 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple is what you need for efficient and accurate medical image segmentation
Jun 16, 2025While modern segmentation models often prioritize performance over practicality, we advocate a design philosophy prioritizing simplicity and efficiency, and attempted high performance segmentation model design. This paper presents SimpleUNet, a scalable ultra-lightweight medical image segmentation model with three key innovations: (1) A partial feature selection mechanism in skip connections for redundancy reduction while enhancing segmentation performance; (2) A fixed-width architecture that prevents exponential parameter growth across network stages; (3) An adaptive feature fusion module achieving enhanced representation with minimal computational overhead. With a record-breaking 16 KB parameter configuration, SimpleUNet outperforms LBUNet and other lightweight benchmarks across multiple public datasets. The 0.67 MB variant achieves superior efficiency (8.60 GFLOPs) and accuracy, attaining a mean DSC/IoU of 85.76%/75.60% on multi-center breast lesion datasets, surpassing both U-Net and TransUNet. Evaluations on skin lesion datasets (ISIC 2017/2018: mDice 84.86%/88.77%) and endoscopic polyp segmentation (KVASIR-SEG: 86.46%/76.48% mDice/mIoU) confirm consistent dominance over state-of-the-art models. This work demonstrates that extreme model compression need not compromise performance, providing new insights for efficient and accurate medical image segmentation. Codes can be found at https://github.com/Frankyu5666666/SimpleUNet.
LLM-ABBA: Understanding time series via symbolic approximation
Dec 03, 2024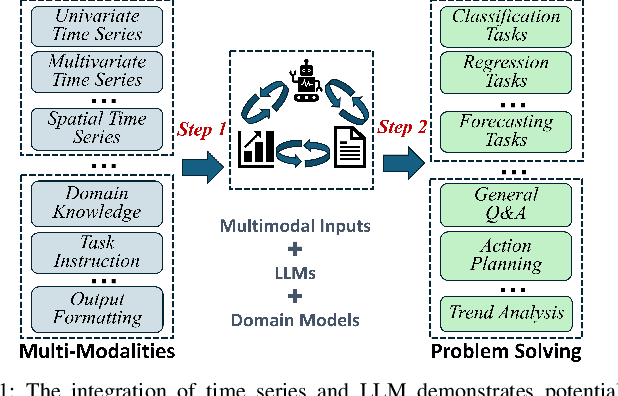
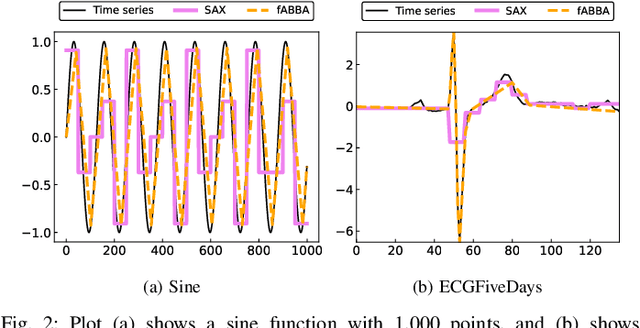
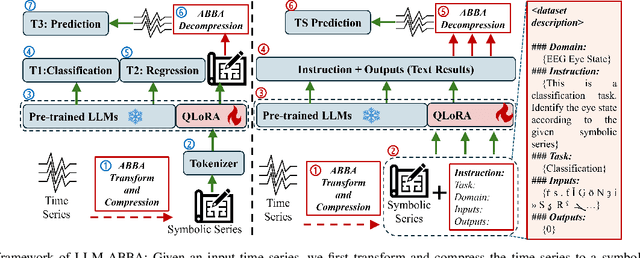
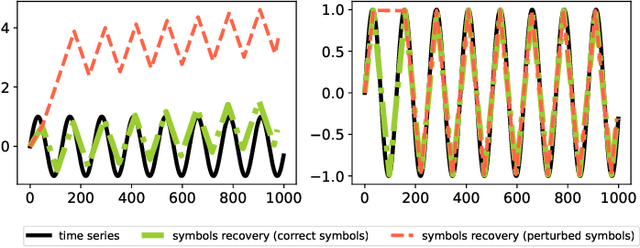
The success of large language models (LLMs) for time series has been demonstrated in previous work. Utilizing a symbolic time series representation, one can efficiently bridge the gap between LLMs and time series. However, the remaining challenge is to exploit the semantic information hidden in time series by using symbols or existing tokens of LLMs, while aligning the embedding space of LLMs according to the hidden information of time series. The symbolic time series approximation (STSA) method called adaptive Brownian bridge-based symbolic aggregation (ABBA) shows outstanding efficacy in preserving salient time series features by modeling time series patterns in terms of amplitude and period while using existing tokens of LLMs. In this paper, we introduce a method, called LLM-ABBA, that integrates ABBA into large language models for various downstream time series tasks. By symbolizing time series, LLM-ABBA compares favorably to the recent state-of-the-art (SOTA) in UCR and three medical time series classification tasks. Meanwhile, a fixed-polygonal chain trick in ABBA is introduced to \kc{avoid obvious drifting} during prediction tasks by significantly mitigating the effects of cumulative error arising from misused symbols during the transition from symbols to numerical values. In time series regression tasks, LLM-ABBA achieves the new SOTA on Time Series Extrinsic Regression (TSER) benchmarks. LLM-ABBA also shows competitive prediction capability compared to recent SOTA time series prediction results. We believe this framework can also seamlessly extend to other time series tasks.
