 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoI-Driven Joint Optimization of Control and Communication in Vehicular Digital Twin Network
May 12, 2025The vision of sixth-generation (6G) wireless networks paves the way for the seamless integration of digital twins into vehicular networks, giving rise to a Vehicular Digital Twin Network (VDTN). The large amount of computing resources as well as the massive amount of spatial-temporal data in Digital Twin (DT) domain can be utilized to enhance the communication and control performance of Internet of Vehicle (IoV) systems. In this article, we first propose the architecture of VDTN, emphasizing key modules that center on functions related to the joint optimization of control and communication. We then delve into the intricacies of the multitimescale decision process inherent in joint optimization in VDTN, specifically investigating the dynamic interplay between control and communication. To facilitate the joint optimization, we define two Value of Information (VoI) concepts rooted in control performance. Subsequently, utilizing VoI as a bridge between control and communication, we introduce a novel joint optimization framework, which involves iterative processing of two Deep Reinforcement Learning (DRL) modules corresponding to control and communication to derive the optimal policy. Finally, we conduct simulations of the proposed framework applied to a platoon scenario to demonstrate its effectiveness in ensu
Learning Value of Information towards Joint Communication and Control in 6G V2X
May 11, 2025As Cellular Vehicle-to-Everything (C-V2X) evolves towards future sixth-generation (6G) networks, Connected Autonomous Vehicles (CAVs) are emerging to become a key application. Leveraging data-driven Machine Learning (ML), especially Deep Reinforcement Learning (DRL), is expected to significantly enhance CAV decision-making in both vehicle control and V2X communication under uncertainty. These two decision-making processes are closely intertwined, with the value of information (VoI) acting as a crucial bridge between them. In this paper, we introduce Sequential Stochastic Decision Process (SSDP) models to define and assess VoI, demonstrating their application in optimizing communication systems for CAVs. Specifically, we formally define the SSDP model and demonstrate that the MDP model is a special case of it. The SSDP model offers a key advantage by explicitly representing the set of information that can enhance decision-making when available. Furthermore, as current research on VoI remains fragmented, we propose a systematic VoI modeling framework grounded in the MDP, Reinforcement Learning (RL) and Optimal Control theories. We define different categories of VoI and discuss their corresponding estimation methods. Finally, we present a structured approach to leverage the various VoI metrics for optimizing the ``When", ``What", and ``How" to communicate problems. For this purpose, SSDP models are formulated with VoI-associated reward functions derived from VoI-based optimization objectives. While we use a simple vehicle-following control problem to illustrate the proposed methodology, it holds significant potential to facilitate the joint optimization of stochastic, sequential control and communication decisions in a wide range of networked control systems.
PLHF: Prompt Optimization with Few-Shot Human Feedback
May 11, 2025Automatic prompt optimization frameworks are developed to obtain suitable prompts for large language models (LLMs) with respect to desired output quality metrics. Although existing approaches can handle conventional tasks such as fixed-solution question answering, defining the metric becomes complicated when the output quality cannot be easily assessed by comparisons with standard golden samples. Consequently, optimizing the prompts effectively and efficiently without a clear metric becomes a critical challenge. To address the issue, we present PLHF (which stands for "P"rompt "L"earning with "H"uman "F"eedback), a few-shot prompt optimization framework inspired by the well-known RLHF technique. Different from naive strategies, PLHF employs a specific evaluator module acting as the metric to estimate the output quality. PLHF requires only a single round of human feedback to complete the entire prompt optimization process. Empirical results on both public and industrial datasets show that PLHF outperforms prior output grading strategies for LLM prompt optimizations.
