 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple is what you need for efficient and accurate medical image segmentation
Jun 16, 2025While modern segmentation models often prioritize performance over practicality, we advocate a design philosophy prioritizing simplicity and efficiency, and attempted high performance segmentation model design. This paper presents SimpleUNet, a scalable ultra-lightweight medical image segmentation model with three key innovations: (1) A partial feature selection mechanism in skip connections for redundancy reduction while enhancing segmentation performance; (2) A fixed-width architecture that prevents exponential parameter growth across network stages; (3) An adaptive feature fusion module achieving enhanced representation with minimal computational overhead. With a record-breaking 16 KB parameter configuration, SimpleUNet outperforms LBUNet and other lightweight benchmarks across multiple public datasets. The 0.67 MB variant achieves superior efficiency (8.60 GFLOPs) and accuracy, attaining a mean DSC/IoU of 85.76%/75.60% on multi-center breast lesion datasets, surpassing both U-Net and TransUNet. Evaluations on skin lesion datasets (ISIC 2017/2018: mDice 84.86%/88.77%) and endoscopic polyp segmentation (KVASIR-SEG: 86.46%/76.48% mDice/mIoU) confirm consistent dominance over state-of-the-art models. This work demonstrates that extreme model compression need not compromise performance, providing new insights for efficient and accurate medical image segmentation. Codes can be found at https://github.com/Frankyu5666666/SimpleUNet.
Cybersecurity Entity Alignment via Masked Graph Attention Networks
Jul 04, 2022
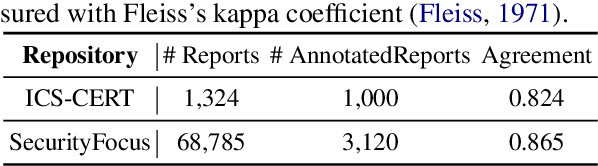
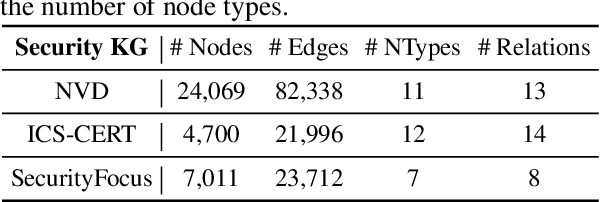
Cybersecurity vulnerability information is often recorded by multiple channels, including government vulnerability repositories, individual-maintained vulnerability-gathering platforms, or vulnerability-disclosure email lists and forums. Integrating vulnerability information from different channels enables comprehensive threat assessment and quick deployment to various security mechanisms. Efforts to automatically gather such information, however, are impeded by the limitations of today's entity alignment techniques. In our study, we annotate the first cybersecurity-domain entity alignment dataset and reveal the unique characteristics of security entities. Based on these observations, we propose the first cybersecurity entity alignment model, CEAM, which equips GNN-based entity alignment with two mechanisms: asymmetric masked aggregation and partitioned attention. Experimental results on cybersecurity-domain entity alignment datasets demonstrate that CEAM significantly outperforms state-of-the-art entity alignment methods.
