 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecision Autotuning for Linear Solvers via Reinforcement Learning
Jan 05, 2026We propose a reinforcement learning (RL) framework for adaptive precision tuning of linear solvers, and can be extended to general algorithms. The framework is formulated as a contextual bandit problem and solved using incremental action-value estimation with a discretized state space to select optimal precision configurations for computational steps, balancing precision and computational efficiency. To verify its effectiveness, we apply the framework to iterative refinement for solving linear systems $Ax = b$. In this application, our approach dynamically chooses precisions based on calculated features from the system. In detail, a Q-table maps discretized features (e.g., approximate condition number and matrix norm)to actions (chosen precision configurations for specific steps), optimized via an epsilon-greedy strategy to maximize a multi-objective reward balancing accuracy and computational cost. Empirical results demonstrate effective precision selection, reducing computational cost while maintaining accuracy comparable to double-precision baselines. The framework generalizes to diverse out-of-sample data and offers insight into utilizing RL precision selection for other numerical algorithms, advancing mixed-precision numerical methods in scientific computing. To the best of our knowledge, this is the first work on precision autotuning with RL and verified on unseen datasets.
Pychop: Emulating Low-Precision Arithmetic in Numerical Methods and Neural Networks
Apr 10, 2025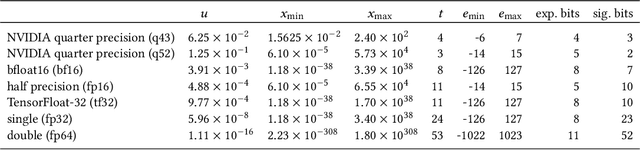
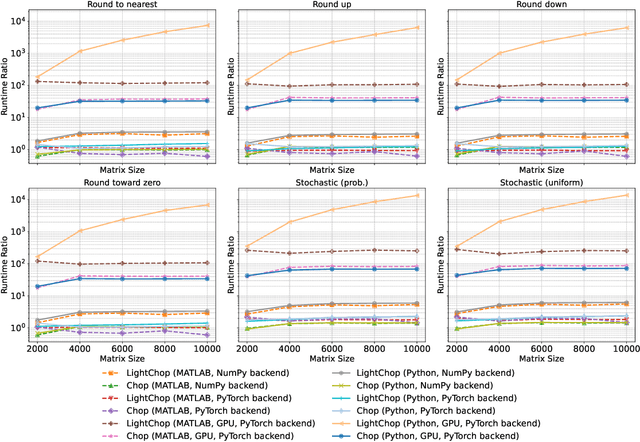
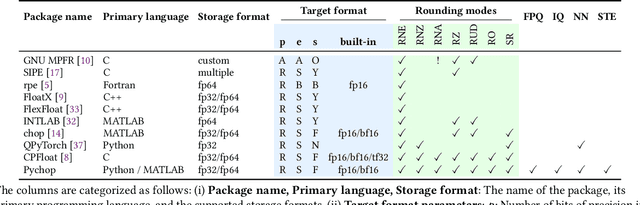
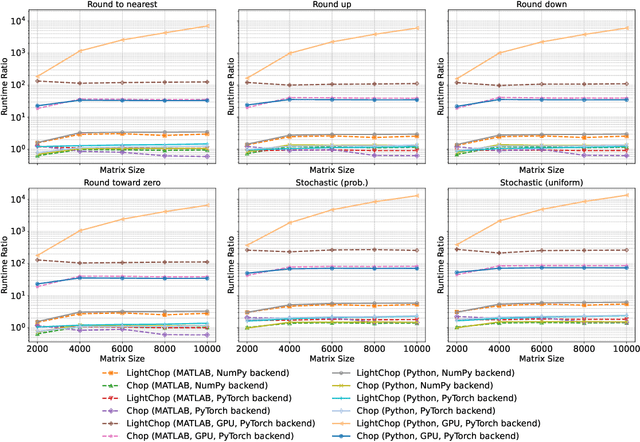
Motivated by the growing demand for low-precision arithmetic in computational science, we exploit lower-precision emulation in Python -- widely regarded as the dominant programming language for numerical analysis and machine learning. Low-precision training has revolutionized deep learning by enabling more efficient computation and reduced memory and energy consumption while maintaining model fidelity. To better enable numerical experimentation with and exploration of low precision computation, we developed the Pychop library, which supports customizable floating-point formats and a comprehensive set of rounding modes in Python, allowing users to benefit from fast, low-precision emulation in numerous applications. Pychop also introduces interfaces for both PyTorch and JAX, enabling efficient low-precision emulation on GPUs for neural network training and inference with unparalleled flexibility. In this paper, we offer a comprehensive exposition of the design, implementation, validation, and practical application of Pychop, establishing it as a foundational tool for advancing efficient mixed-precision algorithms. Furthermore, we present empirical results on low-precision emulation for image classification and object detection using published datasets, illustrating the sensitivity of the use of low precision and offering valuable insights into its impact. Pychop enables in-depth investigations into the effects of numerical precision, facilitates the development of novel hardware accelerators, and integrates seamlessly into existing deep learning workflows. Software and experimental code are publicly available at https://github.com/inEXASCALE/pychop.