Multi-Timescale Control and Communications with Deep Reinforcement Learning -- Part I: Communication-Aware Vehicle Control
Nov 19, 2023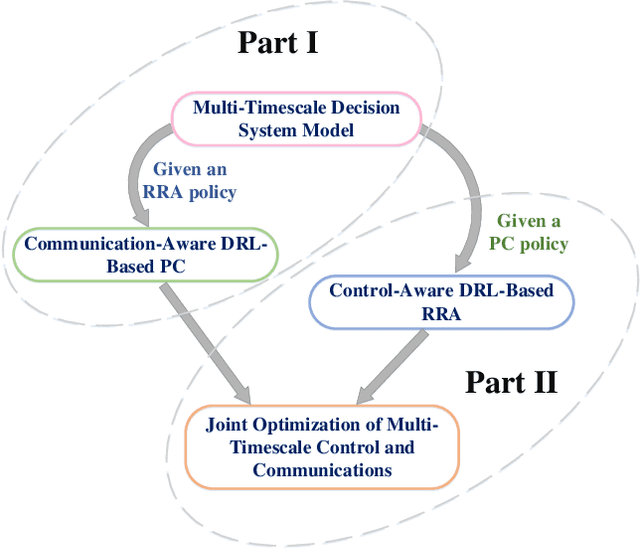
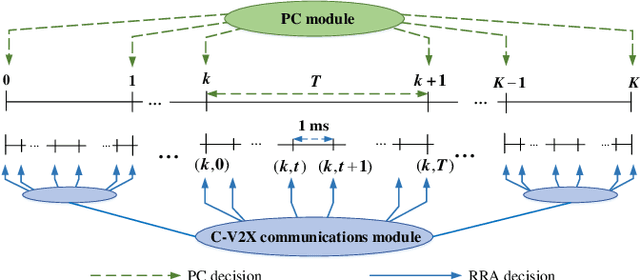
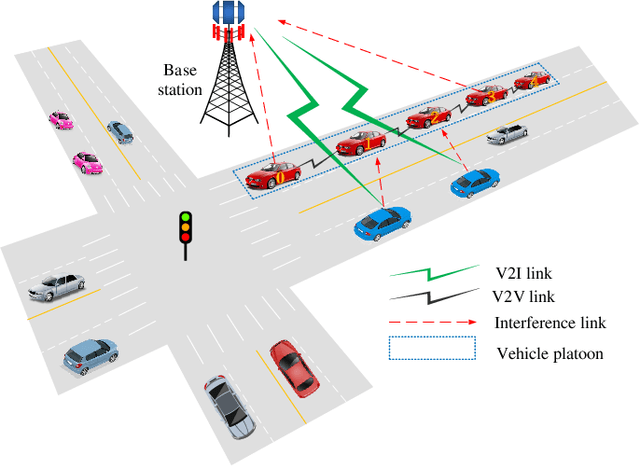
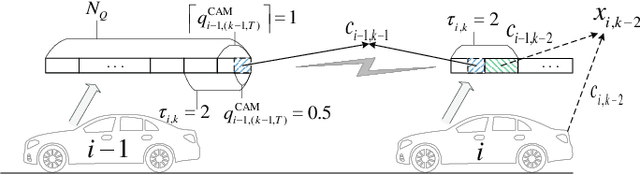
An intelligent decision-making system enabled by Vehicle-to-Everything (V2X) communications is essential to achieve safe and efficient autonomous driving (AD), where two types of decisions have to be made at different timescales, i.e., vehicle control and radio resource allocation (RRA) decisions. The interplay between RRA and vehicle control necessitates their collaborative design. In this two-part paper (Part I and Part II), taking platoon control (PC) as an example use case, we propose a joint optimization framework of multi-timescale control and communications (MTCC) based on Deep Reinforcement Learning (DRL). In this paper (Part I), we first decompose the problem into a communication-aware DRL-based PC sub-problem and a control-aware DRL-based RRA sub-problem. Then, we focus on the PC sub-problem assuming an RRA policy is given, and propose the MTCC-PC algorithm to learn an efficient PC policy. To improve the PC performance under random observation delay, the PC state space is augmented with the observation delay and PC action history. Moreover, the reward function with respect to the augmented state is defined to construct an augmented state Markov Decision Process (MDP). It is proved that the optimal policy for the augmented state MDP is optimal for the original PC problem with observation delay. Different from most existing works on communication-aware control, the MTCC-PC algorithm is trained in a delayed environment generated by the fine-grained embedded simulation of C-V2X communications rather than by a simple stochastic delay model. Finally, experiments are performed to compare the performance of MTCC-PC with those of the baseline DRL algorithms.
