 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Graph-Guided Generative AI Framework for Synthesizing and Evaluating Industrial Hazard Scenarios
Nov 17, 2025

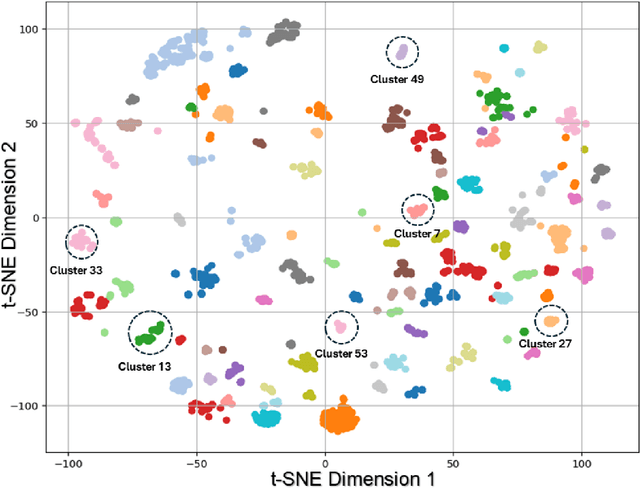

Training vision models to detect workplace hazards accurately requires realistic images of unsafe conditions that could lead to accidents. However, acquiring such datasets is difficult because capturing accident-triggering scenarios as they occur is nearly impossible. To overcome this limitation, this study presents a novel scene graph-guided generative AI framework that synthesizes photorealistic images of hazardous scenarios grounded in historical Occupational Safety and Health Administration (OSHA) accident reports. OSHA narratives are analyzed using GPT-4o to extract structured hazard reasoning, which is converted into object-level scene graphs capturing spatial and contextual relationships essential for understanding risk. These graphs guide a text-to-image diffusion model to generate compositionally accurate hazard scenes. To evaluate the realism and semantic fidelity of the generated data, a visual question answering (VQA) framework is introduced. Across four state-of-the-art generative models, the proposed VQA Graph Score outperforms CLIP and BLIP metrics based on entropy-based validation, confirming its higher discriminative sensitivity.
Risks, Causes, and Mitigations of Widespread Deployments of Large Language Models (LLMs): A Survey
Aug 01, 2024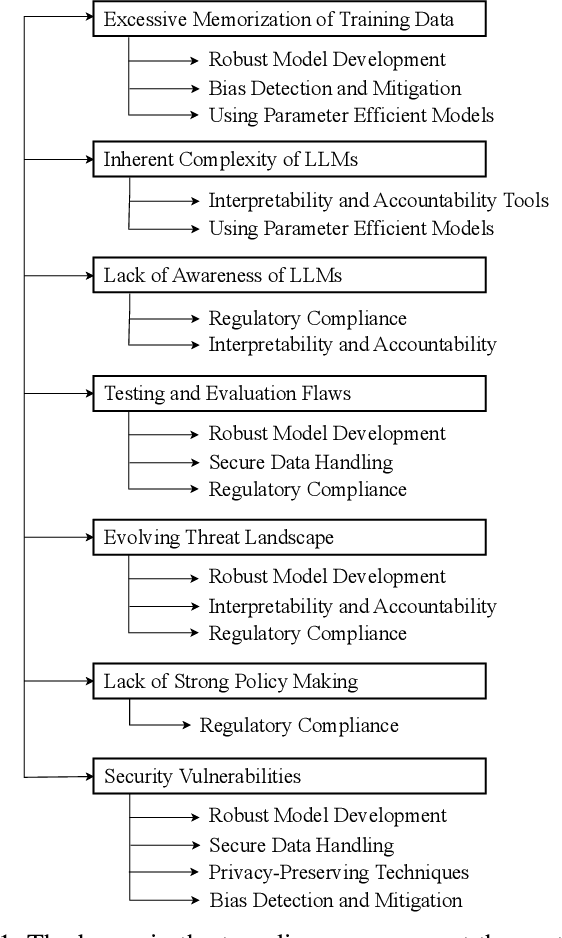
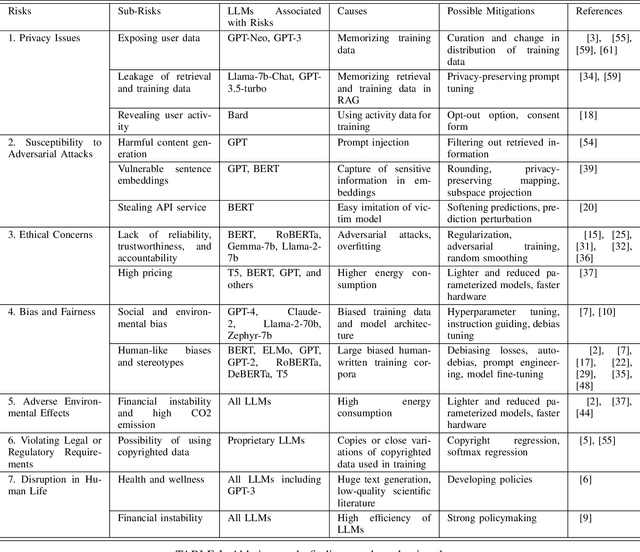
Recent advancements in Large Language Models (LLMs), such as ChatGPT and LLaMA, have significantly transformed Natural Language Processing (NLP) with their outstanding abilities in text generation, summarization, and classification. Nevertheless, their widespread adoption introduces numerous challenges, including issues related to academic integrity, copyright, environmental impacts, and ethical considerations such as data bias, fairness, and privacy. The rapid evolution of LLMs also raises concerns regarding the reliability and generalizability of their evaluations. This paper offers a comprehensive survey of the literature on these subjects, systematically gathered and synthesized from Google Scholar. Our study provides an in-depth analysis of the risks associated with specific LLMs, identifying sub-risks, their causes, and potential solutions. Furthermore, we explore the broader challenges related to LLMs, detailing their causes and proposing mitigation strategies. Through this literature analysis, our survey aims to deepen the understanding of the implications and complexities surrounding these powerful models.
