 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Filtering via Variational Regularization for Robot Manipulation
Jan 29, 2026Diffusion-based visuomotor policies built on 3D visual representations have achieved strong performance in learning complex robotic skills. However, most existing methods employ an oversized denoising decoder. While increasing model capacity can improve denoising, empirical evidence suggests that it also introduces redundancy and noise in intermediate feature blocks. Crucially, we find that randomly masking backbone features at inference time (without changing training) can improve performance, confirming the presence of task-irrelevant noise in intermediate features. To this end, we propose Variational Regularization (VR), a lightweight module that imposes a timestep-conditioned Gaussian over backbone features and applies a KL-divergence regularizer, forming an adaptive information bottleneck. Extensive experiments on three simulation benchmarks (RoboTwin2.0, Adroit, and MetaWorld) show that, compared to the baseline DP3, our approach improves the success rate by 6.1% on RoboTwin2.0 and by 4.1% on Adroit and MetaWorld, achieving new state-of-the-art results. Real-world experiments further demonstrate that our method performs well in practical deployments. Code will released.
PocketDP3: Efficient Pocket-Scale 3D Visuomotor Policy
Jan 29, 2026Recently, 3D vision-based diffusion policies have shown strong capability in learning complex robotic manipulation skills. However, a common architectural mismatch exists in these models: a tiny yet efficient point-cloud encoder is often paired with a massive decoder. Given a compact scene representation, we argue that this may lead to substantial parameter waste in the decoder. Motivated by this observation, we propose PocketDP3, a pocket-scale 3D diffusion policy that replaces the heavy conditional U-Net decoder used in prior methods with a lightweight Diffusion Mixer (DiM) built on MLP-Mixer blocks. This architecture enables efficient fusion across temporal and channel dimensions, significantly reducing model size. Notably, without any additional consistency distillation techniques, our method supports two-step inference without sacrificing performance, improving practicality for real-time deployment. Across three simulation benchmarks--RoboTwin2.0, Adroit, and MetaWorld--PocketDP3 achieves state-of-the-art performance with fewer than 1% of the parameters of prior methods, while also accelerating inference. Real-world experiments further demonstrate the practicality and transferability of our method in real-world settings. Code will be released.
ISS Policy : Scalable Diffusion Policy with Implicit Scene Supervision
Dec 17, 2025Vision-based imitation learning has enabled impressive robotic manipulation skills, but its reliance on object appearance while ignoring the underlying 3D scene structure leads to low training efficiency and poor generalization. To address these challenges, we introduce \emph{Implicit Scene Supervision (ISS) Policy}, a 3D visuomotor DiT-based diffusion policy that predicts sequences of continuous actions from point cloud observations. We extend DiT with a novel implicit scene supervision module that encourages the model to produce outputs consistent with the scene's geometric evolution, thereby improving the performance and robustness of the policy. Notably, ISS Policy achieves state-of-the-art performance on both single-arm manipulation tasks (MetaWorld) and dexterous hand manipulation (Adroit). In real-world experiments, it also demonstrates strong generalization and robustness. Additional ablation studies show that our method scales effectively with both data and parameters. Code and videos will be released.
Agile in the Face of Delay: Asynchronous End-to-End Learning for Real-World Aerial Navigation
Sep 17, 2025
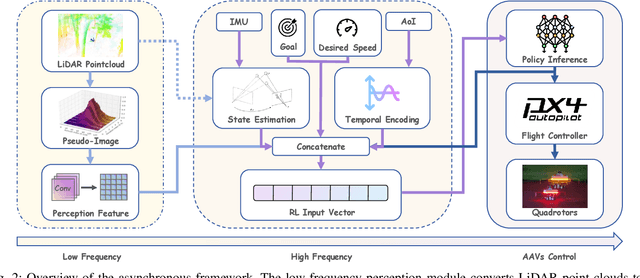
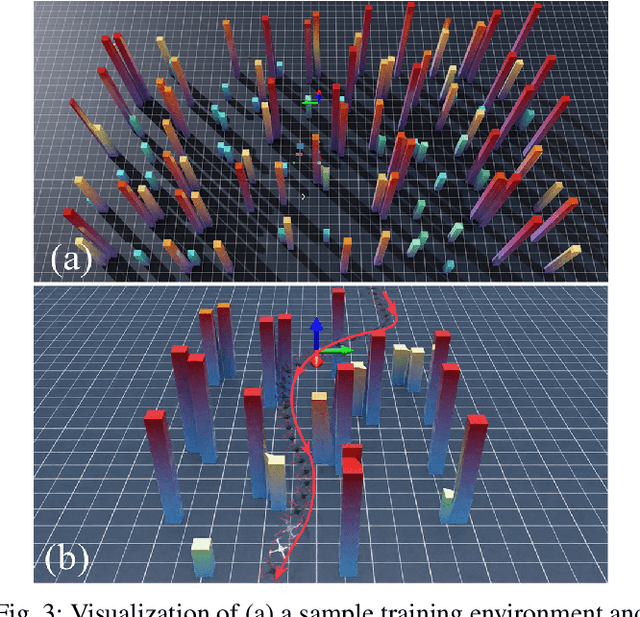
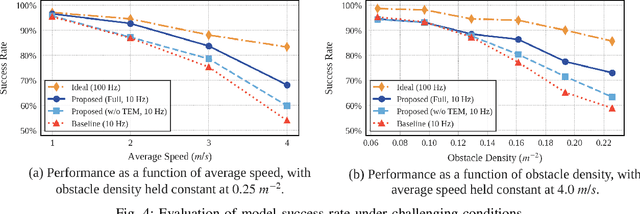
Robust autonomous navigation for Autonomous Aerial Vehicles (AAVs) in complex environments is a critical capability. However, modern end-to-end navigation faces a key challenge: the high-frequency control loop needed for agile flight conflicts with low-frequency perception streams, which are limited by sensor update rates and significant computational cost. This mismatch forces conventional synchronous models into undesirably low control rates. To resolve this, we propose an asynchronous reinforcement learning framework that decouples perception and control, enabling a high-frequency policy to act on the latest IMU state for immediate reactivity, while incorporating perception features asynchronously. To manage the resulting data staleness, we introduce a theoretically-grounded Temporal Encoding Module (TEM) that explicitly conditions the policy on perception delays, a strategy complemented by a two-stage curriculum to ensure stable and efficient training. Validated in extensive simulations, our method was successfully deployed in zero-shot sim-to-real transfer on an onboard NUC, where it sustains a 100~Hz control rate and demonstrates robust, agile navigation in cluttered real-world environments. Our source code will be released for community reference.
