 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Gradient Inversion Attacks with Robust Optimization
Jun 13, 2023



Federated Learning (FL) has emerged as a promising approach for collaborative model training without sharing private data. However, privacy concerns regarding information exchanged during FL have received significant research attention. Gradient Inversion Attacks (GIAs) have been proposed to reconstruct the private data retained by local clients from the exchanged gradients. While recovering private data, the data dimensions and the model complexity increase, which thwart data reconstruction by GIAs. Existing methods adopt prior knowledge about private data to overcome those challenges. In this paper, we first observe that GIAs with gradients from a single iteration fail to reconstruct private data due to insufficient dimensions of leaked gradients, complex model architectures, and invalid gradient information. We investigate a Temporal Gradient Inversion Attack with a Robust Optimization framework, called TGIAs-RO, which recovers private data without any prior knowledge by leveraging multiple temporal gradients. To eliminate the negative impacts of outliers, e.g., invalid gradients for collaborative optimization, robust statistics are proposed. Theoretical guarantees on the recovery performance and robustness of TGIAs-RO against invalid gradients are also provided. Extensive empirical results on MNIST, CIFAR10, ImageNet and Reuters 21578 datasets show that the proposed TGIAs-RO with 10 temporal gradients improves reconstruction performance compared to state-of-the-art methods, even for large batch sizes (up to 128), complex models like ResNet18, and large datasets like ImageNet (224*224 pixels). Furthermore, the proposed attack method inspires further exploration of privacy-preserving methods in the context of FL.
Adversarial Representation Sharing: A Quantitative and Secure Collaborative Learning Framework
Mar 27, 2022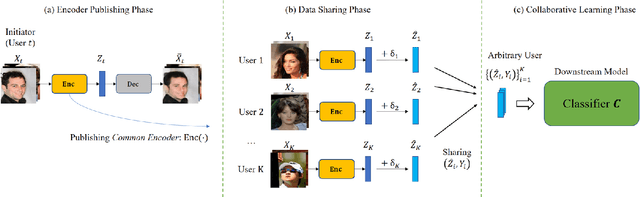

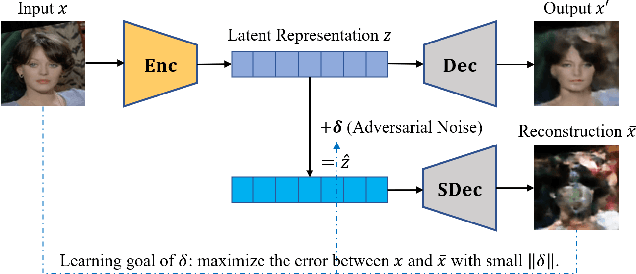

The performance of deep learning models highly depends on the amount of training data. It is common practice for today's data holders to merge their datasets and train models collaboratively, which yet poses a threat to data privacy. Different from existing methods such as secure multi-party computation (MPC) and federated learning (FL), we find representation learning has unique advantages in collaborative learning due to the lower communication overhead and task-independency. However, data representations face the threat of model inversion attacks. In this article, we formally define the collaborative learning scenario, and quantify data utility and privacy. Then we present ARS, a collaborative learning framework wherein users share representations of data to train models, and add imperceptible adversarial noise to data representations against reconstruction or attribute extraction attacks. By evaluating ARS in different contexts, we demonstrate that our mechanism is effective against model inversion attacks, and achieves a balance between privacy and utility. The ARS framework has wide applicability. First, ARS is valid for various data types, not limited to images. Second, data representations shared by users can be utilized in different tasks. Third, the framework can be easily extended to the vertical data partitioning scenario.