Automatic Pull Request Description Generation Using LLMs: A T5 Model Approach
Aug 01, 2024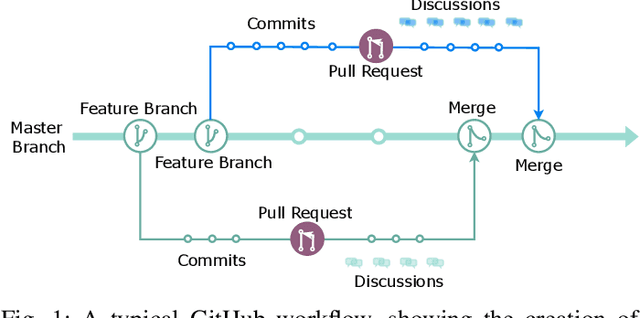
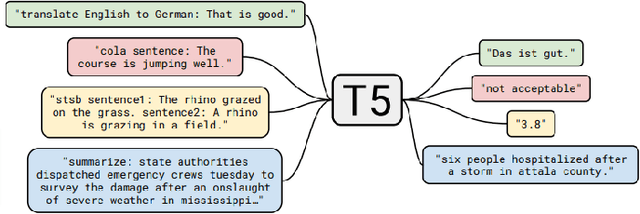
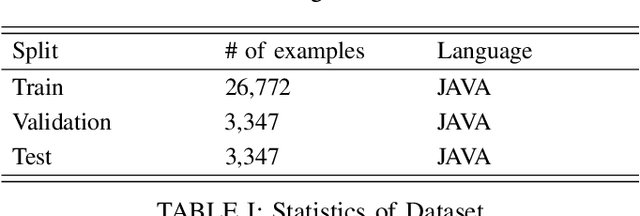
Developers create pull request (PR) descriptions to provide an overview of their changes and explain the motivations behind them. These descriptions help reviewers and fellow developers quickly understand the updates. Despite their importance, some developers omit these descriptions. To tackle this problem, we propose an automated method for generating PR descriptions based on commit messages and source code comments. This method frames the task as a text summarization problem, for which we utilized the T5 text-to-text transfer model. We fine-tuned a pre-trained T5 model using a dataset containing 33,466 PRs. The model's effectiveness was assessed using ROUGE metrics, which are recognized for their strong alignment with human evaluations. Our findings reveal that the T5 model significantly outperforms LexRank, which served as our baseline for comparison.
Explainable, Interpretable & Trustworthy AI for Intelligent Digital Twin: Case Study on Remaining Useful Life
Jan 17, 2023Machine learning (ML) and Artificial Intelligence (AI) are increasingly used in energy and engineering systems, but these models must be fair, unbiased, and explainable. It is critical to have confidence in AI's trustworthiness. ML techniques have been useful in predicting important parameters and improving model performance. However, for these AI techniques to be useful for making decisions, they need to be audited, accounted for, and easy to understand. Therefore, the use of Explainable AI (XAI) and interpretable machine learning (IML) is crucial for the accurate prediction of prognostics, such as remaining useful life (RUL) in a digital twin system to make it intelligent while ensuring that the AI model is transparent in its decision-making processes and that the predictions it generates can be understood and trusted by users. By using AI that is explainable, interpretable, and trustworthy, intelligent digital twin systems can make more accurate predictions of RUL, leading to better maintenance and repair planning and, ultimately, improved system performance. The objective of this paper is to understand the idea of XAI and IML and justify the important role of ML/AI in the Digital Twin framework and components, which requires XAI to understand the prediction better. This paper explains the importance of XAI and IML in both local and global aspects to ensure the use of trustworthy ML/AI applications for RUL prediction. This paper used the RUL prediction for the XAI and IML studies and leveraged the integrated python toolbox for interpretable machine learning (PiML).