Multi-Timescale Control and Communications with Deep Reinforcement Learning -- Part II: Control-Aware Radio Resource Allocation
Nov 19, 2023



In Part I of this two-part paper (Multi-Timescale Control and Communications with Deep Reinforcement Learning -- Part I: Communication-Aware Vehicle Control), we decomposed the multi-timescale control and communications (MTCC) problem in Cellular Vehicle-to-Everything (C-V2X) system into a communication-aware Deep Reinforcement Learning (DRL)-based platoon control (PC) sub-problem and a control-aware DRL-based radio resource allocation (RRA) sub-problem. We focused on the PC sub-problem and proposed the MTCC-PC algorithm to learn an optimal PC policy given an RRA policy. In this paper (Part II), we first focus on the RRA sub-problem in MTCC assuming a PC policy is given, and propose the MTCC-RRA algorithm to learn the RRA policy. Specifically, we incorporate the PC advantage function in the RRA reward function, which quantifies the amount of PC performance degradation caused by observation delay. Moreover, we augment the state space of RRA with PC action history for a more well-informed RRA policy. In addition, we utilize reward shaping and reward backpropagation prioritized experience replay (RBPER) techniques to efficiently tackle the multi-agent and sparse reward problems, respectively. Finally, a sample- and computational-efficient training approach is proposed to jointly learn the PC and RRA policies in an iterative process. In order to verify the effectiveness of the proposed MTCC algorithm, we performed experiments using real driving data for the leading vehicle, where the performance of MTCC is compared with those of the baseline DRL algorithms.
