 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Horizon: Decoupling UAVs Multi-View Action Recognition via Partial Order Transfer
Apr 29, 2025Action recognition in unmanned aerial vehicles (UAVs) poses unique challenges due to significant view variations along the vertical spatial axis. Unlike traditional ground-based settings, UAVs capture actions from a wide range of altitudes, resulting in considerable appearance discrepancies. We introduce a multi-view formulation tailored to varying UAV altitudes and empirically observe a partial order among views, where recognition accuracy consistently decreases as the altitude increases. This motivates a novel approach that explicitly models the hierarchical structure of UAV views to improve recognition performance across altitudes. To this end, we propose the Partial Order Guided Multi-View Network (POG-MVNet), designed to address drastic view variations by effectively leveraging view-dependent information across different altitude levels. The framework comprises three key components: a View Partition (VP) module, which uses the head-to-body ratio to group views by altitude; an Order-aware Feature Decoupling (OFD) module, which disentangles action-relevant and view-specific features under partial order guidance; and an Action Partial Order Guide (APOG), which leverages the partial order to transfer informative knowledge from easier views to support learning in more challenging ones. We conduct experiments on Drone-Action, MOD20, and UAV datasets, demonstrating that POG-MVNet significantly outperforms competing methods. For example, POG-MVNet achieves a 4.7% improvement on Drone-Action dataset and a 3.5% improvement on UAV dataset compared to state-of-the-art methods ASAT and FAR. The code for POG-MVNet will be made available soon.
See What You Seek: Semantic Contextual Integration for Cloth-Changing Person Re-Identification
Dec 02, 2024



Cloth-changing person re-identification (CC-ReID) aims to match individuals across multiple surveillance cameras despite variations in clothing. Existing methods typically focus on mitigating the effects of clothing changes or enhancing ID-relevant features but often struggle to capture complex semantic information. In this paper, we propose a novel prompt learning framework, Semantic Contextual Integration (SCI), for CC-ReID, which leverages the visual-text representation capabilities of CLIP to minimize the impact of clothing changes and enhance ID-relevant features. Specifically, we introduce Semantic Separation Enhancement (SSE) module, which uses dual learnable text tokens to separately capture confounding and clothing-related semantic information, effectively isolating ID-relevant features from distracting clothing semantics. Additionally, we develop a Semantic-Guided Interaction Module (SIM) that uses orthogonalized text features to guide visual representations, sharpening the model's focus on distinctive ID characteristics. This integration enhances the model's discriminative power and enriches the visual context with high-dimensional semantic insights. Extensive experiments on three CC-ReID datasets demonstrate that our method outperforms state-of-the-art techniques. The code will be released at github.
Learning Meta Pattern for Face Anti-Spoofing
Oct 13, 2021



Face Anti-Spoofing (FAS) is essential to secure face recognition systems and has been extensively studied in recent years. Although deep neural networks (DNNs) for the FAS task have achieved promising results in intra-dataset experiments with similar distributions of training and testing data, the DNNs' generalization ability is limited under the cross-domain scenarios with different distributions of training and testing data. To improve the generalization ability, recent hybrid methods have been explored to extract task-aware handcrafted features (e.g., Local Binary Pattern) as discriminative information for the input of DNNs. However, the handcrafted feature extraction relies on experts' domain knowledge, and how to choose appropriate handcrafted features is underexplored. To this end, we propose a learnable network to extract Meta Pattern (MP) in our learning-to-learn framework. By replacing handcrafted features with the MP, the discriminative information from MP is capable of learning a more generalized model. Moreover, we devise a two-stream network to hierarchically fuse the input RGB image and the extracted MP by using our proposed Hierarchical Fusion Module (HFM). We conduct comprehensive experiments and show that our MP outperforms the compared handcrafted features. Also, our proposed method with HFM and the MP can achieve state-of-the-art performance on two different domain generalization evaluation benchmarks.