Quantized symbolic time series approximation
Nov 20, 2024Time series are ubiquitous in numerous science and engineering domains, e.g., signal processing, bioinformatics, and astronomy. Previous work has verified the efficacy of symbolic time series representation in a variety of engineering applications due to its storage efficiency and numerosity reduction. The most recent symbolic aggregate approximation technique, ABBA, has been shown to preserve essential shape information of time series and improve downstream applications, e.g., neural network inference regarding prediction and anomaly detection in time series. Motivated by the emergence of high-performance hardware which enables efficient computation for low bit-width representations, we present a new quantization-based ABBA symbolic approximation technique, QABBA, which exhibits improved storage efficiency while retaining the original speed and accuracy of symbolic reconstruction. We prove an upper bound for the error arising from quantization and discuss how the number of bits should be chosen to balance this with other errors. An application of QABBA with large language models (LLMs) for time series regression is also presented, and its utility is investigated. By representing the symbolic chain of patterns on time series, QABBA not only avoids the training of embedding from scratch, but also achieves a new state-of-the-art on Monash regression dataset. The symbolic approximation to the time series offers a more efficient way to fine-tune LLMs on the time series regression task which contains various application domains. We further present a set of extensive experiments performed across various well-established datasets to demonstrate the advantages of the QABBA method for symbolic approximation.
Domain-Specific Improvement on Psychotherapy Chatbot Using Assistant
Apr 24, 2024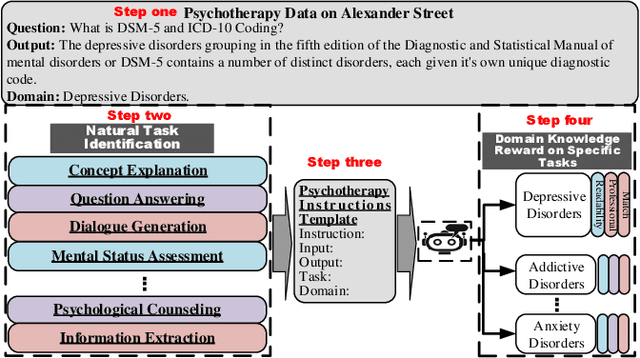
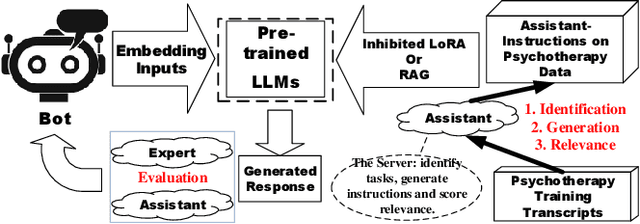


Large language models (LLMs) have demonstrated impressive generalization capabilities on specific tasks with human-written instruction data. However, the limited quantity, diversity, and professional expertise of such instruction data raise concerns about the performance of LLMs in psychotherapy tasks when provided with domain-specific instructions. To address this, we firstly propose Domain-Specific Assistant Instructions based on AlexanderStreet therapy, and secondly, we use an adaption fine-tuning method and retrieval augmented generation method to improve pre-trained LLMs. Through quantitative evaluation of linguistic quality using automatic and human evaluation, we observe that pre-trained LLMs on Psychotherapy Assistant Instructions outperform state-of-the-art LLMs response baselines. Our Assistant-Instruction approach offers a half-annotation method to align pre-trained LLMs with instructions and provide pre-trained LLMs with more psychotherapy knowledge.