Optimal Scheduling in IoT-Driven Smart Isolated Microgrids Based on Deep Reinforcement Learning
Apr 28, 2023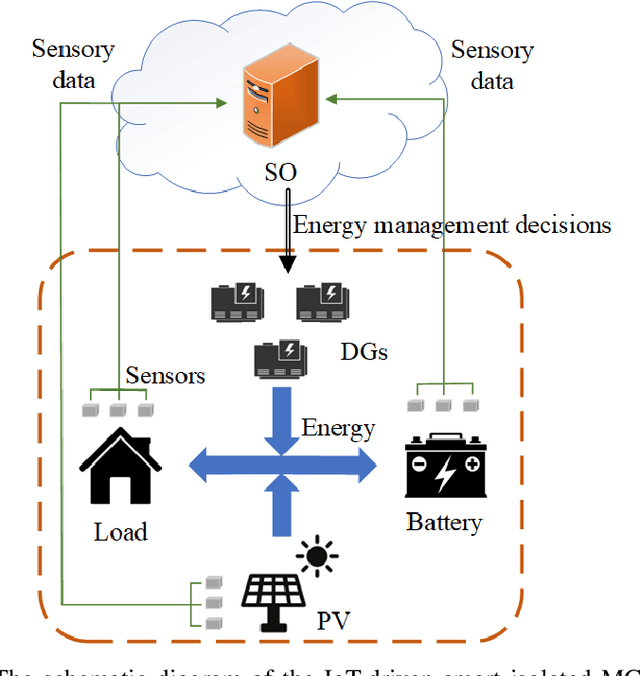
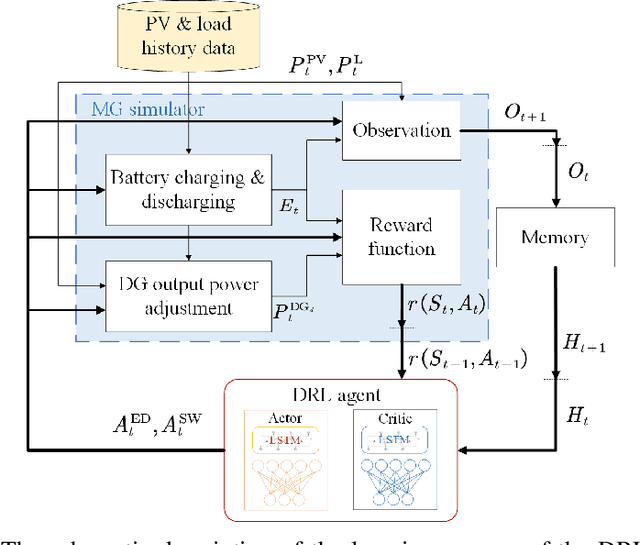
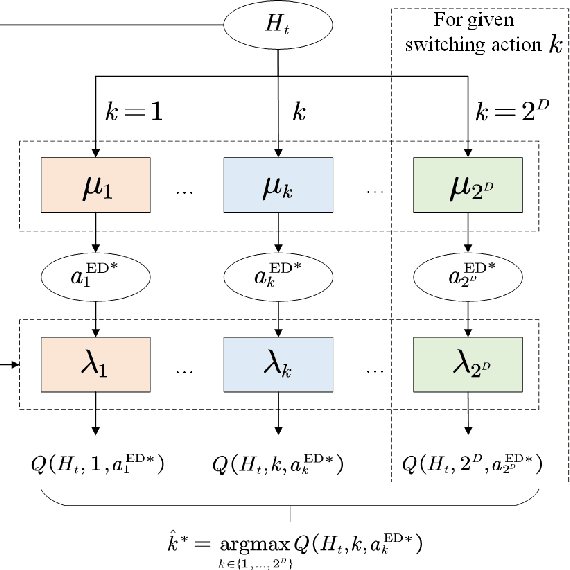
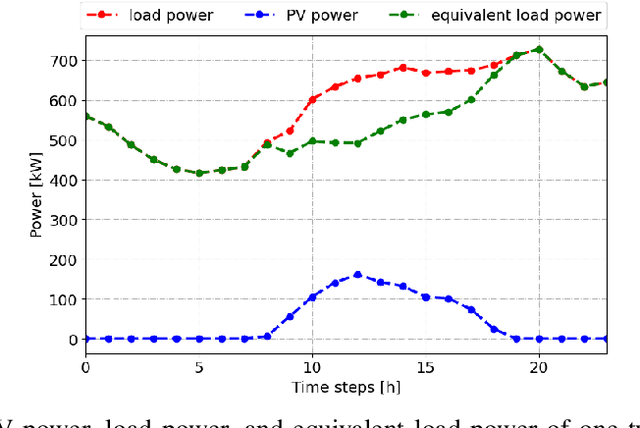
In this paper, we investigate the scheduling issue of diesel generators (DGs) in an Internet of Things (IoT)-Driven isolated microgrid (MG) by deep reinforcement learning (DRL). The renewable energy is fully exploited under the uncertainty of renewable generation and load demand. The DRL agent learns an optimal policy from history renewable and load data of previous days, where the policy can generate real-time decisions based on observations of past renewable and load data of previous hours collected by connected sensors. The goal is to reduce operating cost on the premise of ensuring supply-demand balance. In specific, a novel finite-horizon partial observable Markov decision process (POMDP) model is conceived considering the spinning reserve. In order to overcome the challenge of discrete-continuous hybrid action space due to the binary DG switching decision and continuous energy dispatch (ED) decision, a DRL algorithm, namely the hybrid action finite-horizon RDPG (HAFH-RDPG), is proposed. HAFH-RDPG seamlessly integrates two classical DRL algorithms, i.e., deep Q-network (DQN) and recurrent deterministic policy gradient (RDPG), based on a finite-horizon dynamic programming (DP) framework. Extensive experiments are performed with real-world data in an IoT-driven MG to evaluate the capability of the proposed algorithm in handling the uncertainty due to inter-hour and inter-day power fluctuation and to compare its performance with those of the benchmark algorithms.
