 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetinex-RAWMamba: Bridging Demosaicing and Denoising for Low-Light RAW Image Enhancement
Sep 11, 2024



Low-light image enhancement, particularly in cross-domain tasks such as mapping from the raw domain to the sRGB domain, remains a significant challenge. Many deep learning-based methods have been developed to address this issue and have shown promising results in recent years. However, single-stage methods, which attempt to unify the complex mapping across both domains, leading to limited denoising performance. In contrast, two-stage approaches typically decompose a raw image with color filter arrays (CFA) into a four-channel RGGB format before feeding it into a neural network. However, this strategy overlooks the critical role of demosaicing within the Image Signal Processing (ISP) pipeline, leading to color distortions under varying lighting conditions, especially in low-light scenarios. To address these issues, we design a novel Mamba scanning mechanism, called RAWMamba, to effectively handle raw images with different CFAs. Furthermore, we present a Retinex Decomposition Module (RDM) grounded in Retinex prior, which decouples illumination from reflectance to facilitate more effective denoising and automatic non-linear exposure correction. By bridging demosaicing and denoising, better raw image enhancement is achieved. Experimental evaluations conducted on public datasets SID and MCR demonstrate that our proposed RAWMamba achieves state-of-the-art performance on cross-domain mapping.
Robust Region Feature Synthesizer for Zero-Shot Object Detection
Jan 01, 2022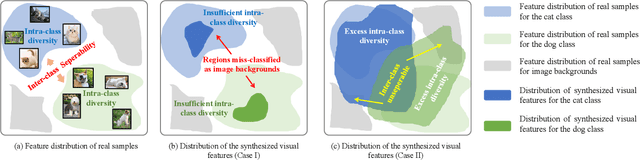
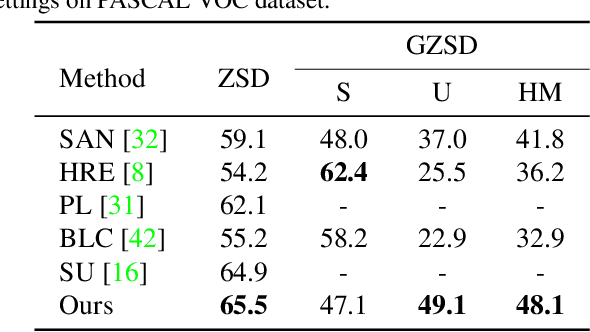
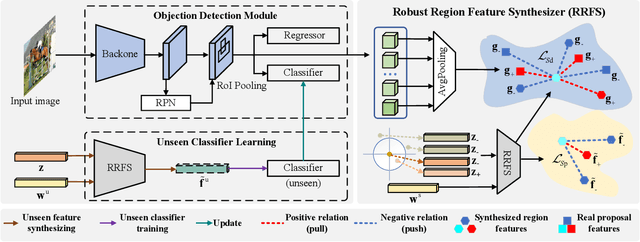
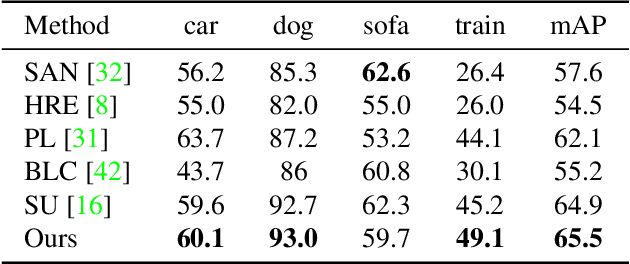
Zero-shot object detection aims at incorporating class semantic vectors to realize the detection of (both seen and) unseen classes given an unconstrained test image. In this study, we reveal the core challenges in this research area: how to synthesize robust region features (for unseen objects) that are as intra-class diverse and inter-class separable as the real samples, so that strong unseen object detectors can be trained upon them. To address these challenges, we build a novel zero-shot object detection framework that contains an Intra-class Semantic Diverging component and an Inter-class Structure Preserving component. The former is used to realize the one-to-more mapping to obtain diverse visual features from each class semantic vector, preventing miss-classifying the real unseen objects as image backgrounds. While the latter is used to avoid the synthesized features too scattered to mix up the inter-class and foreground-background relationship. To demonstrate the effectiveness of the proposed approach, comprehensive experiments on PASCAL VOC, COCO, and DIOR datasets are conducted. Notably, our approach achieves the new state-of-the-art performance on PASCAL VOC and COCO and it is the first study to carry out zero-shot object detection in remote sensing imagery.