Quantized Embedding Vectors for Controllable Diffusion Language Models
Feb 15, 2024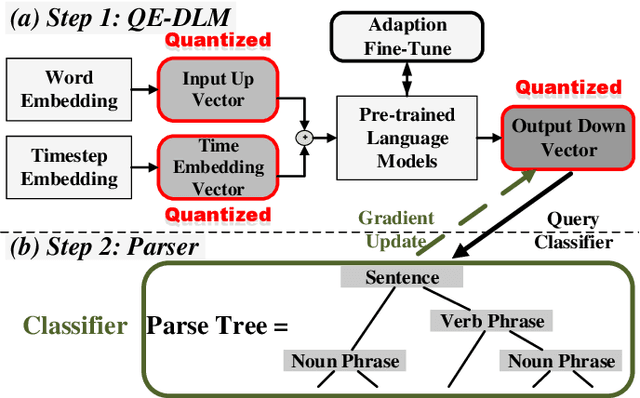

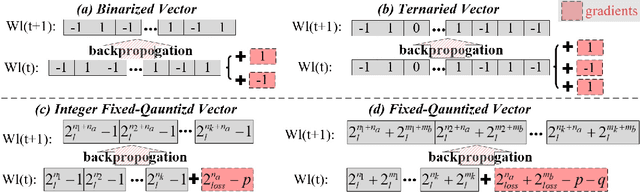
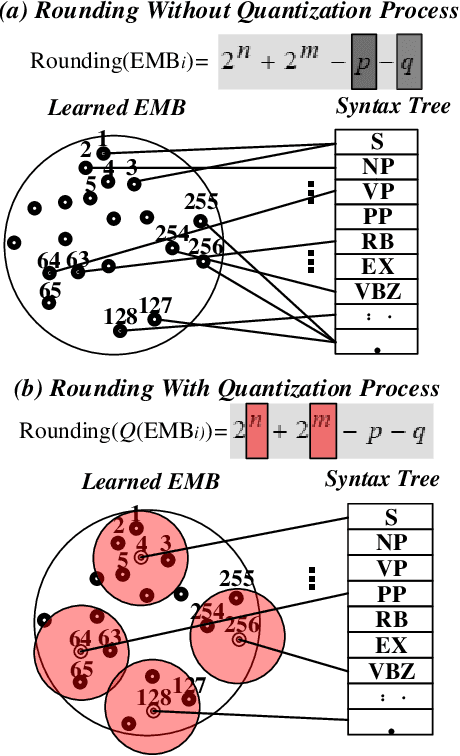
Improving the controllability, portability, and inference speed of diffusion language models (DLMs) is a key challenge in natural language generation. While recent research has shown significant success in complex text generation with language models, the memory and computational power are still very demanding and fall short of expectations, which naturally results in low portability and instability for the models. To mitigate these issues, numerous well-established methods were proposed for neural network quantization. To further enhance their portability of independent deployment as well as improve their stability evaluated by language perplexity, we propose a novel approach called the Quantized Embedding Controllable Diffusion Language Model (QE-CDLM). QE-CDLM builds upon the recent successful controllable DLMs by remodeling the task-specific embedding space via quantization. This leads to a gradient-based controller for the generation tasks, and more stable intermediate latent variables are obtained, which naturally brings in an accelerated convergence as well as better controllability. Additionally, the adaption fine-tuning method is employed to reduce tunable weights. Experimental results on five challenging fine-grained control tasks demonstrate that QE-CDLM compares favorably to existing methods in terms of quality and feasibility, achieving better perplexity and lightweight fine-tuning.
