 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Fusion of 3D Extended Object Tracking based on a B-Spline Shape Model
Apr 25, 2025Extended Object Tracking (EOT) exploits the high resolution of modern sensors for detailed environmental perception. Combined with decentralized fusion, it contributes to a more scalable and robust perception system. This paper investigates the decentralized fusion of 3D EOT using a B-spline curve based model. The spline curve is used to represent the side-view profile, which is then extruded with a width to form a 3D shape. We use covariance intersection (CI) for the decentralized fusion and discuss the challenge of applying it to EOT. We further evaluate the tracking result of the decentralized fusion with simulated and real datasets of traffic scenarios. We show that the CI-based fusion can significantly improve the tracking performance for sensors with unfavorable perspective.
AccidentSim: Generating Physically Realistic Vehicle Collision Videos from Real-World Accident Reports
Mar 26, 2025

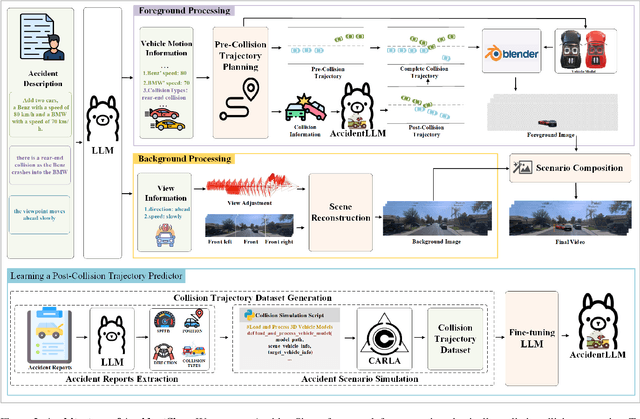

Collecting real-world vehicle accident videos for autonomous driving research is challenging due to their rarity and complexity. While existing driving video generation methods may produce visually realistic videos, they often fail to deliver physically realistic simulations because they lack the capability to generate accurate post-collision trajectories. In this paper, we introduce AccidentSim, a novel framework that generates physically realistic vehicle collision videos by extracting and utilizing the physical clues and contextual information available in real-world vehicle accident reports. Specifically, AccidentSim leverages a reliable physical simulator to replicate post-collision vehicle trajectories from the physical and contextual information in the accident reports and to build a vehicle collision trajectory dataset. This dataset is then used to fine-tune a language model, enabling it to respond to user prompts and predict physically consistent post-collision trajectories across various driving scenarios based on user descriptions. Finally, we employ Neural Radiance Fields (NeRF) to render high-quality backgrounds, merging them with the foreground vehicles that exhibit physically realistic trajectories to generate vehicle collision videos. Experimental results demonstrate that the videos produced by AccidentSim excel in both visual and physical authenticity.
3D Extended Object Tracking based on Extruded B-Spline Side View Profiles
Mar 13, 2025Object tracking is an essential task for autonomous systems. With the advancement of 3D sensors, these systems can better perceive their surroundings using effective 3D Extended Object Tracking (EOT) methods. Based on the observation that common road users are symmetrical on the right and left sides in the traveling direction, we focus on the side view profile of the object. In order to leverage of the development in 2D EOT and balance the number of parameters of a shape model in the tracking algorithms, we propose a method for 3D extended object tracking (EOT) by describing the side view profile of the object with B-spline curves and forming an extrusion to obtain a 3D extent. The use of B-spline curves exploits their flexible representation power by allowing the control points to move freely. The algorithm is developed into an Extended Kalman Filter (EKF). For a through evaluation of this method, we use simulated traffic scenario of different vehicle models and realworld open dataset containing both radar and lidar data.
