 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPDiffusion: Semantic Protection Diffusion for Multi-concept Text-to-image Generation
Sep 02, 2024



Recent text-to-image models have achieved remarkable success in generating high-quality images. However, when tasked with multi-concept generation which creates images containing multiple characters or objects, existing methods often suffer from attribute confusion, resulting in severe text-image inconsistency. We found that attribute confusion occurs when a certain region of the latent features attend to multiple or incorrect prompt tokens. In this work, we propose novel Semantic Protection Diffusion (SPDiffusion) to protect the semantics of regions from the influence of irrelevant tokens, eliminating the confusion of non-corresponding attributes. In the SPDiffusion framework, we design a Semantic Protection Mask (SP-Mask) to represent the relevance of the regions and the tokens, and propose a Semantic Protection Cross-Attention (SP-Attn) to shield the influence of irrelevant tokens on specific regions in the generation process. To evaluate our method, we created a diverse multi-concept benchmark, and SPDiffusion achieves state-of-the-art results on this benchmark, proving its effectiveness. Our method can be combined with many other application methods or backbones, such as ControlNet, Story Diffusion, PhotoMaker and PixArt-alpha to enhance their multi-concept capabilities, demonstrating strong compatibility and scalability.
Adversarial Representation Sharing: A Quantitative and Secure Collaborative Learning Framework
Mar 27, 2022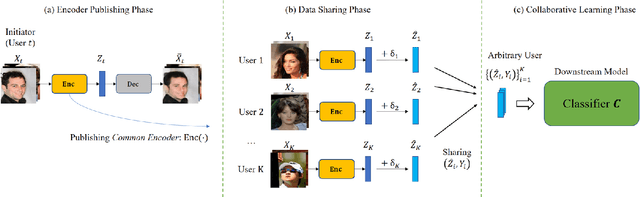

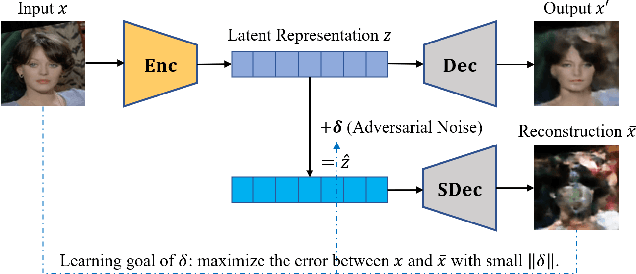

The performance of deep learning models highly depends on the amount of training data. It is common practice for today's data holders to merge their datasets and train models collaboratively, which yet poses a threat to data privacy. Different from existing methods such as secure multi-party computation (MPC) and federated learning (FL), we find representation learning has unique advantages in collaborative learning due to the lower communication overhead and task-independency. However, data representations face the threat of model inversion attacks. In this article, we formally define the collaborative learning scenario, and quantify data utility and privacy. Then we present ARS, a collaborative learning framework wherein users share representations of data to train models, and add imperceptible adversarial noise to data representations against reconstruction or attribute extraction attacks. By evaluating ARS in different contexts, we demonstrate that our mechanism is effective against model inversion attacks, and achieves a balance between privacy and utility. The ARS framework has wide applicability. First, ARS is valid for various data types, not limited to images. Second, data representations shared by users can be utilized in different tasks. Third, the framework can be easily extended to the vertical data partitioning scenario.