 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular Depth Guided Occlusion-Aware Disparity Refinement via Semi-supervised Learning in Laparoscopic Images
May 13, 2025Occlusion and the scarcity of labeled surgical data are significant challenges in disparity estimation for stereo laparoscopic images. To address these issues, this study proposes a Depth Guided Occlusion-Aware Disparity Refinement Network (DGORNet), which refines disparity maps by leveraging monocular depth information unaffected by occlusion. A Position Embedding (PE) module is introduced to provide explicit spatial context, enhancing the network's ability to localize and refine features. Furthermore, we introduce an Optical Flow Difference Loss (OFDLoss) for unlabeled data, leveraging temporal continuity across video frames to improve robustness in dynamic surgical scenes. Experiments on the SCARED dataset demonstrate that DGORNet outperforms state-of-the-art methods in terms of End-Point Error (EPE) and Root Mean Squared Error (RMSE), particularly in occlusion and texture-less regions. Ablation studies confirm the contributions of the Position Embedding and Optical Flow Difference Loss, highlighting their roles in improving spatial and temporal consistency. These results underscore DGORNet's effectiveness in enhancing disparity estimation for laparoscopic surgery, offering a practical solution to challenges in disparity estimation and data limitations.
Attention-Aware Laparoscopic Image Desmoking Network with Lightness Embedding and Hybrid Guided Embedding
Apr 11, 2024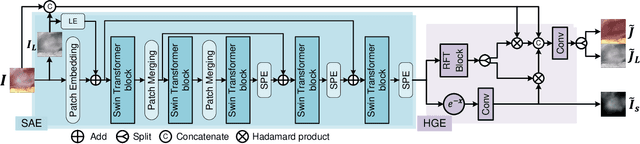
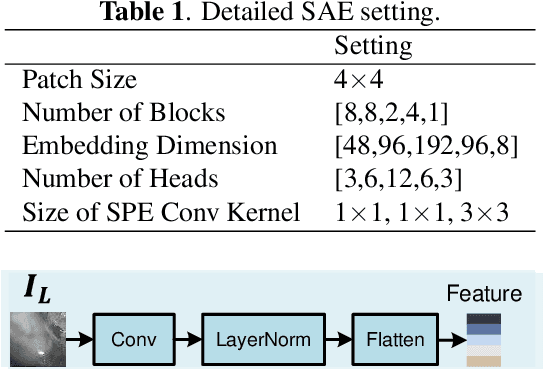
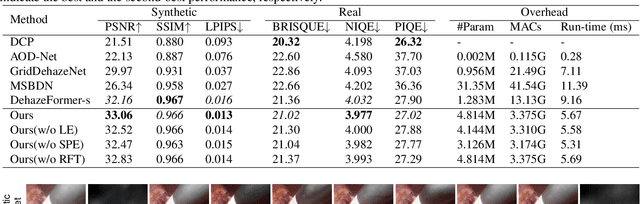
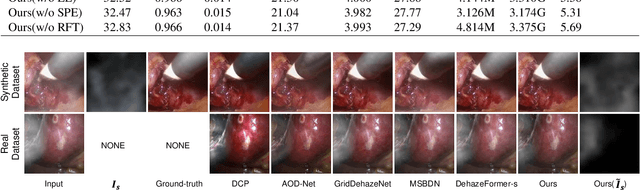
This paper presents a novel method of smoke removal from the laparoscopic images. Due to the heterogeneous nature of surgical smoke, a two-stage network is proposed to estimate the smoke distribution and reconstruct a clear, smoke-free surgical scene. The utilization of the lightness channel plays a pivotal role in providing vital information pertaining to smoke density. The reconstruction of smoke-free image is guided by a hybrid embedding, which combines the estimated smoke mask with the initial image. Experimental results demonstrate that the proposed method boasts a Peak Signal to Noise Ratio that is $2.79\%$ higher than the state-of-the-art methods, while also exhibits a remarkable $38.2\%$ reduction in run-time. Overall, the proposed method offers comparable or even superior performance in terms of both smoke removal quality and computational efficiency when compared to existing state-of-the-art methods. This work will be publicly available on http://homepage.hit.edu.cn/wpgao
Synthetic Training for Monocular Human Mesh Recovery
Oct 27, 2020
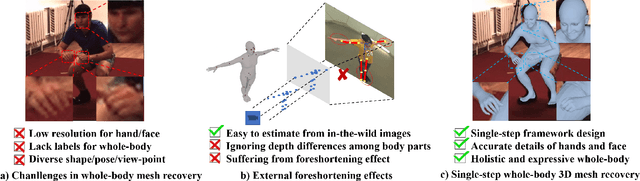
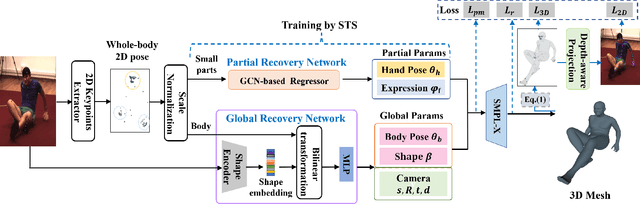
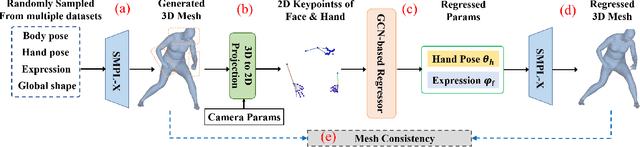
Recovering 3D human mesh from monocular images is a popular topic in computer vision and has a wide range of applications. This paper aims to estimate 3D mesh of multiple body parts (e.g., body, hands) with large-scale differences from a single RGB image. Existing methods are mostly based on iterative optimization, which is very time-consuming. We propose to train a single-shot model to achieve this goal. The main challenge is lacking training data that have complete 3D annotations of all body parts in 2D images. To solve this problem, we design a multi-branch framework to disentangle the regression of different body properties, enabling us to separate each component's training in a synthetic training manner using unpaired data available. Besides, to strengthen the generalization ability, most existing methods have used in-the-wild 2D pose datasets to supervise the estimated 3D pose via 3D-to-2D projection. However, we observe that the commonly used weak-perspective model performs poorly in dealing with the external foreshortening effect of camera projection. Therefore, we propose a depth-to-scale (D2S) projection to incorporate the depth difference into the projection function to derive per-joint scale variants for more proper supervision. The proposed method outperforms previous methods on the CMU Panoptic Studio dataset according to the evaluation results and achieves comparable results on the Human3.6M body and STB hand benchmarks. More impressively, the performance in close shot images gets significantly improved using the proposed D2S projection for weak supervision, while maintains obvious superiority in computational efficiency.