Retinex-RAWMamba: Bridging Demosaicing and Denoising for Low-Light RAW Image Enhancement
Sep 11, 2024



Low-light image enhancement, particularly in cross-domain tasks such as mapping from the raw domain to the sRGB domain, remains a significant challenge. Many deep learning-based methods have been developed to address this issue and have shown promising results in recent years. However, single-stage methods, which attempt to unify the complex mapping across both domains, leading to limited denoising performance. In contrast, two-stage approaches typically decompose a raw image with color filter arrays (CFA) into a four-channel RGGB format before feeding it into a neural network. However, this strategy overlooks the critical role of demosaicing within the Image Signal Processing (ISP) pipeline, leading to color distortions under varying lighting conditions, especially in low-light scenarios. To address these issues, we design a novel Mamba scanning mechanism, called RAWMamba, to effectively handle raw images with different CFAs. Furthermore, we present a Retinex Decomposition Module (RDM) grounded in Retinex prior, which decouples illumination from reflectance to facilitate more effective denoising and automatic non-linear exposure correction. By bridging demosaicing and denoising, better raw image enhancement is achieved. Experimental evaluations conducted on public datasets SID and MCR demonstrate that our proposed RAWMamba achieves state-of-the-art performance on cross-domain mapping.
Applying Extended Object Tracking for Self-Localization of Roadside Radar Sensors
Jul 03, 2024
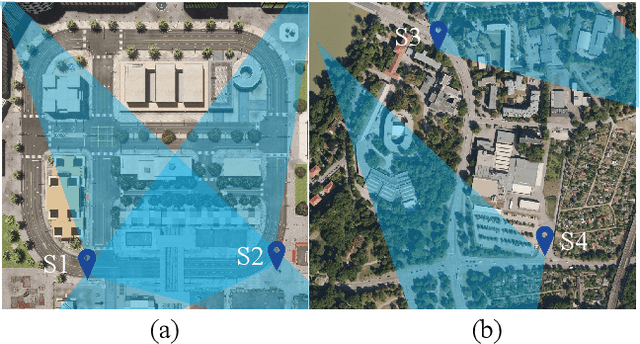
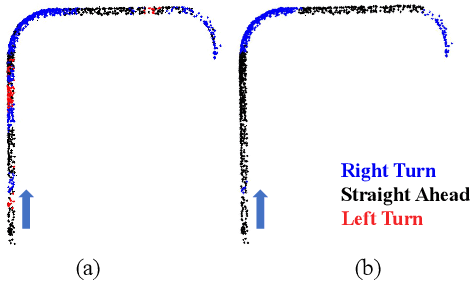

Intelligent Transportation Systems (ITS) can benefit from roadside 4D mmWave radar sensors for large-scale traffic monitoring due to their weatherproof functionality, long sensing range and low manufacturing cost. However, the localization method using external measurement devices has limitations in urban environments. Furthermore, if the sensor mount exhibits changes due to environmental influences, they cannot be corrected when the measurement is performed only during the installation. In this paper, we propose self-localization of roadside radar data using Extended Object Tracking (EOT). The method analyses both the tracked trajectories of the vehicles observed by the sensor and the aerial laser scan of city streets, assigns labels of driving behaviors such as "straight ahead", "left turn", "right turn" to trajectory sections and road segments, and performs Semantic Iterative Closest Points (SICP) algorithm to register the point cloud. The method exploits the result from a down stream task -- object tracking -- for localization. We demonstrate high accuracy in the sub-meter range along with very low orientation error. The method also shows good data efficiency. The evaluation is done in both simulation and real-world tests.
