 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Explicit Deep Representations from Deep Kernel Networks
Paper and Code
Apr 30, 2018


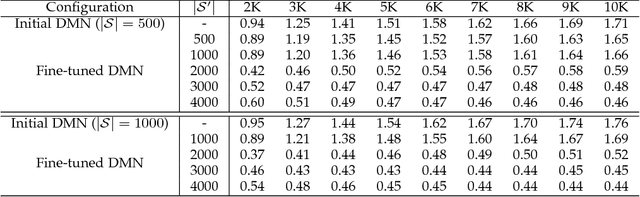
Deep kernel learning aims at designing nonlinear combinations of multiple standard elementary kernels by training deep networks. This scheme has proven to be effective, but intractable when handling large-scale datasets especially when the depth of the trained networks increases; indeed, the complexity of evaluating these networks scales quadratically w.r.t. the size of training data and linearly w.r.t. the depth of the trained networks. In this paper, we address the issue of efficient computation in Deep Kernel Networks (DKNs) by designing effective maps in the underlying Reproducing Kernel Hilbert Spaces. Given a pretrained DKN, our method builds its associated Deep Map Network (DMN) whose inner product approximates the original network while being far more efficient. The design principle of our method is greedy and achieved layer-wise, by finding maps that approximate DKNs at different (input, intermediate and output) layers. This design also considers an extra fine-tuning step based on unsupervised learning, that further enhances the generalization ability of the trained DMNs. When plugged into SVMs, these DMNs turn out to be as accurate as the underlying DKNs while being at least an order of magnitude faster on large-scale datasets, as shown through extensive experiments on the challenging ImageCLEF and COREL5k benchmarks.