 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComprehensive Graph Gradual Pruning for Sparse Training in Graph Neural Networks
Paper and Code
Jul 19, 2022

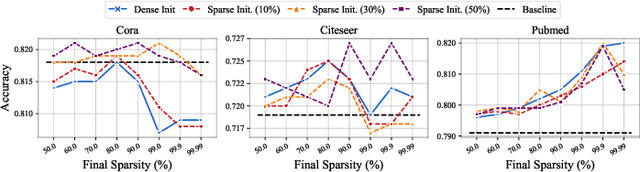

Graph Neural Networks (GNNs) tend to suffer from high computation costs due to the exponentially increasing scale of graph data and the number of model parameters, which restricts their utility in practical applications. To this end, some recent works focus on sparsifying GNNs with the lottery ticket hypothesis (LTH) to reduce inference costs while maintaining performance levels. However, the LTH-based methods suffer from two major drawbacks: 1) they require exhaustive and iterative training of dense models, resulting in an extremely large training computation cost, and 2) they only trim graph structures and model parameters but ignore the node feature dimension, where significant redundancy exists. To overcome the above limitations, we propose a comprehensive graph gradual pruning framework termed CGP. This is achieved by designing a during-training graph pruning paradigm to dynamically prune GNNs within one training process. Unlike LTH-based methods, the proposed CGP approach requires no re-training, which significantly reduces the computation costs. Furthermore, we design a co-sparsifying strategy to comprehensively trim all three core elements of GNNs: graph structures, node features, and model parameters. Meanwhile, aiming at refining the pruning operation, we introduce a regrowth process into our CGP framework, in order to re-establish the pruned but important connections. The proposed CGP is evaluated by using a node classification task across 6 GNN architectures, including shallow models (GCN and GAT), shallow-but-deep-propagation models (SGC and APPNP), and deep models (GCNII and ResGCN), on a total of 14 real-world graph datasets, including large-scale graph datasets from the challenging Open Graph Benchmark. Experiments reveal that our proposed strategy greatly improves both training and inference efficiency while matching or even exceeding the accuracy of existing methods.