ASPS: Augmented Segment Anything Model for Polyp Segmentation
Jun 30, 2024



Polyp segmentation plays a pivotal role in colorectal cancer diagnosis. Recently, the emergence of the Segment Anything Model (SAM) has introduced unprecedented potential for polyp segmentation, leveraging its powerful pre-training capability on large-scale datasets. However, due to the domain gap between natural and endoscopy images, SAM encounters two limitations in achieving effective performance in polyp segmentation. Firstly, its Transformer-based structure prioritizes global and low-frequency information, potentially overlooking local details, and introducing bias into the learned features. Secondly, when applied to endoscopy images, its poor out-of-distribution (OOD) performance results in substandard predictions and biased confidence output. To tackle these challenges, we introduce a novel approach named Augmented SAM for Polyp Segmentation (ASPS), equipped with two modules: Cross-branch Feature Augmentation (CFA) and Uncertainty-guided Prediction Regularization (UPR). CFA integrates a trainable CNN encoder branch with a frozen ViT encoder, enabling the integration of domain-specific knowledge while enhancing local features and high-frequency details. Moreover, UPR ingeniously leverages SAM's IoU score to mitigate uncertainty during the training procedure, thereby improving OOD performance and domain generalization. Extensive experimental results demonstrate the effectiveness and utility of the proposed method in improving SAM's performance in polyp segmentation. Our code is available at https://github.com/HuiqianLi/ASPS.
Scalable Radar-based ITS: Self-localization and Occupancy Heat Map for Traffic Analysis
Apr 01, 2024



4D mmWave radar sensors are well suited for city scale Intelligent Transportation Systems (ITS) given their long sensing range, weatherproof functionality, simple mechanical design, and low manufacturing cost. In this paper, we investigate radar-based ITS for scalable traffic analysis. Localization of these radar sensors in a city scale range is a fundamental task in ITS. For mobile ITS setups it requires more endeavor. To address this task, we propose a self-localization approach that matches two descriptions of "road": the one from the geometry of the motion trajectories of cumulatively observed vehicles, and the other one from the aerial laser scan. An ICP (iterative closest point) algorithm is used to register the motion trajectory into the road section of the laser scan to estimate the sensor pose. We evaluates the results and show that it outperforms other map-based radar localization methods, especially for the orientation estimation. Beyond the localization result, we project radar sensor data onto city scale laser scan and generate an scalable occupancy heat map as a traffic analysis tool. This is demonstrated using two radar sensors monitoring an urban area in the real world.
Dual Domain-Adversarial Learning for Audio-Visual Saliency Prediction
Aug 16, 2022
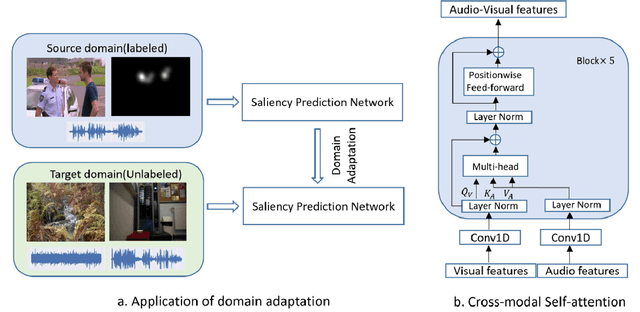
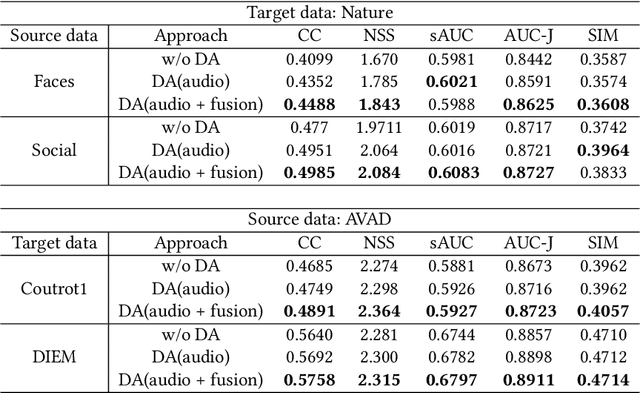
Both visual and auditory information are valuable to determine the salient regions in videos. Deep convolution neural networks (CNN) showcase strong capacity in coping with the audio-visual saliency prediction task. Due to various factors such as shooting scenes and weather, there often exists moderate distribution discrepancy between source training data and target testing data. The domain discrepancy induces to performance degradation on target testing data for CNN models. This paper makes an early attempt to tackle the unsupervised domain adaptation problem for audio-visual saliency prediction. We propose a dual domain-adversarial learning algorithm to mitigate the domain discrepancy between source and target data. First, a specific domain discrimination branch is built up for aligning the auditory feature distributions. Then, those auditory features are fused into the visual features through a cross-modal self-attention module. The other domain discrimination branch is devised to reduce the domain discrepancy of visual features and audio-visual correlations implied by the fused audio-visual features. Experiments on public benchmarks demonstrate that our method can relieve the performance degradation caused by domain discrepancy.
