 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniGCD: Abstracting Generalized Category Discovery for Modality Agnosticism
Apr 16, 2026Generalized Category Discovery (GCD) challenges methods to identify known and novel classes using partially labeled data, mirroring human category learning. Unlike prior GCD methods, which operate within a single modality and require dataset-specific fine-tuning, we propose a modality-agnostic GCD approach inspired by the human brain's abstract category formation. Our $\textbf{OmniGCD}$ leverages modality-specific encoders (e.g., vision, audio, text, remote sensing) to process inputs, followed by dimension reduction to construct a $\textbf{GCD latent space}$, which is transformed at test-time into a representation better suited for clustering using a novel synthetically trained Transformer-based model. To evaluate OmniGCD, we introduce a $\textbf{zero-shot GCD setting}$ where no dataset-specific fine-tuning is allowed, enabling modality-agnostic category discovery. $\textbf{Trained once on synthetic data}$, OmniGCD performs zero-shot GCD across 16 datasets spanning four modalities, improving classification accuracy for known and novel classes over baselines (average percentage point improvement of $\textbf{+6.2}$, $\textbf{+17.9}$, $\textbf{+1.5}$ and $\textbf{+12.7}$ for vision, text, audio and remote sensing). This highlights the importance of strong encoders while decoupling representation learning from category discovery. Improving modality-agnostic methods will propagate across modalities, enabling encoder development independent of GCD. Our work serves as a benchmark for future modality-agnostic GCD works, paving the way for scalable, human-inspired category discovery. All code is available $\href{https://github.com/Jordan-HS/OmniGCD}{here}$
Zoom-shot: Fast and Efficient Unsupervised Zero-Shot Transfer of CLIP to Vision Encoders with Multimodal Loss
Jan 22, 2024The fusion of vision and language has brought about a transformative shift in computer vision through the emergence of Vision-Language Models (VLMs). However, the resource-intensive nature of existing VLMs poses a significant challenge. We need an accessible method for developing the next generation of VLMs. To address this issue, we propose Zoom-shot, a novel method for transferring the zero-shot capabilities of CLIP to any pre-trained vision encoder. We do this by exploiting the multimodal information (i.e. text and image) present in the CLIP latent space through the use of specifically designed multimodal loss functions. These loss functions are (1) cycle-consistency loss and (2) our novel prompt-guided knowledge distillation loss (PG-KD). PG-KD combines the concept of knowledge distillation with CLIP's zero-shot classification, to capture the interactions between text and image features. With our multimodal losses, we train a $\textbf{linear mapping}$ between the CLIP latent space and the latent space of a pre-trained vision encoder, for only a $\textbf{single epoch}$. Furthermore, Zoom-shot is entirely unsupervised and is trained using $\textbf{unpaired}$ data. We test the zero-shot capabilities of a range of vision encoders augmented as new VLMs, on coarse and fine-grained classification datasets, outperforming the previous state-of-the-art in this problem domain. In our ablations, we find Zoom-shot allows for a trade-off between data and compute during training; and our state-of-the-art results can be obtained by reducing training from 20% to 1% of the ImageNet training data with 20 epochs. All code and models are available on GitHub.
SafeSea: Synthetic Data Generation for Adverse & Low Probability Maritime Conditions
Nov 24, 2023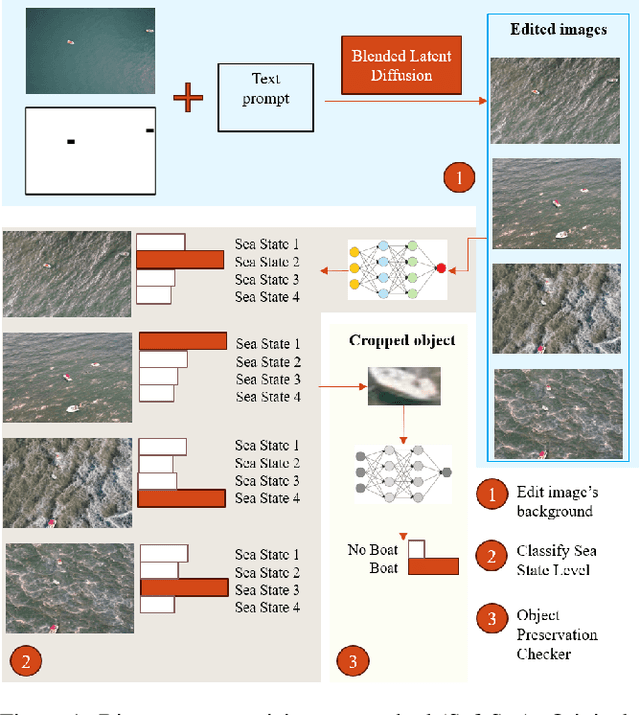