Learning Security Classifiers with Verified Global Robustness Properties
May 24, 2021
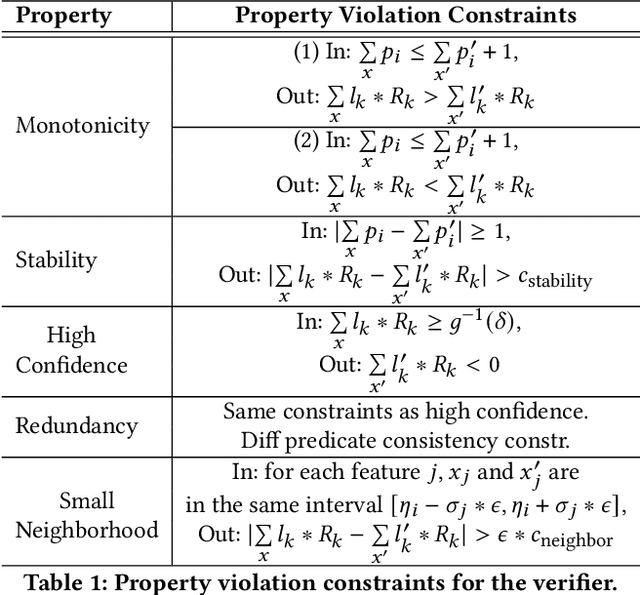

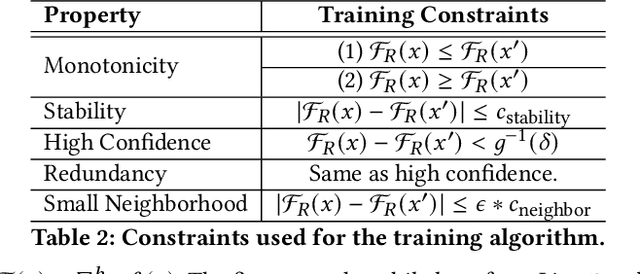
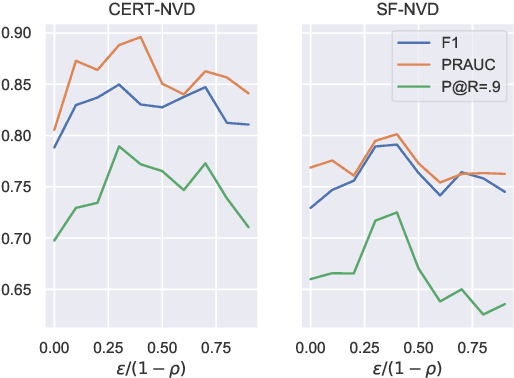
Recent works have proposed methods to train classifiers with local robustness properties, which can provably eliminate classes of evasion attacks for most inputs, but not all inputs. Since data distribution shift is very common in security applications, e.g., often observed for malware detection, local robustness cannot guarantee that the property holds for unseen inputs at the time of deploying the classifier. Therefore, it is more desirable to enforce global robustness properties that hold for all inputs, which is strictly stronger than local robustness. In this paper, we present a framework and tools for training classifiers that satisfy global robustness properties. We define new notions of global robustness that are more suitable for security classifiers. We design a novel booster-fixer training framework to enforce global robustness properties. We structure our classifier as an ensemble of logic rules and design a new verifier to verify the properties. In our training algorithm, the booster increases the classifier's capacity, and the fixer enforces verified global robustness properties following counterexample guided inductive synthesis. To the best of our knowledge, the only global robustness property that has been previously achieved is monotonicity. Several previous works have defined global robustness properties, but their training techniques failed to achieve verified global robustness. In comparison, we show that we can train classifiers to satisfy different global robustness properties for three security datasets, and even multiple properties at the same time, with modest impact on the classifier's performance. For example, we train a Twitter spam account classifier to satisfy five global robustness properties, with 5.4% decrease in true positive rate, and 0.1% increase in false positive rate, compared to a baseline XGBoost model that doesn't satisfy any property.