Pixel Distillation: A New Knowledge Distillation Scheme for Low-Resolution Image Recognition
Dec 17, 2021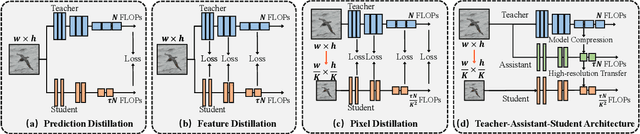
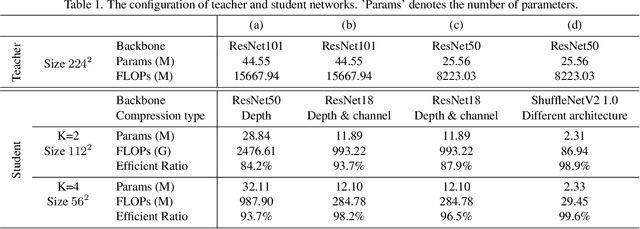
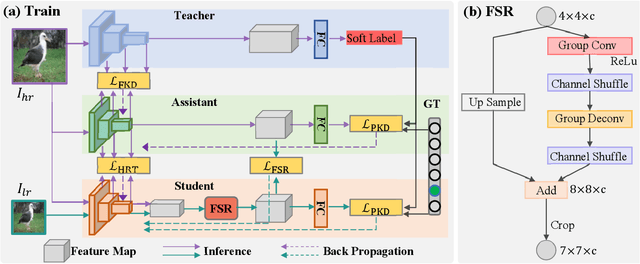
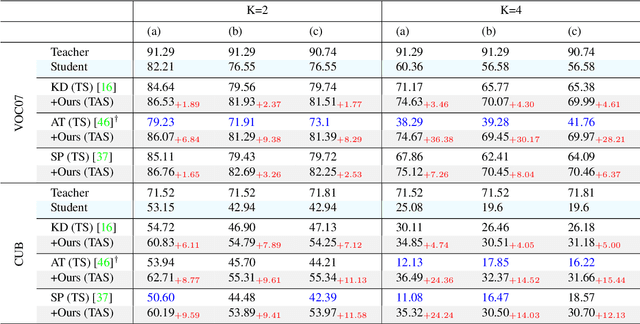
The great success of deep learning is mainly due to the large-scale network architecture and the high-quality training data. However, it is still challenging to deploy recent deep models on portable devices with limited memory and imaging ability. Some existing works have engaged to compress the model via knowledge distillation. Unfortunately, these methods cannot deal with images with reduced image quality, such as the low-resolution (LR) images. To this end, we make a pioneering effort to distill helpful knowledge from a heavy network model learned from high-resolution (HR) images to a compact network model that will handle LR images, thus advancing the current knowledge distillation technique with the novel pixel distillation. To achieve this goal, we propose a Teacher-Assistant-Student (TAS) framework, which disentangles knowledge distillation into the model compression stage and the high resolution representation transfer stage. By equipping a novel Feature Super Resolution (FSR) module, our approach can learn lightweight network model that can achieve similar accuracy as the heavy teacher model but with much fewer parameters, faster inference speed, and lower-resolution inputs. Comprehensive experiments on three widely-used benchmarks, \ie, CUB-200-2011, PASCAL VOC 2007, and ImageNetSub, demonstrate the effectiveness of our approach.