High-quality training data is essential for enhancing the robustness of object detection models. Within the maritime domain, obtaining a diverse real image dataset is particularly challenging due to the difficulty of capturing sea images with the presence of maritime objects , especially in stormy conditions. These challenges arise due to resource limitations, in addition to the unpredictable appearance of maritime objects. Nevertheless, acquiring data from stormy conditions is essential for training effective maritime detection models, particularly for search and rescue, where real-world conditions can be unpredictable. In this work, we introduce SafeSea, which is a stepping stone towards transforming actual sea images with various Sea State backgrounds while retaining maritime objects. Compared to existing generative methods such as Stable Diffusion Inpainting~\cite{stableDiffusion}, this approach reduces the time and effort required to create synthetic datasets for training maritime object detection models. The proposed method uses two automated filters to only pass generated images that meet the criteria. In particular, these filters will first classify the sea condition according to its Sea State level and then it will check whether the objects from the input image are still preserved. This method enabled the creation of the SafeSea dataset, offering diverse weather condition backgrounds to supplement the training of maritime models. Lastly, we observed that a maritime object detection model faced challenges in detecting objects in stormy sea backgrounds, emphasizing the impact of weather conditions on detection accuracy. The code, and dataset are available at https://github.com/martin-3240/SafeSea.
Boosting Zero-shot Classification with Synthetic Data Diversity via Stable Diffusion
Feb 08, 2023



Recent research has shown it is possible to perform zero-shot classification tasks by training a classifier with synthetic data generated by a diffusion model. However, the performance of this approach is still inferior to that of recent vision-language models. It has been suggested that the reason for this is a domain gap between the synthetic and real data. In our work, we show that this domain gap is not the main issue, and that diversity in the synthetic dataset is more important. We propose a $\textit{bag of tricks}$ to improve diversity and are able to achieve performance on par with one of the vision-language models, CLIP. More importantly, this insight allows us to endow zero-shot classification capabilities on any classification model.
Does Interference Exist When Training a Once-For-All Network?
Apr 20, 2022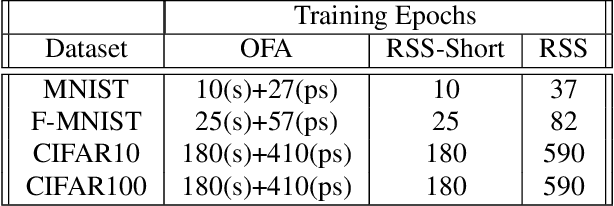
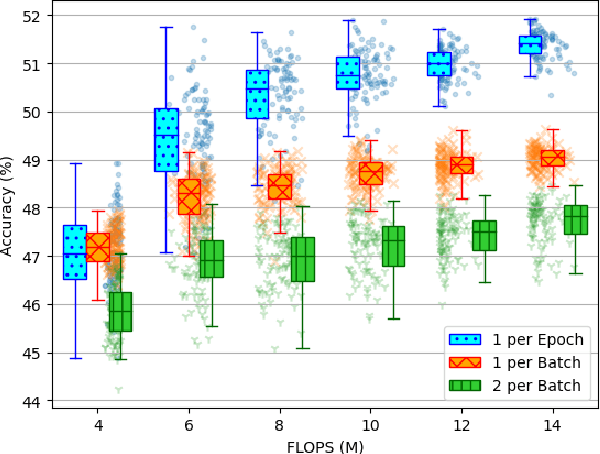

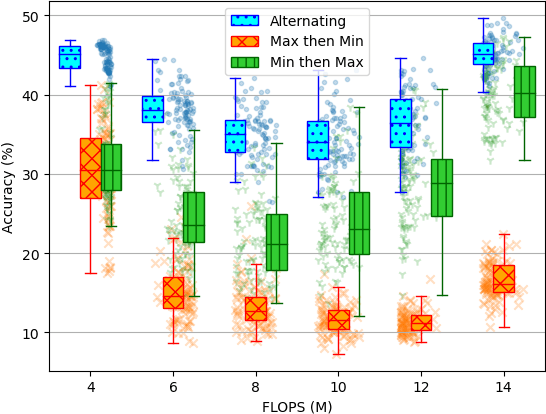
The Once-For-All (OFA) method offers an excellent pathway to deploy a trained neural network model into multiple target platforms by utilising the supernet-subnet architecture. Once trained, a subnet can be derived from the supernet (both architecture and trained weights) and deployed directly to the target platform with little to no retraining or fine-tuning. To train the subnet population, OFA uses a novel training method called Progressive Shrinking (PS) which is designed to limit the negative impact of interference during training. It is believed that higher interference during training results in lower subnet population accuracies. In this work we take a second look at this interference effect. Surprisingly, we find that interference mitigation strategies do not have a large impact on the overall subnet population performance. Instead, we find the subnet architecture selection bias during training to be a more important aspect. To show this, we propose a simple-yet-effective method called Random Subnet Sampling (RSS), which does not have mitigation on the interference effect. Despite no mitigation, RSS is able to produce a better performing subnet population than PS in four small-to-medium-sized datasets; suggesting that the interference effect does not play a pivotal role in these datasets. Due to its simplicity, RSS provides a $1.9\times$ reduction in training times compared to PS. A $6.1\times$ reduction can also be achieved with a reasonable drop in performance when the number of RSS training epochs are reduced. Code available at https://github.com/Jordan-HS/RSS-Interference-CVPRW2022.