 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Stakeholder LLM Alignment: Decomposing Estimation from Aggregation
May 26, 2026Multi-stakeholder tasks require one output to satisfy users with conflicting preferences. Holistic LLM judges conflate utility estimation and utility aggregation, yielding unstable implicit weights. We show empirically and theoretically that this aggregation-specific \emph{weighting noise} can create large score shifts when stakeholder satisfaction is dispersed; in our experiments, these weight-induced shifts also increase with stakeholder count. We propose \textsc{DecompR}: counterfactual-calibrated weights are fixed from query structure before candidate scoring, while per-role utilities are estimated independently, removing candidate-dependent weight drift and reducing estimation noise.
No More Stale Feedback: Co-Evolving Critics for Open-World Agent Learning
Jan 11, 2026Critique-guided reinforcement learning (RL) has emerged as a powerful paradigm for training LLM agents by augmenting sparse outcome rewards with natural-language feedback. However, current methods often rely on static or offline critic models, which fail to adapt as the policy evolves. In on-policy RL, the agent's error patterns shift over time, causing stationary critics to become stale and providing feedback of diminishing utility. To address this, we introduce ECHO (Evolving Critic for Hindsight-Guided Optimization)}, a framework that jointly optimizes the policy and critic through a synchronized co-evolutionary loop. ECHO utilizes a cascaded rollout mechanism where the critic generates multiple diagnoses for an initial trajectory, followed by policy refinement to enable group-structured advantage estimation. We address the challenge of learning plateaus via a saturation-aware gain shaping objective, which rewards the critic for inducing incremental improvements in high-performing trajectories. By employing dual-track GRPO updates, ECHO ensures the critic's feedback stays synchronized with the evolving policy. Experimental results show that ECHO yields more stable training and higher long-horizon task success across open-world environments.
TravelBench: A Broader Real-World Benchmark for Multi-Turn and Tool-Using Travel Planning
Jan 05, 2026Travel planning is a natural real-world task to test large language models (LLMs) planning and tool-use abilities. Although prior work has studied LLM performance on travel planning, existing settings still differ from real-world needs, mainly due to limited domain coverage, insufficient modeling of users' implicit preferences in multi-turn conversations, and a lack of clear evaluation of agents' capability boundaries. To mitigate these gaps, we propose \textbf{TravelBench}, a benchmark for fully real-world travel planning. We collect user queries, user profile and tools from real scenarios, and construct three subtasks-Single-Turn, Multi-Turn, and Unsolvable-to evaluate agent's three core capabilities in real settings: (1) solving problems autonomously, (2) interacting with users over multiple turns to refine requirements, and (3) recognizing the limits of own abilities. To enable stable tool invocation and reproducible evaluation, we cache real tool-call results and build a sandbox environment that integrates ten travel-related tools. Agents can combine these tools to solve most practical travel planning problems, and our systematic verification demonstrates the stability of the proposed benchmark. We further evaluate multiple LLMs on TravelBench and conduct an in-depth analysis of their behaviors and performance. TravelBench provides a practical and reproducible evaluation benchmark to advance research on LLM agents for travel planning.\footnote{Our code and data will be available after internal review.
AMAP Agentic Planning Technical Report
Dec 31, 2025We present STAgent, an agentic large language model tailored for spatio-temporal understanding, designed to solve complex tasks such as constrained point-of-interest discovery and itinerary planning. STAgent is a specialized model capable of interacting with ten distinct tools within spatio-temporal scenarios, enabling it to explore, verify, and refine intermediate steps during complex reasoning. Notably, STAgent effectively preserves its general capabilities. We empower STAgent with these capabilities through three key contributions: (1) a stable tool environment that supports over ten domain-specific tools, enabling asynchronous rollout and training; (2) a hierarchical data curation framework that identifies high-quality data like a needle in a haystack, curating high-quality queries with a filter ratio of 1:10,000, emphasizing both diversity and difficulty; and (3) a cascaded training recipe that starts with a seed SFT stage acting as a guardian to measure query difficulty, followed by a second SFT stage fine-tuned on queries with high certainty, and an ultimate RL stage that leverages data of low certainty. Initialized with Qwen3-30B-A3B to establish a strong SFT foundation and leverage insights into sample difficulty, STAgent yields promising performance on TravelBench while maintaining its general capabilities across a wide range of general benchmarks, thereby demonstrating the effectiveness of our proposed agentic model.
TravelBench: A Real-World Benchmark for Multi-Turn and Tool-Augmented Travel Planning
Dec 27, 2025Large language model (LLM) agents have demonstrated strong capabilities in planning and tool use. Travel planning provides a natural and high-impact testbed for these capabilities, as it requires multi-step reasoning, iterative preference elicitation through interaction, and calls to external tools under evolving constraints. Prior work has studied LLMs on travel-planning tasks, but existing settings are limited in domain coverage and multi-turn interaction. As a result, they cannot support dynamic user-agent interaction and therefore fail to comprehensively assess agent capabilities. In this paper, we introduce TravelBench, a real-world travel-planning benchmark featuring multi-turn interaction and tool use. We collect user requests from real-world scenarios and construct three subsets-multi-turn, single-turn, and unsolvable-to evaluate different aspects of agent performance. For stable and reproducible evaluation, we build a controlled sandbox environment with 10 travel-domain tools, providing deterministic tool outputs for reliable reasoning. We evaluate multiple LLMs on TravelBench and conduct an analysis of their behaviors and performance. TravelBench offers a practical and reproducible benchmark for advancing LLM agents in travel planning.
SketchPlay: Intuitive Creation of Physically Realistic VR Content with Gesture-Driven Sketching
Dec 26, 2025Creating physically realistic content in VR often requires complex modeling tools or predefined 3D models, textures, and animations, which present significant barriers for non-expert users. In this paper, we propose SketchPlay, a novel VR interaction framework that transforms humans' air-drawn sketches and gestures into dynamic, physically realistic scenes, making content creation intuitive and playful like drawing. Specifically, sketches capture the structure and spatial arrangement of objects and scenes, while gestures convey physical cues such as velocity, direction, and force that define movement and behavior. By combining these complementary forms of input, SketchPlay captures both the structure and dynamics of user-created content, enabling the generation of a wide range of complex physical phenomena, such as rigid body motion, elastic deformation, and cloth dynamics. Experimental results demonstrate that, compared to traditional text-driven methods, SketchPlay offers significant advantages in expressiveness, and user experience. By providing an intuitive and engaging creation process, SketchPlay lowers the entry barrier for non-expert users and shows strong potential for applications in education, art, and immersive storytelling.
AccidentSim: Generating Physically Realistic Vehicle Collision Videos from Real-World Accident Reports
Mar 26, 2025