Based on What We Can Control Artificial Neural Networks
Oct 09, 2023How can the stability and efficiency of Artificial Neural Networks (ANNs) be ensured through a systematic analysis method? This paper seeks to address that query. While numerous factors can influence the learning process of ANNs, utilizing knowledge from control systems allows us to analyze its system function and simulate system responses. Although the complexity of most ANNs is extremely high, we still can analyze each factor (e.g., optimiser, hyperparameters) by simulating their system response. This new method also can potentially benefit the development of new optimiser and learning system, especially when discerning which components adversely affect ANNs. Controlling ANNs can benefit from the design of optimiser and learning system, as (1) all optimisers act as controllers, (2) all learning systems operate as control systems with inputs and outputs, and (3) the optimiser should match the learning system. Please find codes: \url{https://github.com/RandomUserName2023/Control-ANNs}.
giMLPs: Gate with Inhibition Mechanism in MLPs
Aug 02, 2022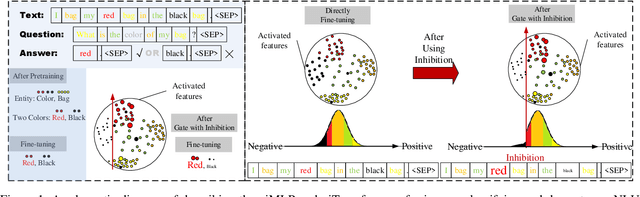
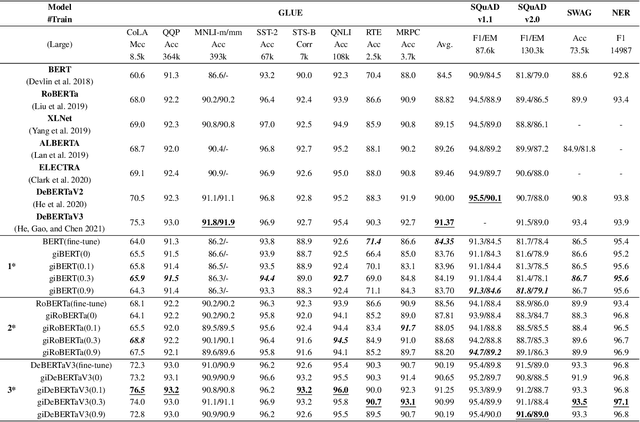
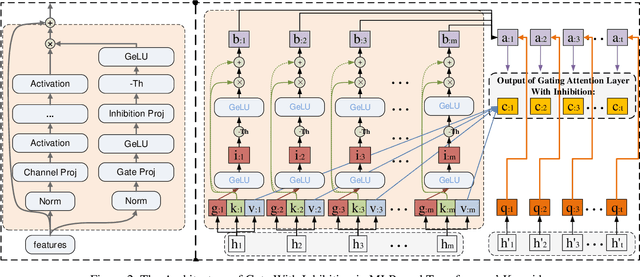
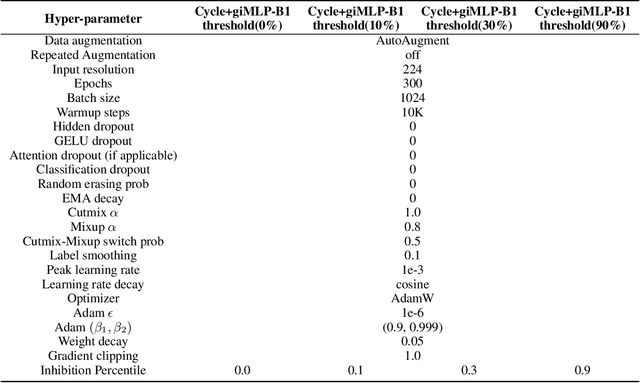
This paper presents a new model architecture, gate with inhibition MLP (giMLP).The gate with inhibition on CycleMLP (gi-CycleMLP) can produce equal performance on the ImageNet classification task, and it also improves the BERT, Roberta, and DeBERTaV3 models depending on two novel techniques. The first is the gating MLP, where matrix multiplications between the MLP and the trunk Attention input in further adjust models' adaptation. The second is inhibition which inhibits or enhances the branch adjustment, and with the inhibition levels increasing, it offers models more muscular features restriction. We show that the giCycleMLP with a lower inhibition level can be competitive with the original CycleMLP in terms of ImageNet classification accuracy. In addition, we also show through a comprehensive empirical study that these techniques significantly improve the performance of fine-tuning NLU downstream tasks. As for the gate with inhibition MLPs on DeBERTa (giDeBERTa) fine-tuning, we find it can achieve appealing results on most parts of NLU tasks without any extra pretraining again. We also find that with the use of Gate With Inhibition, the activation function should have a short and smooth negative tail, with which the unimportant features or the features that hurt models can be moderately inhibited. The experiments on ImageNet and twelve language downstream tasks demonstrate the effectiveness of Gate With Inhibition, both for image classification and for enhancing the capacity of nature language fine-tuning without any extra pretraining.