Otem&Utem: Over- and Under-Translation Evaluation Metric for NMT
Jul 24, 2018

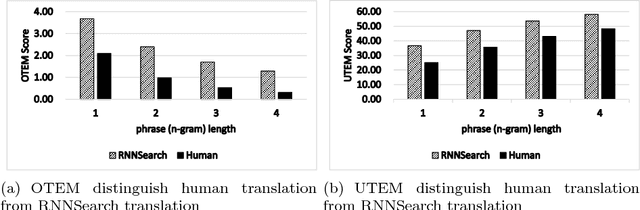

Although neural machine translation(NMT) yields promising translation performance, it unfortunately suffers from over- and under-translation is- sues [Tu et al., 2016], of which studies have become research hotspots in NMT. At present, these studies mainly apply the dominant automatic evaluation metrics, such as BLEU, to evaluate the overall translation quality with respect to both adequacy and uency. However, they are unable to accurately measure the ability of NMT systems in dealing with the above-mentioned issues. In this paper, we propose two quantitative metrics, the Otem and Utem, to automatically evaluate the system perfor- mance in terms of over- and under-translation respectively. Both metrics are based on the proportion of mismatched n-grams between gold ref- erence and system translation. We evaluate both metrics by comparing their scores with human evaluations, where the values of Pearson Cor- relation Coefficient reveal their strong correlation. Moreover, in-depth analyses on various translation systems indicate some inconsistency be- tween BLEU and our proposed metrics, highlighting the necessity and significance of our metrics.
Asynchronous Bidirectional Decoding for Neural Machine Translation
Feb 03, 2018
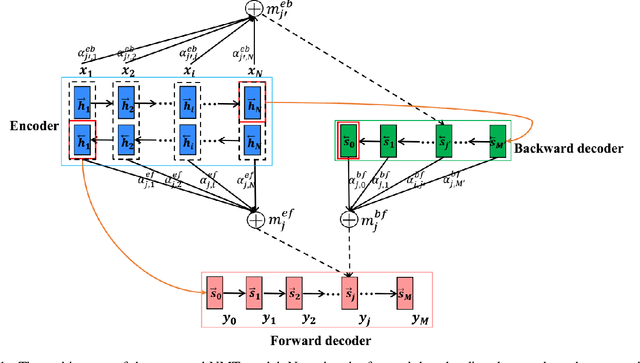
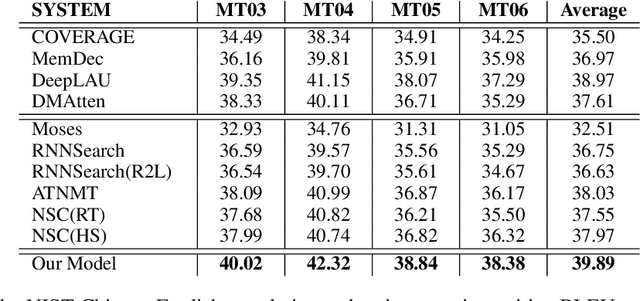
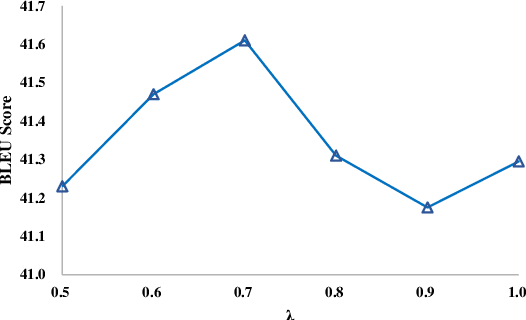
The dominant neural machine translation (NMT) models apply unified attentional encoder-decoder neural networks for translation. Traditionally, the NMT decoders adopt recurrent neural networks (RNNs) to perform translation in a left-toright manner, leaving the target-side contexts generated from right to left unexploited during translation. In this paper, we equip the conventional attentional encoder-decoder NMT framework with a backward decoder, in order to explore bidirectional decoding for NMT. Attending to the hidden state sequence produced by the encoder, our backward decoder first learns to generate the target-side hidden state sequence from right to left. Then, the forward decoder performs translation in the forward direction, while in each translation prediction timestep, it simultaneously applies two attention models to consider the source-side and reverse target-side hidden states, respectively. With this new architecture, our model is able to fully exploit source- and target-side contexts to improve translation quality altogether. Experimental results on NIST Chinese-English and WMT English-German translation tasks demonstrate that our model achieves substantial improvements over the conventional NMT by 3.14 and 1.38 BLEU points, respectively. The source code of this work can be obtained from https://github.com/DeepLearnXMU/ABDNMT.