LLM-ABBA: Understanding time series via symbolic approximation
Dec 03, 2024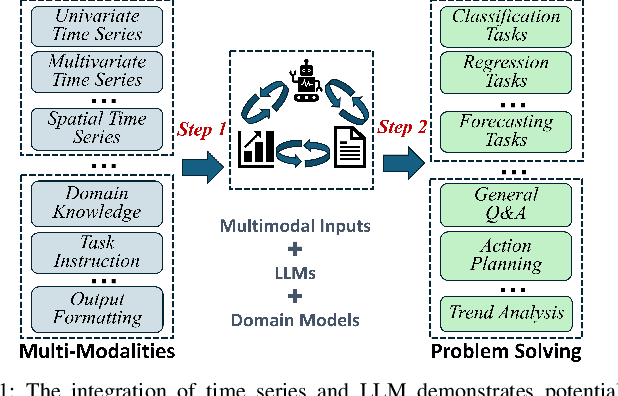
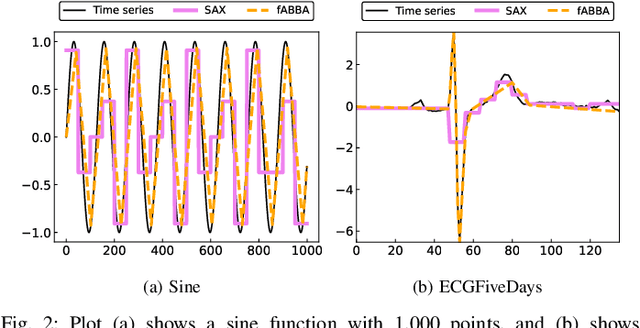
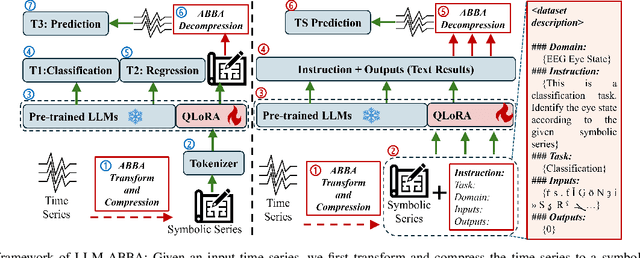
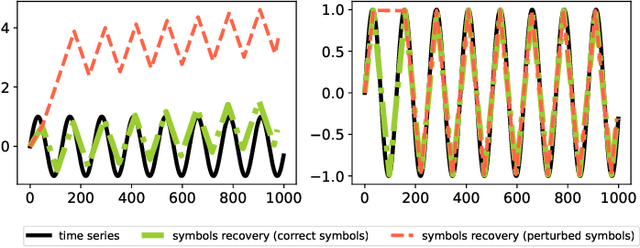
The success of large language models (LLMs) for time series has been demonstrated in previous work. Utilizing a symbolic time series representation, one can efficiently bridge the gap between LLMs and time series. However, the remaining challenge is to exploit the semantic information hidden in time series by using symbols or existing tokens of LLMs, while aligning the embedding space of LLMs according to the hidden information of time series. The symbolic time series approximation (STSA) method called adaptive Brownian bridge-based symbolic aggregation (ABBA) shows outstanding efficacy in preserving salient time series features by modeling time series patterns in terms of amplitude and period while using existing tokens of LLMs. In this paper, we introduce a method, called LLM-ABBA, that integrates ABBA into large language models for various downstream time series tasks. By symbolizing time series, LLM-ABBA compares favorably to the recent state-of-the-art (SOTA) in UCR and three medical time series classification tasks. Meanwhile, a fixed-polygonal chain trick in ABBA is introduced to \kc{avoid obvious drifting} during prediction tasks by significantly mitigating the effects of cumulative error arising from misused symbols during the transition from symbols to numerical values. In time series regression tasks, LLM-ABBA achieves the new SOTA on Time Series Extrinsic Regression (TSER) benchmarks. LLM-ABBA also shows competitive prediction capability compared to recent SOTA time series prediction results. We believe this framework can also seamlessly extend to other time series tasks.
Quantized symbolic time series approximation
Nov 20, 2024Time series are ubiquitous in numerous science and engineering domains, e.g., signal processing, bioinformatics, and astronomy. Previous work has verified the efficacy of symbolic time series representation in a variety of engineering applications due to its storage efficiency and numerosity reduction. The most recent symbolic aggregate approximation technique, ABBA, has been shown to preserve essential shape information of time series and improve downstream applications, e.g., neural network inference regarding prediction and anomaly detection in time series. Motivated by the emergence of high-performance hardware which enables efficient computation for low bit-width representations, we present a new quantization-based ABBA symbolic approximation technique, QABBA, which exhibits improved storage efficiency while retaining the original speed and accuracy of symbolic reconstruction. We prove an upper bound for the error arising from quantization and discuss how the number of bits should be chosen to balance this with other errors. An application of QABBA with large language models (LLMs) for time series regression is also presented, and its utility is investigated. By representing the symbolic chain of patterns on time series, QABBA not only avoids the training of embedding from scratch, but also achieves a new state-of-the-art on Monash regression dataset. The symbolic approximation to the time series offers a more efficient way to fine-tune LLMs on the time series regression task which contains various application domains. We further present a set of extensive experiments performed across various well-established datasets to demonstrate the advantages of the QABBA method for symbolic approximation.