Vision-Assisted mmWave Beam Management for Next-Generation Wireless Systems: Concepts, Solutions and Open Challenges
Mar 31, 2023Beamforming techniques have been widely used in the millimeter wave (mmWave) bands to mitigate the path loss of mmWave radio links as the narrow straight beams by directionally concentrating the signal energy. However, traditional mmWave beam management algorithms usually require excessive channel state information overhead, leading to extremely high computational and communication costs. This hinders the widespread deployment of mmWave communications. By contrast, the revolutionary vision-assisted beam management system concept employed at base stations (BSs) can select the optimal beam for the target user equipment (UE) based on its location information determined by machine learning (ML) algorithms applied to visual data, without requiring channel information. In this paper, we present a comprehensive framework for a vision-assisted mmWave beam management system, its typical deployment scenarios as well as the specifics of the framework. Then, some of the challenges faced by this system and their efficient solutions are discussed from the perspective of ML. Next, a new simulation platform is conceived to provide both visual and wireless data for model validation and performance evaluation. Our simulation results indicate that the vision-assisted beam management is indeed attractive for next-generation wireless systems.
Autonomous Platoon Control with Integrated Deep Reinforcement Learning and Dynamic Programming
Jun 15, 2022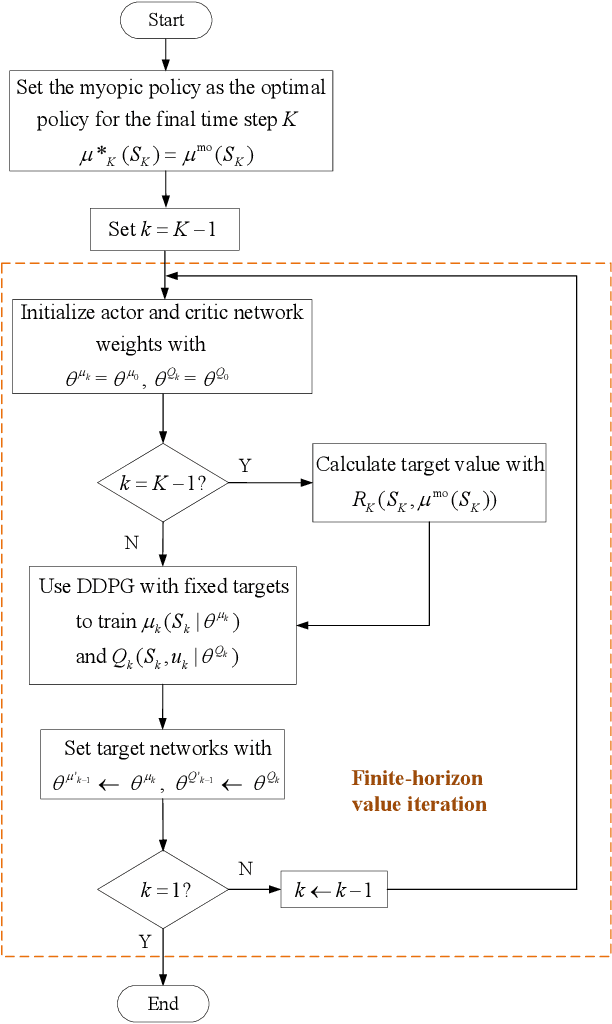
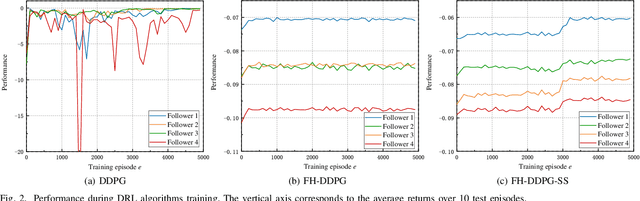
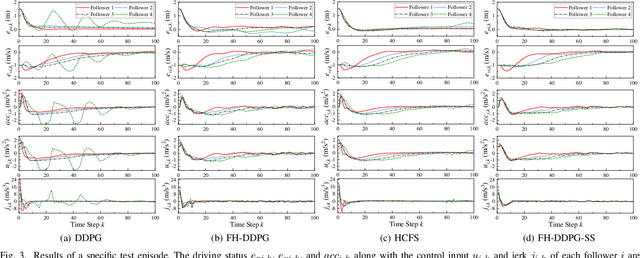
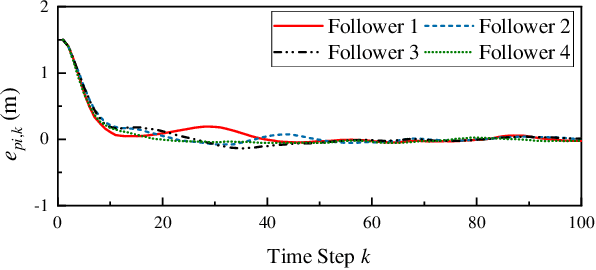
Deep Reinforcement Learning (DRL) is regarded as a potential method for car-following control and has been mostly studied to support a single following vehicle. However, it is more challenging to learn a stable and efficient car-following policy when there are multiple following vehicles in a platoon, especially with unpredictable leading vehicle behavior. In this context, we adopt an integrated DRL and Dynamic Programming (DP) approach to learn autonomous platoon control policies, which embeds the Deep Deterministic Policy Gradient (DDPG) algorithm into a finite-horizon value iteration framework. Although the DP framework can improve the stability and performance of DDPG, it has the limitations of lower sampling and training efficiency. In this paper, we propose an algorithm, namely Finite-Horizon-DDPG with Sweeping through reduced state space using Stationary approximation (FH-DDPG-SS), which uses three key ideas to overcome the above limitations, i.e., transferring network weights backward in time, stationary policy approximation for earlier time steps, and sweeping through reduced state space. In order to verify the effectiveness of FH-DDPG-SS, simulation using real driving data is performed, where the performance of FH-DDPG-SS is compared with those of the benchmark algorithms. Finally, platoon safety and string stability for FH-DDPG-SS are demonstrated.