Improving the Efficiency and Robustness of Deepfakes Detection through Precise Geometric Features
Apr 09, 2021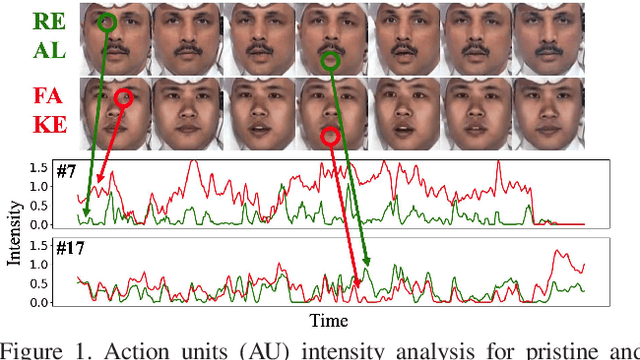
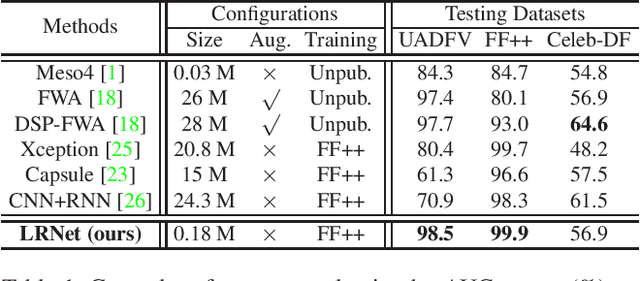
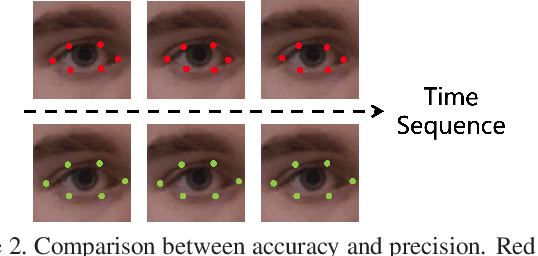
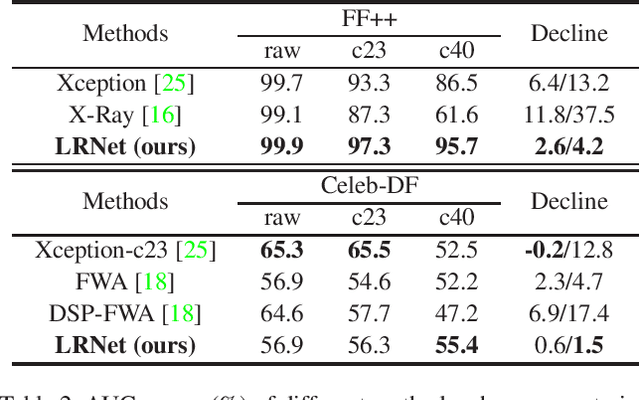
Deepfakes is a branch of malicious techniques that transplant a target face to the original one in videos, resulting in serious problems such as infringement of copyright, confusion of information, or even public panic. Previous efforts for Deepfakes videos detection mainly focused on appearance features, which have a risk of being bypassed by sophisticated manipulation, also resulting in high model complexity and sensitiveness to noise. Besides, how to mine the temporal features of manipulated videos and exploit them is still an open question. We propose an efficient and robust framework named LRNet for detecting Deepfakes videos through temporal modeling on precise geometric features. A novel calibration module is devised to enhance the precision of geometric features, making it more discriminative, and a two-stream Recurrent Neural Network (RNN) is constructed for sufficient exploitation of temporal features. Compared to previous methods, our proposed method is lighter-weighted and easier to train. Moreover, our method has shown robustness in detecting highly compressed or noise corrupted videos. Our model achieved 0.999 AUC on FaceForensics++ dataset. Meanwhile, it has a graceful decline in performance (-0.042 AUC) when faced with highly compressed videos.
Label Smoothing and Adversarial Robustness
Sep 17, 2020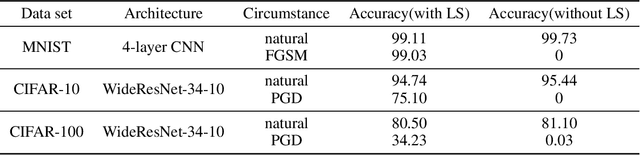
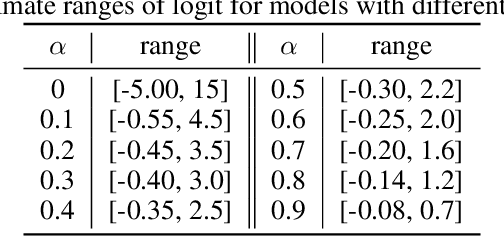
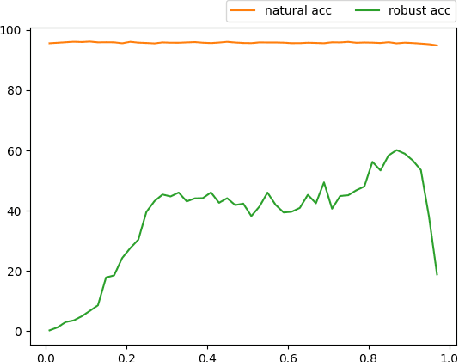
Recent studies indicate that current adversarial attack methods are flawed and easy to fail when encountering some deliberately designed defense. Sometimes even a slight modification in the model details will invalidate the attack. We find that training model with label smoothing can easily achieve striking accuracy under most gradient-based attacks. For instance, the robust accuracy of a WideResNet model trained with label smoothing on CIFAR-10 achieves 75% at most under PGD attack. To understand the reason underlying the subtle robustness, we investigate the relationship between label smoothing and adversarial robustness. Through theoretical analysis about the characteristics of the network trained with label smoothing and experiment verification of its performance under various attacks. We demonstrate that the robustness produced by label smoothing is incomplete based on the fact that its defense effect is volatile, and it cannot defend attacks transferred from a naturally trained model. Our study enlightens the research community to rethink how to evaluate the model's robustness appropriately.
