 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3-D Relative Localization for Multi-Robot Systems with Angle and Self-Displacement Measurements
Apr 02, 2026Realizing relative localization by leveraging inter-robot local measurements is a challenging problem, especially in the presence of measurement noise. Motivated by this challenge, in this paper we propose a novel and systematic 3-D relative localization framework based on inter-robot interior angle and self-displacement measurements. Initially, we propose a linear relative localization theory comprising a distributed linear relative localization algorithm and sufficient conditions for localizability. According to this theory, robots can determine their neighbors' relative positions and orientations in a purely linear manner. Subsequently, in order to deal with measurement noise, we present an advanced Maximum a Posterior (MAP) estimator by addressing three primary challenges existing in the MAP estimator. Firstly, it is common to formulate the MAP problem as an optimization problem, whose inherent non-convexity can result in local optima. To address this issue, we reformulate the linear computation process of the linear relative localization algorithm as a Weighted Total Least Squares (WTLS) optimization problem on manifolds. The optimal solution of the WTLS problem is more accurate, which can then be used as initial values when solving the optimization problem associated with the MAP problem, thereby reducing the risk of falling into local optima. The second challenge is the lack of knowledge of the prior probability density of the robots' relative positions and orientations at the initial time, which is required as an input for the MAP estimator. To deal with it, we combine the WTLS with a Neural Density Estimator (NDE). Thirdly, to prevent the increasing size of the relative positions and orientations to be estimated as the robots continuously move when solving the MAP problem, a marginalization mechanism is designed, which ensures that the computational cost remains constant.
* 29 pages, 28 figures
A Method for Enhancing Generalization of Adam by Multiple Integrations
Dec 17, 2024



The insufficient generalization of adaptive moment estimation (Adam) has hindered its broader application. Recent studies have shown that flat minima in loss landscapes are highly associated with improved generalization. Inspired by the filtering effect of integration operations on high-frequency signals, we propose multiple integral Adam (MIAdam), a novel optimizer that integrates a multiple integral term into Adam. This multiple integral term effectively filters out sharp minima encountered during optimization, guiding the optimizer towards flatter regions and thereby enhancing generalization capability. We provide a theoretical explanation for the improvement in generalization through the diffusion theory framework and analyze the impact of the multiple integral term on the optimizer's convergence. Experimental results demonstrate that MIAdam not only enhances generalization and robustness against label noise but also maintains the rapid convergence characteristic of Adam, outperforming Adam and its variants in state-of-the-art benchmarks.
