 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Bidirectional Decoding for Neural Machine Translation
Paper and Code

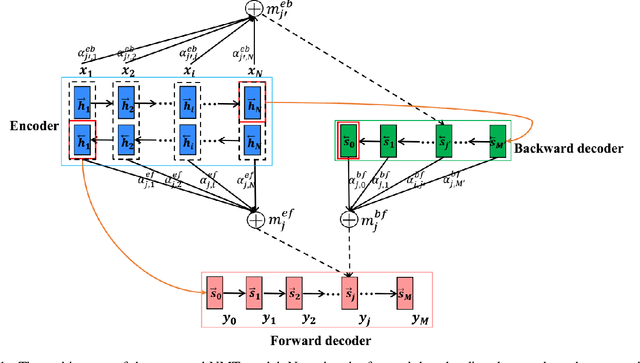
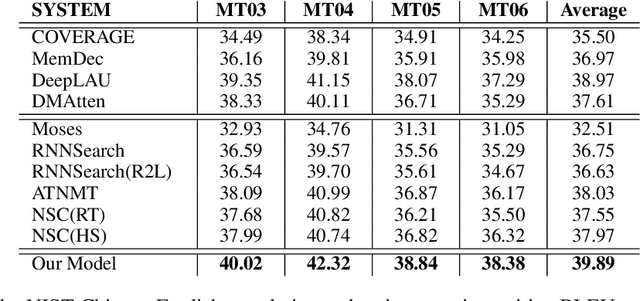
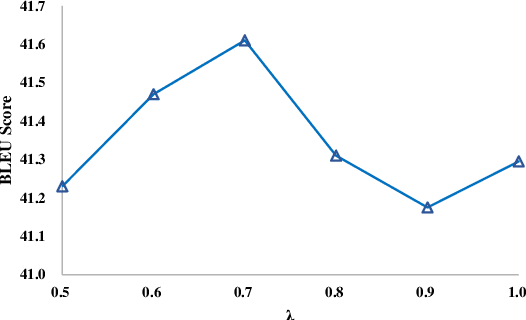
The dominant neural machine translation (NMT) models apply unified attentional encoder-decoder neural networks for translation. Traditionally, the NMT decoders adopt recurrent neural networks (RNNs) to perform translation in a left-toright manner, leaving the target-side contexts generated from right to left unexploited during translation. In this paper, we equip the conventional attentional encoder-decoder NMT framework with a backward decoder, in order to explore bidirectional decoding for NMT. Attending to the hidden state sequence produced by the encoder, our backward decoder first learns to generate the target-side hidden state sequence from right to left. Then, the forward decoder performs translation in the forward direction, while in each translation prediction timestep, it simultaneously applies two attention models to consider the source-side and reverse target-side hidden states, respectively. With this new architecture, our model is able to fully exploit source- and target-side contexts to improve translation quality altogether. Experimental results on NIST Chinese-English and WMT English-German translation tasks demonstrate that our model achieves substantial improvements over the conventional NMT by 3.14 and 1.38 BLEU points, respectively. The source code of this work can be obtained from https://github.com/DeepLearnXMU/ABDNMT.