 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisks, Causes, and Mitigations of Widespread Deployments of Large Language Models (LLMs): A Survey
Paper and Code
Aug 01, 2024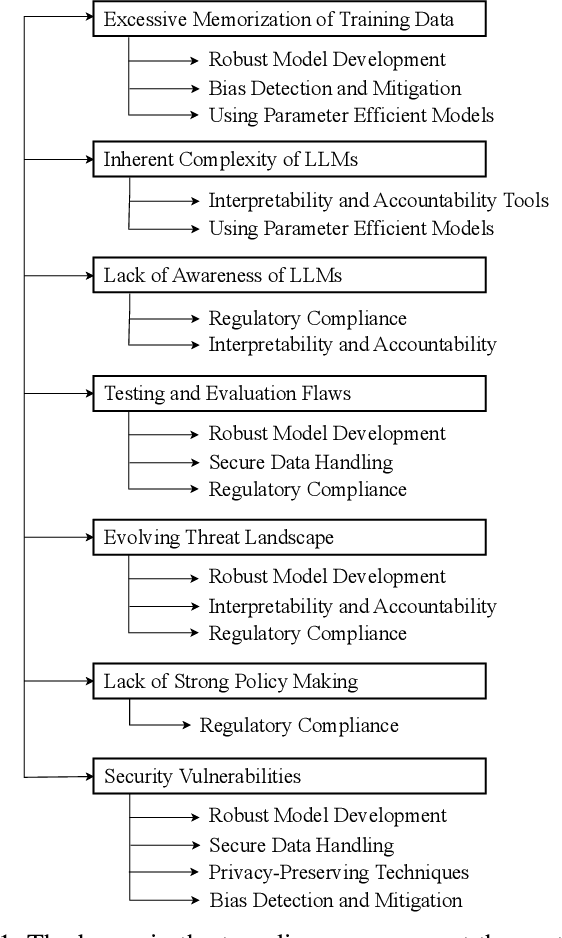
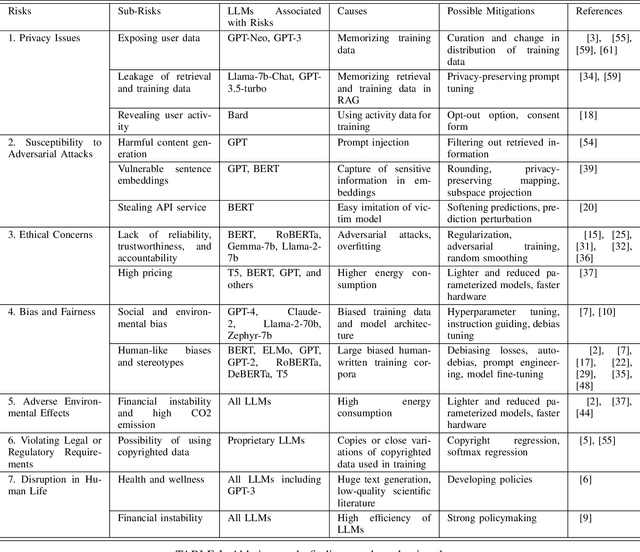
Recent advancements in Large Language Models (LLMs), such as ChatGPT and LLaMA, have significantly transformed Natural Language Processing (NLP) with their outstanding abilities in text generation, summarization, and classification. Nevertheless, their widespread adoption introduces numerous challenges, including issues related to academic integrity, copyright, environmental impacts, and ethical considerations such as data bias, fairness, and privacy. The rapid evolution of LLMs also raises concerns regarding the reliability and generalizability of their evaluations. This paper offers a comprehensive survey of the literature on these subjects, systematically gathered and synthesized from Google Scholar. Our study provides an in-depth analysis of the risks associated with specific LLMs, identifying sub-risks, their causes, and potential solutions. Furthermore, we explore the broader challenges related to LLMs, detailing their causes and proposing mitigation strategies. Through this literature analysis, our survey aims to deepen the understanding of the implications and complexities surrounding these powerful models.