Joint Energy Dispatch and Unit Commitment in Microgrids Based on Deep Reinforcement Learning
Jun 03, 2022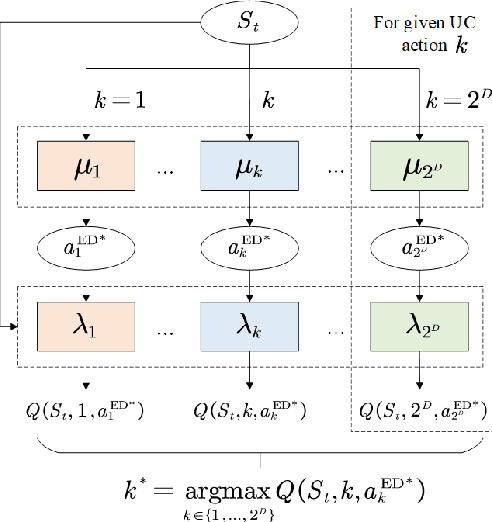
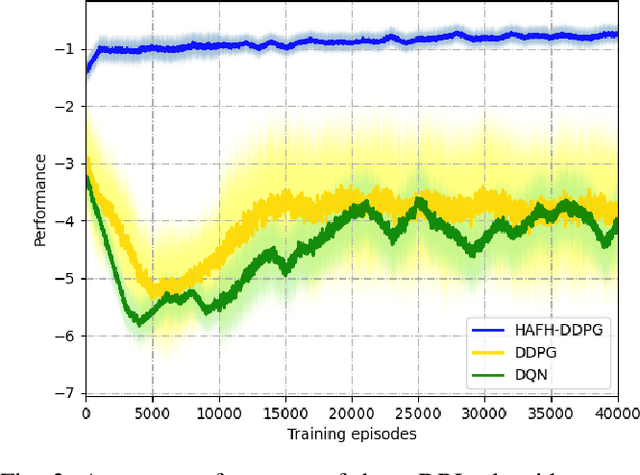
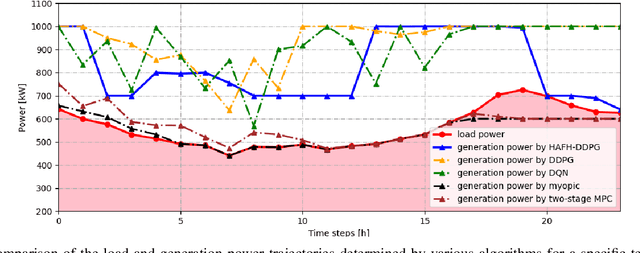
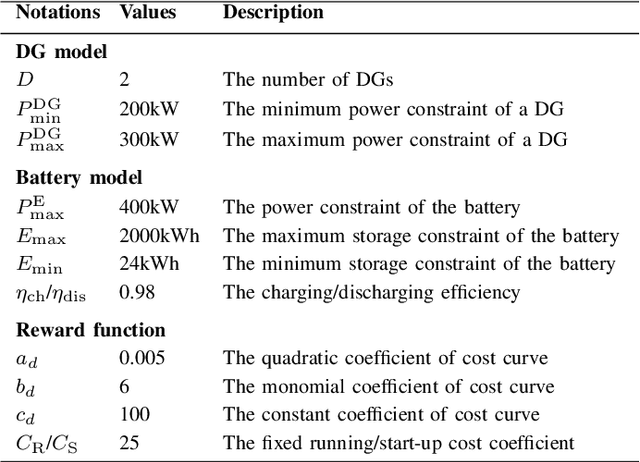
Nowadays, the application of microgrids (MG) with renewable energy is becoming more and more extensive, which creates a strong need for dynamic energy management. In this paper, deep reinforcement learning (DRL) is applied to learn an optimal policy for making joint energy dispatch (ED) and unit commitment (UC) decisions in an isolated MG, with the aim for reducing the total power generation cost on the premise of ensuring the supply-demand balance. In order to overcome the challenge of discrete-continuous hybrid action space due to joint ED and UC, we propose a DRL algorithm, i.e., the hybrid action finite-horizon DDPG (HAFH-DDPG), that seamlessly integrates two classical DRL algorithms, i.e., deep Q-network (DQN) and deep deterministic policy gradient (DDPG), based on a finite-horizon dynamic programming (DP) framework. Moreover, a diesel generator (DG) selection strategy is presented to support a simplified action space for reducing the computation complexity of this algorithm. Finally, the effectiveness of our proposed algorithm is verified through comparison with several baseline algorithms by experiments with real-world data set.
Deep Reinforcement Learning Aided Platoon Control Relying on V2X Information
Mar 28, 2022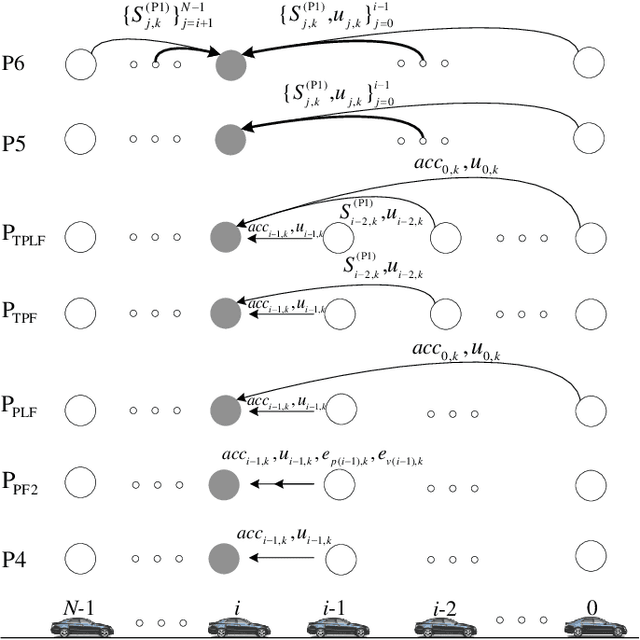
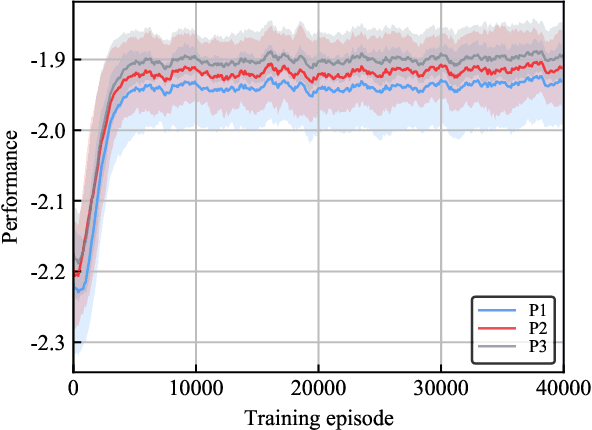
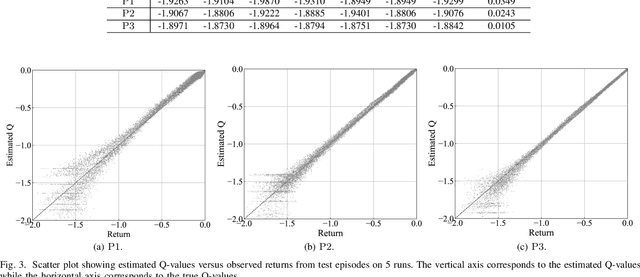