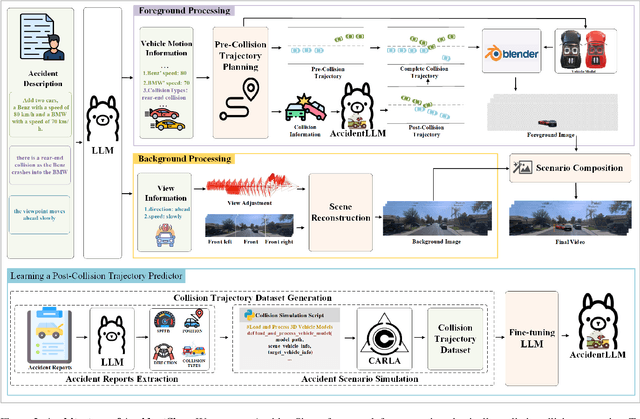

Collecting real-world vehicle accident videos for autonomous driving research is challenging due to their rarity and complexity. While existing driving video generation methods may produce visually realistic videos, they often fail to deliver physically realistic simulations because they lack the capability to generate accurate post-collision trajectories. In this paper, we introduce AccidentSim, a novel framework that generates physically realistic vehicle collision videos by extracting and utilizing the physical clues and contextual information available in real-world vehicle accident reports. Specifically, AccidentSim leverages a reliable physical simulator to replicate post-collision vehicle trajectories from the physical and contextual information in the accident reports and to build a vehicle collision trajectory dataset. This dataset is then used to fine-tune a language model, enabling it to respond to user prompts and predict physically consistent post-collision trajectories across various driving scenarios based on user descriptions. Finally, we employ Neural Radiance Fields (NeRF) to render high-quality backgrounds, merging them with the foreground vehicles that exhibit physically realistic trajectories to generate vehicle collision videos. Experimental results demonstrate that the videos produced by AccidentSim excel in both visual and physical authenticity.
Finedeep: Mitigating Sparse Activation in Dense LLMs via Multi-Layer Fine-Grained Experts
Feb 18, 2025



