 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-aware Image Deblurring
Paper and Code
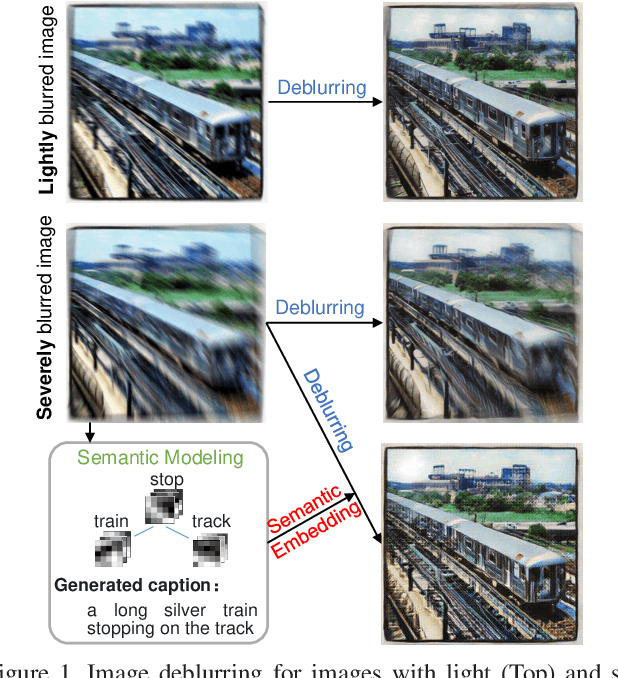

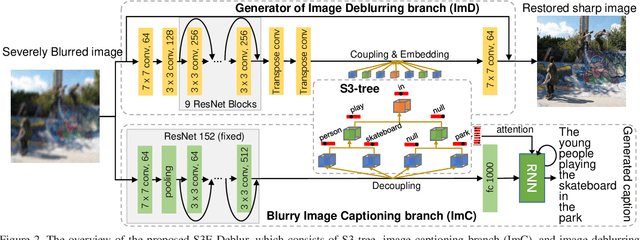

Image deblurring has achieved exciting progress in recent years. However, traditional methods fail to deblur severely blurred images, where semantic contents appears ambiguously. In this paper, we conduct image deblurring guided by the semantic contents inferred from image captioning. Specially, we propose a novel Structured-Spatial Semantic Embedding model for image deblurring (termed S3E-Deblur), which introduces a novel Structured-Spatial Semantic tree model (S3-tree) to bridge two basic tasks in computer vision: image deblurring (ImD) and image captioning (ImC). In particular, S3-tree captures and represents the semantic contents in structured spatial features in ImC, and then embeds the spatial features of the tree nodes into GAN based ImD. Co-training on S3-tree, ImC, and ImD is conducted to optimize the overall model in a multi-task end-to-end manner. Extensive experiments on severely blurred MSCOCO and GoPro datasets demonstrate the significant superiority of S3E-Deblur compared to the state-of-the-arts on both ImD and ImC tasks.