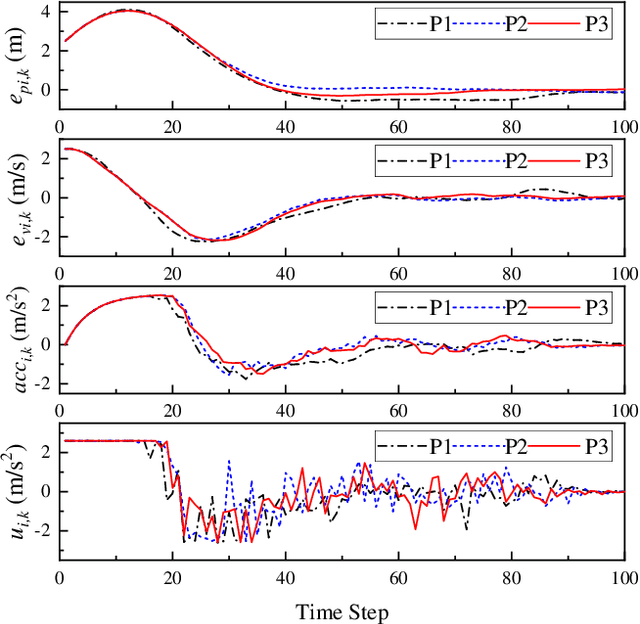
The impact of Vehicle-to-Everything (V2X) communications on platoon control performance is investigated. Platoon control is essentially a sequential stochastic decision problem (SSDP), which can be solved by Deep Reinforcement Learning (DRL) to deal with both the control constraints and uncertainty in the platoon leading vehicle's behavior. In this context, the value of V2X communications for DRL-based platoon controllers is studied with an emphasis on the tradeoff between the gain of including exogenous information in the system state for reducing uncertainty and the performance erosion due to the curse-of-dimensionality. Our objective is to find the specific set of information that should be shared among the vehicles for the construction of the most appropriate state space. SSDP models are conceived for platoon control under different information topologies (IFT) by taking into account `just sufficient' information. Furthermore, theorems are established for comparing the performance of their optimal policies. In order to determine whether a piece of information should or should not be transmitted for improving the DRL-based control policy, we quantify its value by deriving the conditional KL divergence of the transition models. More meritorious information is given higher priority in transmission, since including it in the state space has a higher probability in offsetting the negative effect of having higher state dimensions. Finally, simulation results are provided to illustrate the theoretical analysis.