Large language models have demonstrated exceptional performance across a wide range of tasks. However, dense models usually suffer from sparse activation, where many activation values tend towards zero (i.e., being inactivated). We argue that this could restrict the efficient exploration of model representation space. To mitigate this issue, we propose Finedeep, a deep-layered fine-grained expert architecture for dense models. Our framework partitions the feed-forward neural network layers of traditional dense models into small experts, arranges them across multiple sub-layers. A novel routing mechanism is proposed to determine each expert's contribution. We conduct extensive experiments across various model sizes, demonstrating that our approach significantly outperforms traditional dense architectures in terms of perplexity and benchmark performance while maintaining a comparable number of parameters and floating-point operations. Moreover, we find that Finedeep achieves optimal results when balancing depth and width, specifically by adjusting the number of expert sub-layers and the number of experts per sub-layer. Empirical results confirm that Finedeep effectively alleviates sparse activation and efficiently utilizes representation capacity in dense models.
MSP: Multi-Stage Prompting for Making Pre-trained Language Models Better Translators
Oct 13, 2021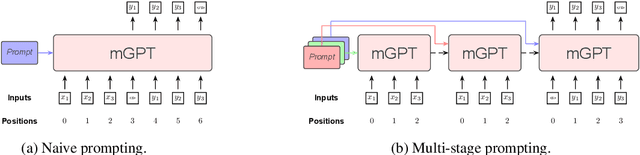
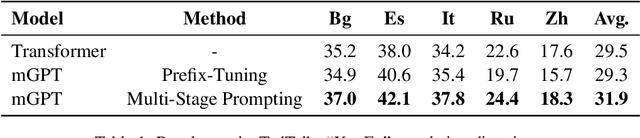
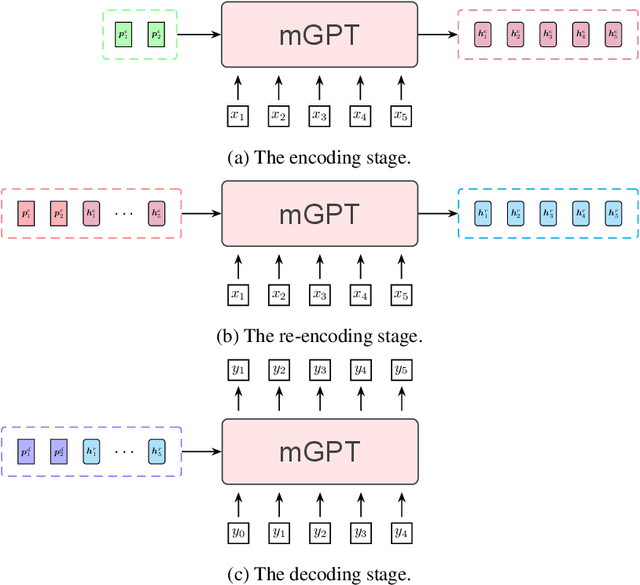

Pre-trained language models have recently been shown to be able to perform translation without finetuning via prompting. Inspired by these findings, we study improving the performance of pre-trained language models on translation tasks, where training neural machine translation models is the current de facto approach. We present Multi-Stage Prompting, a simple and lightweight approach for better adapting pre-trained language models to translation tasks. To make pre-trained language models better translators, we divide the translation process via pre-trained language models into three separate stages: the encoding stage, the re-encoding stage, and the decoding stage. During each stage, we independently apply different continuous prompts for allowing pre-trained language models better adapting to translation tasks. We conduct extensive experiments on low-, medium-, and high-resource translation tasks. Experiments show that our method can significantly improve the translation performance of pre-trained language models.
Otem&Utem: Over- and Under-Translation Evaluation Metric for NMT
Jul 24, 2018

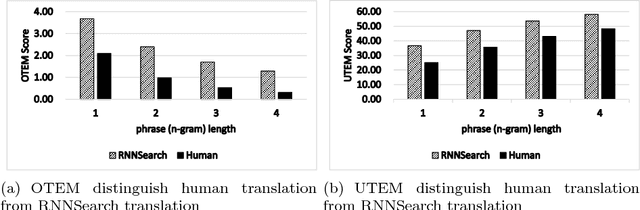

Although neural machine translation(NMT) yields promising translation performance, it unfortunately suffers from over- and under-translation is- sues [Tu et al., 2016], of which studies have become research hotspots in NMT. At present, these studies mainly apply the dominant automatic evaluation metrics, such as BLEU, to evaluate the overall translation quality with respect to both adequacy and uency. However, they are unable to accurately measure the ability of NMT systems in dealing with the above-mentioned issues. In this paper, we propose two quantitative metrics, the Otem and Utem, to automatically evaluate the system perfor- mance in terms of over- and under-translation respectively. Both metrics are based on the proportion of mismatched n-grams between gold ref- erence and system translation. We evaluate both metrics by comparing their scores with human evaluations, where the values of Pearson Cor- relation Coefficient reveal their strong correlation. Moreover, in-depth analyses on various translation systems indicate some inconsistency be- tween BLEU and our proposed metrics, highlighting the necessity and significance of our metrics.