STORM: Spatial-Temporal Iterative Optimization for Reliable Multicopter Trajectory Generation
Mar 05, 2025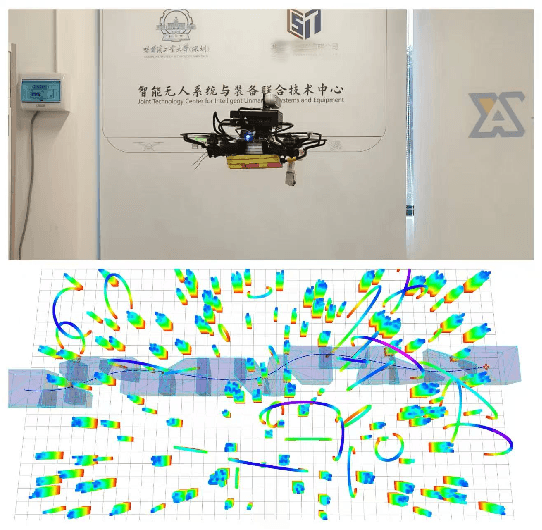
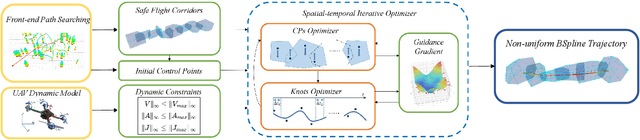
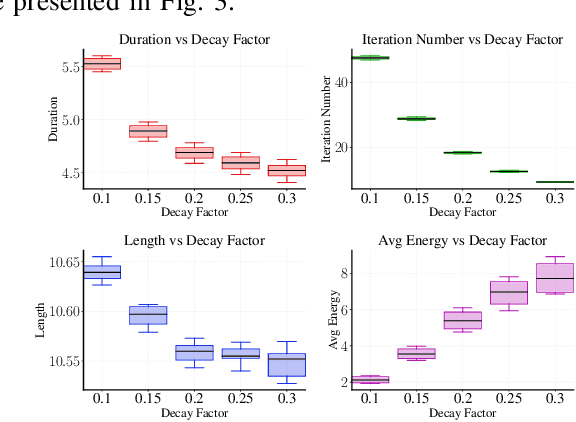
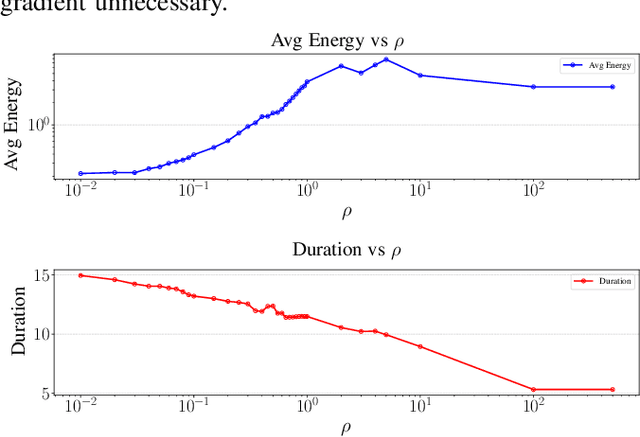
Efficient and safe trajectory planning plays a critical role in the application of quadrotor unmanned aerial vehicles. Currently, the inherent trade-off between constraint compliance and computational efficiency enhancement in UAV trajectory optimization problems has not been sufficiently addressed. To enhance the performance of UAV trajectory optimization, we propose a spatial-temporal iterative optimization framework. Firstly, B-splines are utilized to represent UAV trajectories, with rigorous safety assurance achieved through strict enforcement of constraints on control points. Subsequently, a set of QP-LP subproblems via spatial-temporal decoupling and constraint linearization is derived. Finally, an iterative optimization strategy incorporating guidance gradients is employed to obtain high-performance UAV trajectories in different scenarios. Both simulation and real-world experimental results validate the efficiency and high-performance of the proposed optimization framework in generating safe and fast trajectories. Our source codes will be released for community reference at https://hitsz-mas.github.io/STORM