Zero Stability Well Predicts Performance of Convolutional Neural Networks
Jun 27, 2022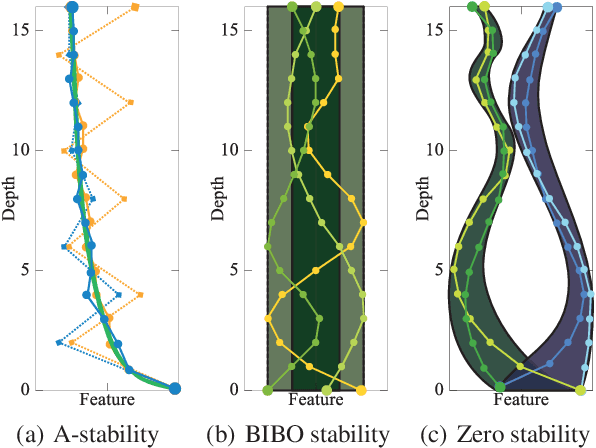
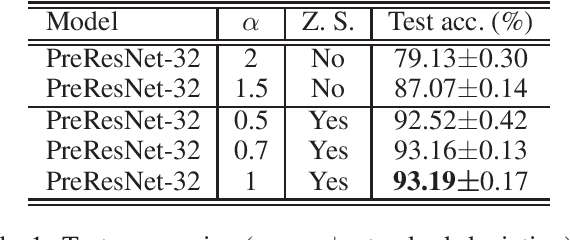
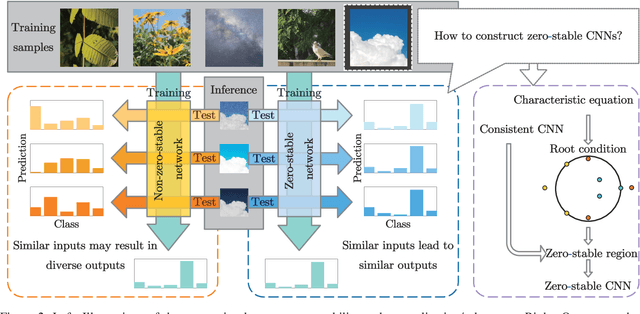
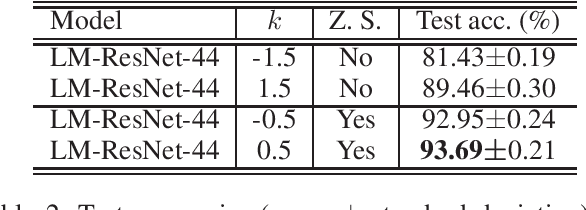
The question of what kind of convolutional neural network (CNN) structure performs well is fascinating. In this work, we move toward the answer with one more step by connecting zero stability and model performance. Specifically, we found that if a discrete solver of an ordinary differential equation is zero stable, the CNN corresponding to that solver performs well. We first give the interpretation of zero stability in the context of deep learning and then investigate the performance of existing first- and second-order CNNs under different zero-stable circumstances. Based on the preliminary observation, we provide a higher-order discretization to construct CNNs and then propose a zero-stable network (ZeroSNet). To guarantee zero stability of the ZeroSNet, we first deduce a structure that meets consistency conditions and then give a zero stable region of a training-free parameter. By analyzing the roots of a characteristic equation, we theoretically obtain the optimal coefficients of feature maps. Empirically, we present our results from three aspects: We provide extensive empirical evidence of different depth on different datasets to show that the moduli of the characteristic equation's roots are the keys for the performance of CNNs that require historical features; Our experiments show that ZeroSNet outperforms existing CNNs which is based on high-order discretization; ZeroSNets show better robustness against noises on the input. The source code is available at \url{https://github.com/LongJin-lab/ZeroSNet}.
Activated Gradients for Deep Neural Networks
Jul 09, 2021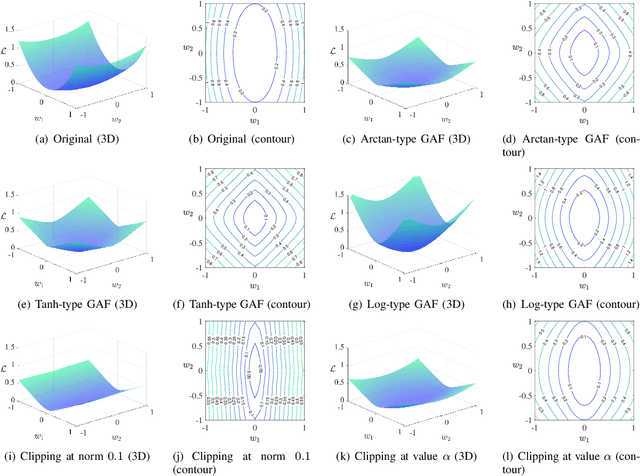
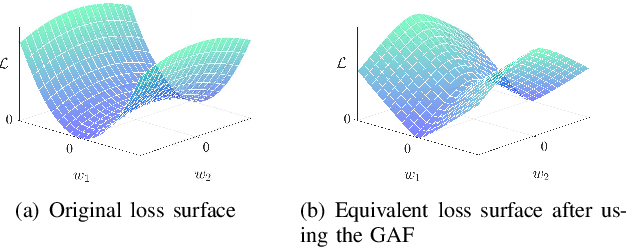
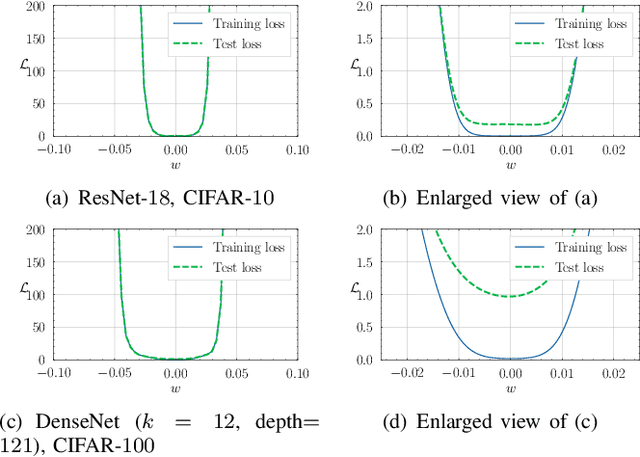
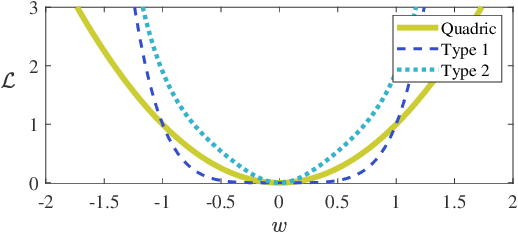
Deep neural networks often suffer from poor performance or even training failure due to the ill-conditioned problem, the vanishing/exploding gradient problem, and the saddle point problem. In this paper, a novel method by acting the gradient activation function (GAF) on the gradient is proposed to handle these challenges. Intuitively, the GAF enlarges the tiny gradients and restricts the large gradient. Theoretically, this paper gives conditions that the GAF needs to meet, and on this basis, proves that the GAF alleviates the problems mentioned above. In addition, this paper proves that the convergence rate of SGD with the GAF is faster than that without the GAF under some assumptions. Furthermore, experiments on CIFAR, ImageNet, and PASCAL visual object classes confirm the GAF's effectiveness. The experimental results also demonstrate that the proposed method is able to be adopted in various deep neural networks to improve their performance. The source code is publicly available at https://github.com/LongJin-lab/Activated-Gradients-for-Deep-Neural-Networks.
