 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Interference Exist When Training a Once-For-All Network?
Paper and Code
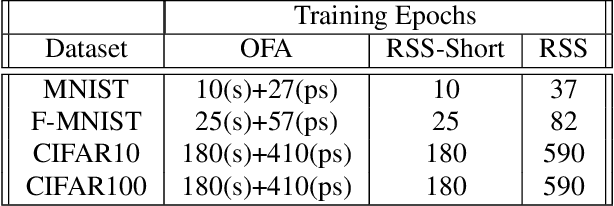
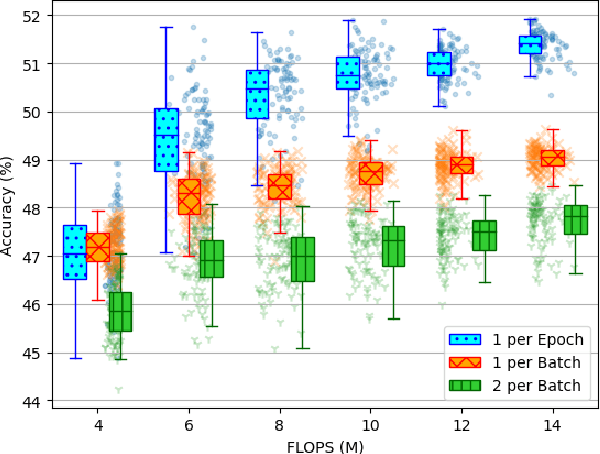

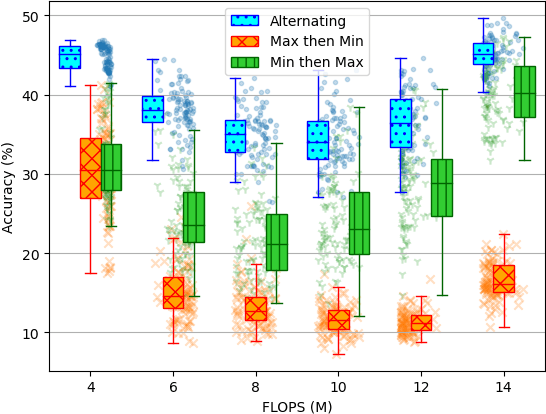
The Once-For-All (OFA) method offers an excellent pathway to deploy a trained neural network model into multiple target platforms by utilising the supernet-subnet architecture. Once trained, a subnet can be derived from the supernet (both architecture and trained weights) and deployed directly to the target platform with little to no retraining or fine-tuning. To train the subnet population, OFA uses a novel training method called Progressive Shrinking (PS) which is designed to limit the negative impact of interference during training. It is believed that higher interference during training results in lower subnet population accuracies. In this work we take a second look at this interference effect. Surprisingly, we find that interference mitigation strategies do not have a large impact on the overall subnet population performance. Instead, we find the subnet architecture selection bias during training to be a more important aspect. To show this, we propose a simple-yet-effective method called Random Subnet Sampling (RSS), which does not have mitigation on the interference effect. Despite no mitigation, RSS is able to produce a better performing subnet population than PS in four small-to-medium-sized datasets; suggesting that the interference effect does not play a pivotal role in these datasets. Due to its simplicity, RSS provides a $1.9\times$ reduction in training times compared to PS. A $6.1\times$ reduction can also be achieved with a reasonable drop in performance when the number of RSS training epochs are reduced. Code available at https://github.com/Jordan-HS/RSS-Interference-CVPRW2022.