 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Representation Sharing: A Quantitative and Secure Collaborative Learning Framework
Mar 27, 2022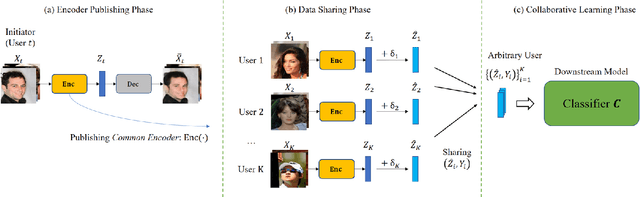

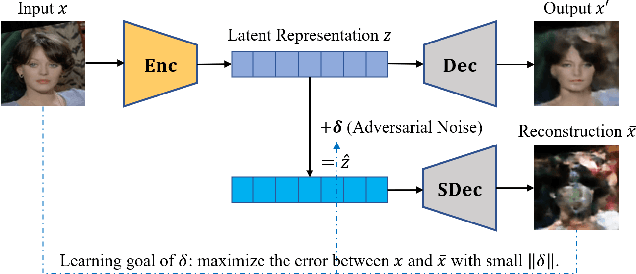

The performance of deep learning models highly depends on the amount of training data. It is common practice for today's data holders to merge their datasets and train models collaboratively, which yet poses a threat to data privacy. Different from existing methods such as secure multi-party computation (MPC) and federated learning (FL), we find representation learning has unique advantages in collaborative learning due to the lower communication overhead and task-independency. However, data representations face the threat of model inversion attacks. In this article, we formally define the collaborative learning scenario, and quantify data utility and privacy. Then we present ARS, a collaborative learning framework wherein users share representations of data to train models, and add imperceptible adversarial noise to data representations against reconstruction or attribute extraction attacks. By evaluating ARS in different contexts, we demonstrate that our mechanism is effective against model inversion attacks, and achieves a balance between privacy and utility. The ARS framework has wide applicability. First, ARS is valid for various data types, not limited to images. Second, data representations shared by users can be utilized in different tasks. Third, the framework can be easily extended to the vertical data partitioning scenario.