FraudJudger: Real-World Data Oriented Fraud Detection on Digital Payment Platforms
Sep 05, 2019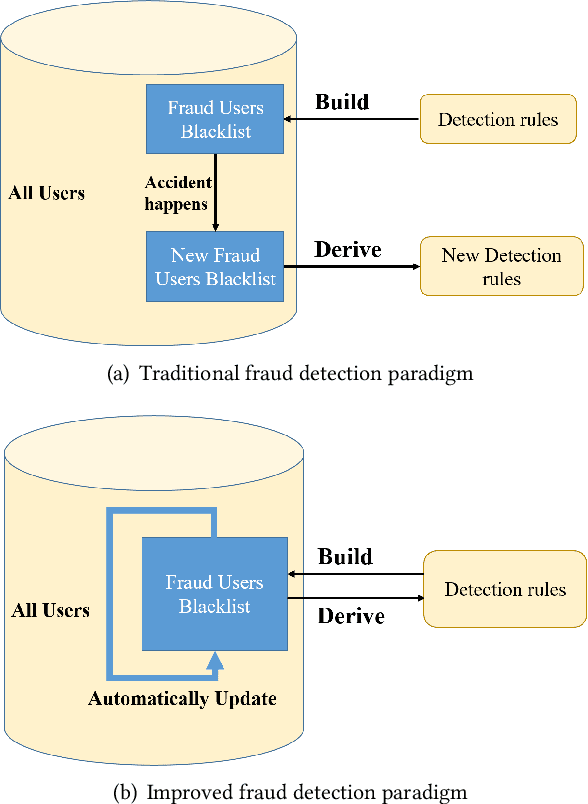
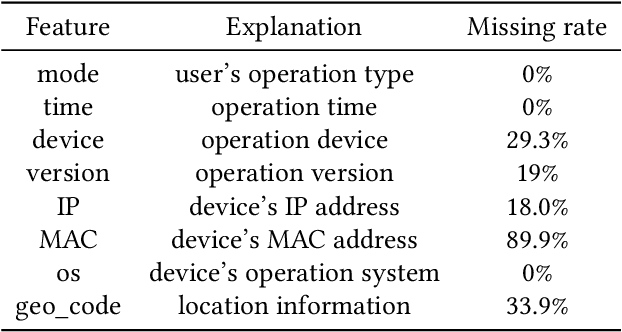
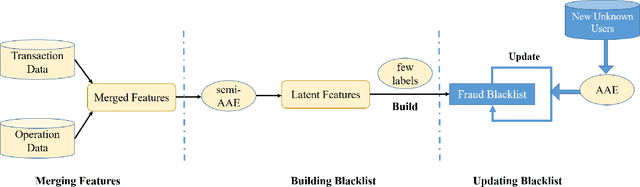
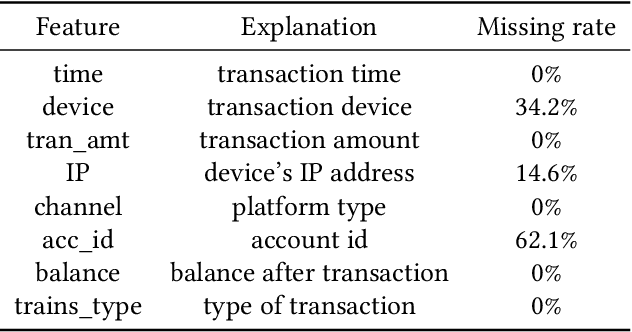
Automated fraud behaviors detection on electronic payment platforms is a tough problem. Fraud users often exploit the vulnerability of payment platforms and the carelessness of users to defraud money, steal passwords, do money laundering, etc, which causes enormous losses to digital payment platforms and users. There are many challenges for fraud detection in practice. Traditional fraud detection methods require a large-scale manually labeled dataset, which is hard to obtain in reality. Manually labeled data cost tremendous human efforts. Besides, the continuous and rapid evolution of fraud users makes it hard to find new fraud patterns based on existing detection rules. In our work, we propose a real-world data oriented detection paradigm which can detect fraud users and upgrade its detection ability automatically. Based on the new paradigm, we design a novel fraud detection model, FraudJudger, to analyze users behaviors on digital payment platforms and detect fraud users with fewer labeled data in training. FraudJudger can learn the latent representations of users from unlabeled data with the help of Adversarial Autoencoder (AAE). Furthermore, FraudJudger can find new fraud patterns from unknown users by cluster analysis. Our experiment is based on a real-world electronic payment dataset. Comparing with other well-known fraud detection methods, FraudJudger can achieve better detection performance with only 10% labeled data.