DRL-FAS: A Novel Framework Based on Deep Reinforcement Learning for Face Anti-Spoofing
Sep 18, 2020
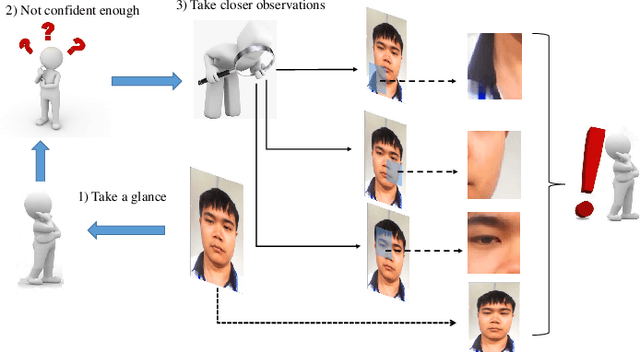
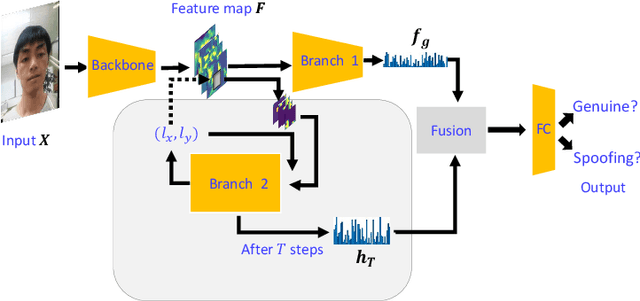
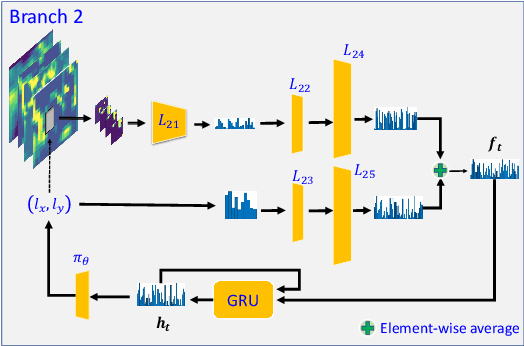
Inspired by the philosophy employed by human beings to determine whether a presented face example is genuine or not, i.e., to glance at the example globally first and then carefully observe the local regions to gain more discriminative information, for the face anti-spoofing problem, we propose a novel framework based on the Convolutional Neural Network (CNN) and the Recurrent Neural Network (RNN). In particular, we model the behavior of exploring face-spoofing-related information from image sub-patches by leveraging deep reinforcement learning. We further introduce a recurrent mechanism to learn representations of local information sequentially from the explored sub-patches with an RNN. Finally, for the classification purpose, we fuse the local information with the global one, which can be learned from the original input image through a CNN. Moreover, we conduct extensive experiments, including ablation study and visualization analysis, to evaluate our proposed framework on various public databases. The experiment results show that our method can generally achieve state-of-the-art performance among all scenarios, demonstrating its effectiveness.
