 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-ABBA: Understanding time series via symbolic approximation
Paper and Code
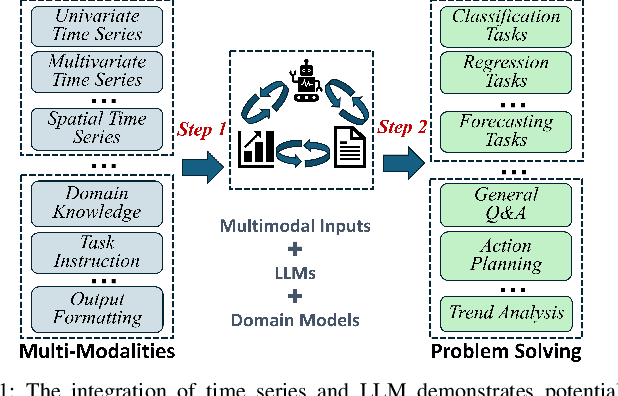
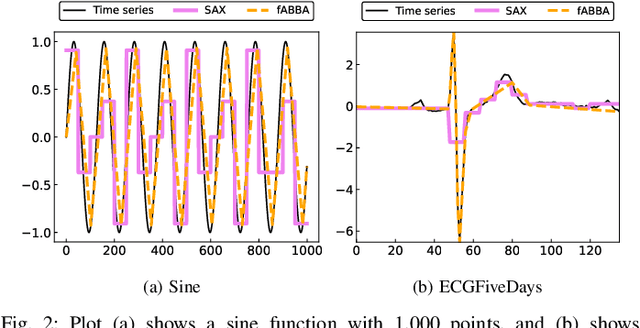
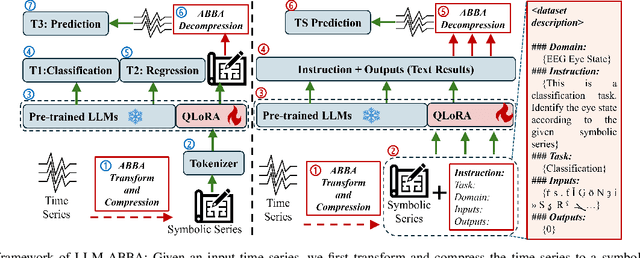
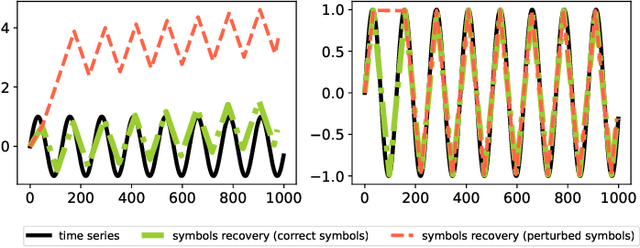
The success of large language models (LLMs) for time series has been demonstrated in previous work. Utilizing a symbolic time series representation, one can efficiently bridge the gap between LLMs and time series. However, the remaining challenge is to exploit the semantic information hidden in time series by using symbols or existing tokens of LLMs, while aligning the embedding space of LLMs according to the hidden information of time series. The symbolic time series approximation (STSA) method called adaptive Brownian bridge-based symbolic aggregation (ABBA) shows outstanding efficacy in preserving salient time series features by modeling time series patterns in terms of amplitude and period while using existing tokens of LLMs. In this paper, we introduce a method, called LLM-ABBA, that integrates ABBA into large language models for various downstream time series tasks. By symbolizing time series, LLM-ABBA compares favorably to the recent state-of-the-art (SOTA) in UCR and three medical time series classification tasks. Meanwhile, a fixed-polygonal chain trick in ABBA is introduced to \kc{avoid obvious drifting} during prediction tasks by significantly mitigating the effects of cumulative error arising from misused symbols during the transition from symbols to numerical values. In time series regression tasks, LLM-ABBA achieves the new SOTA on Time Series Extrinsic Regression (TSER) benchmarks. LLM-ABBA also shows competitive prediction capability compared to recent SOTA time series prediction results. We believe this framework can also seamlessly extend to other time series tasks.