages of CNNs and Self attention, this paper proposes an association learning method to utilize the advantages and suppress their shortcomings, so as to achieve high-quality and efficient inpainting. We regard rain distribution reflects the degradation location and degree, in addition to the rain distribution prediction. Thus, we propose to refine background textures with the predicted degradation prior in an association learning manner. As a result, we accomplish image deraining by associating rain streak removal and background recovery, where an image deraining network and a background recovery network are designed for two subtasks. The key part of association learning is a novel multi-input attention module. It generates the degradation prior and produces the degradation mask according to the predicted rainy distribution. Benefited from the global correlation calculation of SA, MAM can extract the informative complementary components from the rainy input with the degradation mask, and then help accurate texture restoration. Meanwhile, SA tends to aggregate feature maps with self-attention importance, but convolution diversifies them to focus on the local textures. A hybrid fusion network involves one residual Transformer branch and one encoder-decoder branch. The former takes a few learnable tokens as input and stacks multi-head attention and feed-forward networks to encode global features of the image. The latter, conversely, leverages the multi-scale encoder-decoder to represent contexture knowledge.
HOTCOLD Block: Fooling Thermal Infrared Detectors with a Novel Wearable Design
Dec 12, 2022



Adversarial attacks on thermal infrared imaging expose the risk of related applications. Estimating the security of these systems is essential for safely deploying them in the real world. In many cases, realizing the attacks in the physical space requires elaborate special perturbations. These solutions are often \emph{impractical} and \emph{attention-grabbing}. To address the need for a physically practical and stealthy adversarial attack, we introduce \textsc{HotCold} Block, a novel physical attack for infrared detectors that hide persons utilizing the wearable Warming Paste and Cooling Paste. By attaching these readily available temperature-controlled materials to the body, \textsc{HotCold} Block evades human eyes efficiently. Moreover, unlike existing methods that build adversarial patches with complex texture and structure features, \textsc{HotCold} Block utilizes an SSP-oriented adversarial optimization algorithm that enables attacks with pure color blocks and explores the influence of size, shape, and position on attack performance. Extensive experimental results in both digital and physical environments demonstrate the performance of our proposed \textsc{HotCold} Block. \emph{Code is available: \textcolor{magenta}{https://github.com/weihui1308/HOTCOLDBlock}}.
Physical Adversarial Attack meets Computer Vision: A Decade Survey
Sep 30, 2022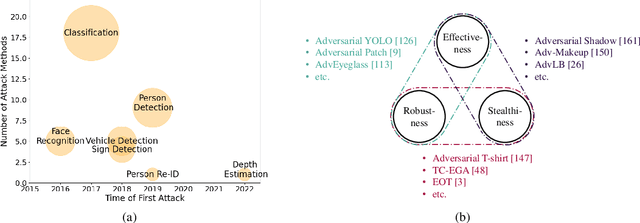
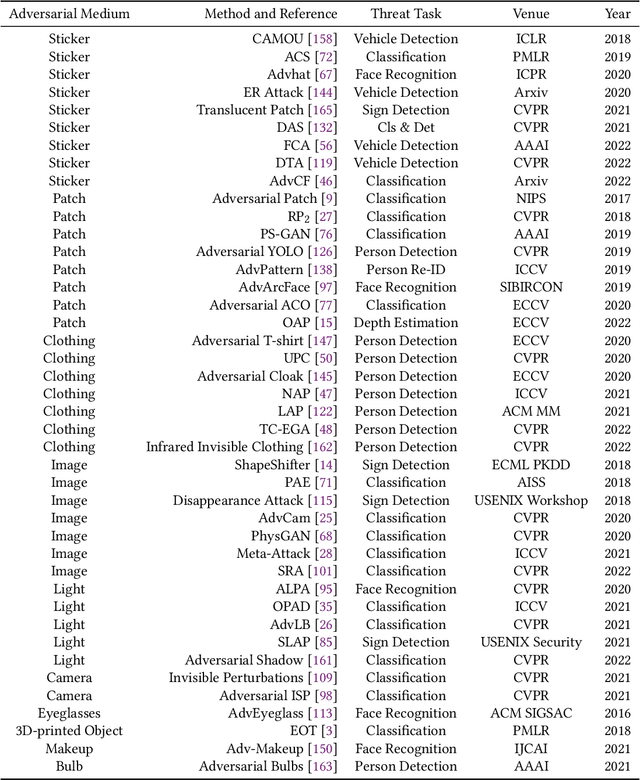

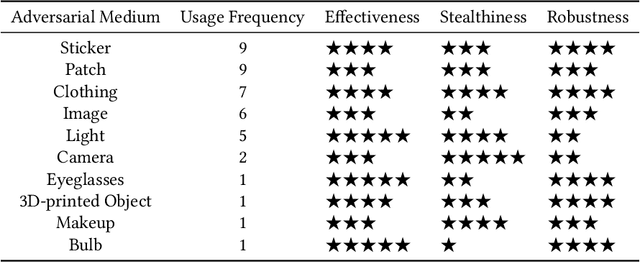
Although Deep Neural Networks (DNNs) have achieved impressive results in computer vision, their exposed vulnerability to adversarial attacks remains a serious concern. A series of works has shown that by adding elaborate perturbations to images, DNNs could have catastrophic degradation in performance metrics. And this phenomenon does not only exist in the digital space but also in the physical space. Therefore, estimating the security of these DNNs-based systems is critical for safely deploying them in the real world, especially for security-critical applications, e.g., autonomous cars, video surveillance, and medical diagnosis. In this paper, we focus on physical adversarial attacks and provide a comprehensive survey of over 150 existing papers. We first clarify the concept of the physical adversarial attack and analyze its characteristics. Then, we define the adversarial medium, essential to perform attacks in the physical world. Next, we present the physical adversarial attack methods in task order: classification, detection, and re-identification, and introduce their performance in solving the trilemma: effectiveness, stealthiness, and robustness. In the end, we discuss the current challenges and potential future directions.