Multi-task Mid-level Feature Alignment Network for Unsupervised Cross-Dataset Person Re-Identification
Jul 11, 2018
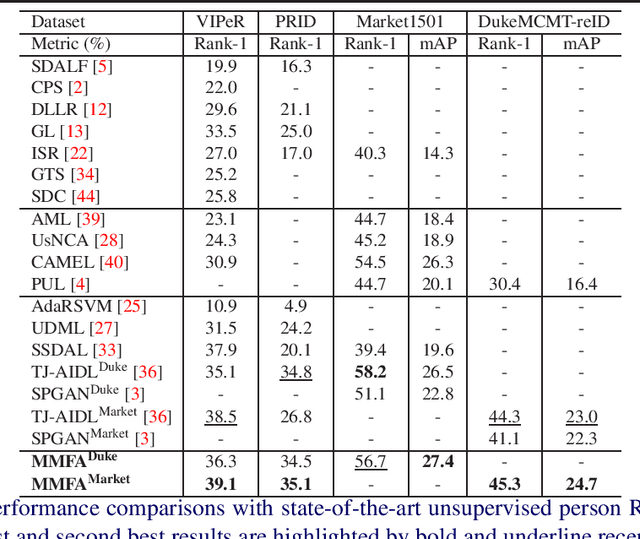
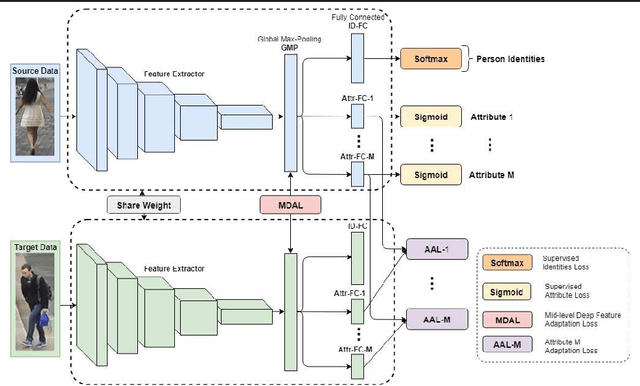

Most existing person re-identification (Re-ID) approaches follow a supervised learning framework, in which a large number of labelled matching pairs are required for training. Such a setting severely limits their scalability in real-world applications where no labelled samples are available during the training phase. To overcome this limitation, we develop a novel unsupervised Multi-task Mid-level Feature Alignment (MMFA) network for the unsupervised cross-dataset person re-identification task. Under the assumption that the source and target datasets share the same set of mid-level semantic attributes, our proposed model can be jointly optimised under the person's identity classification and the attribute learning task with a cross-dataset mid-level feature alignment regularisation term. In this way, the learned feature representation can be better generalised from one dataset to another which further improve the person re-identification accuracy. Experimental results on four benchmark datasets demonstrate that our proposed method outperforms the state-of-the-art baselines.
Compact Descriptors for Video Analysis: the Emerging MPEG Standard
Apr 26, 2017
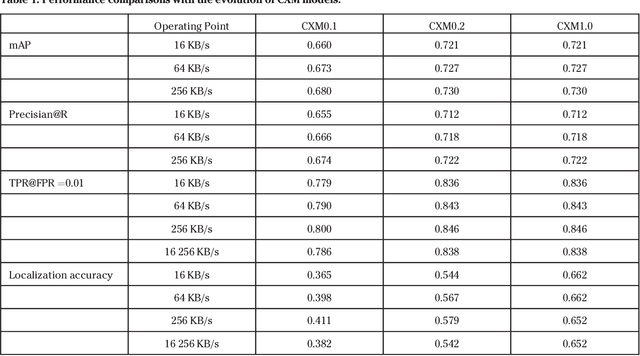
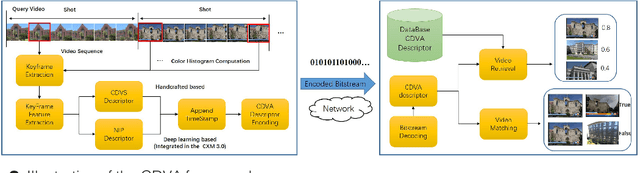
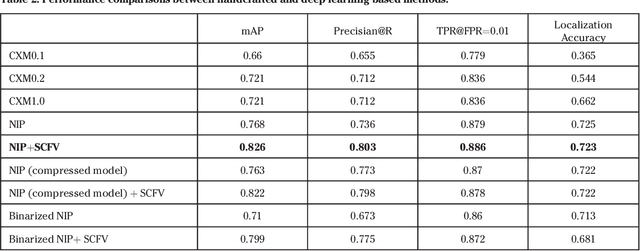
This paper provides an overview of the on-going compact descriptors for video analysis standard (CDVA) from the ISO/IEC moving pictures experts group (MPEG). MPEG-CDVA targets at defining a standardized bitstream syntax to enable interoperability in the context of video analysis applications. During the developments of MPEGCDVA, a series of techniques aiming to reduce the descriptor size and improve the video representation ability have been proposed. This article describes the new standard that is being developed and reports the performance of these key technical contributions.