Deforming the Loss Surface to Affect the Behaviour of the Optimizer
Sep 14, 2020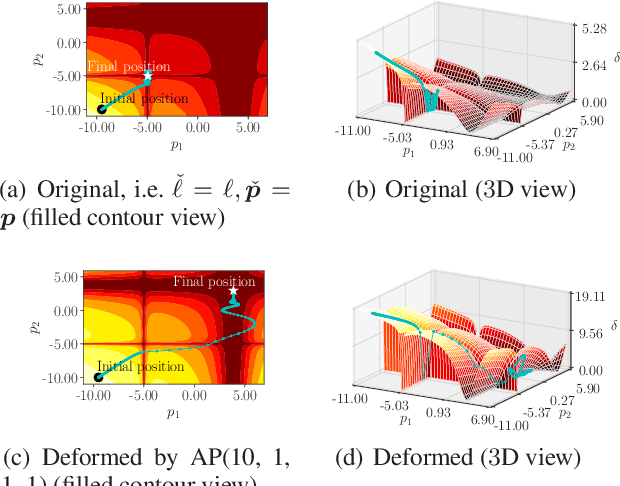
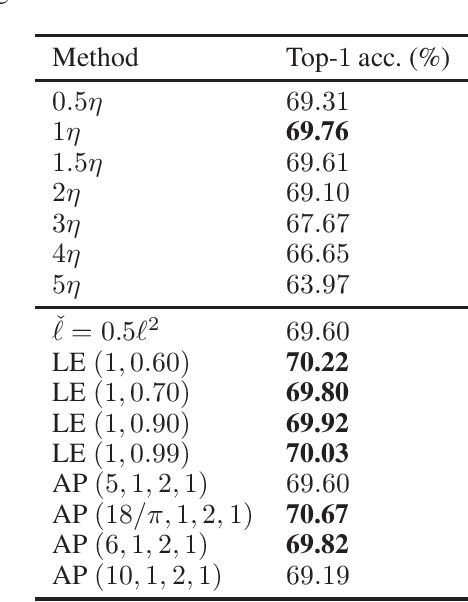


In deep learning, it is usually assumed that the optimization process is conducted on a shape-fixed loss surface. Differently, we first propose a novel concept of deformation mapping in this paper to affect the behaviour of the optimizer. Vertical deformation mapping (VDM), as a type of deformation mapping, can make the optimizer enter a flat region, which often implies better generalization performance. Moreover, we design various VDMs, and further provide their contributions to the loss surface. After defining the local M region, theoretical analyses show that deforming the loss surface can enhance the gradient descent optimizer's ability to filter out sharp minima. With visualizations of loss landscapes, we evaluate the flatnesses of minima obtained by both the original optimizer and optimizers enhanced by VDMs on CIFAR-100. The experimental results show that VDMs do find flatter regions. Moreover, we compare popular convolutional neural networks enhanced by VDMs with the corresponding original ones on ImageNet, CIFAR-10, and CIFAR-100. The results are surprising: there are significant improvements on all of the involved models equipped with VDMs. For example, the top-1 test accuracy of ResNet-20 on CIFAR-100 increases by 1.46%, with insignificant additional computational overhead.
Deforming the Loss Surface
Jul 24, 2020



In deep learning, it is usually assumed that the shape of the loss surface is fixed. Differently, a novel concept of deformation operator is first proposed in this paper to deform the loss surface, thereby improving the optimization. Deformation function, as a type of deformation operator, can improve the generalization performance. Moreover, various deformation functions are designed, and their contributions to the loss surface are further provided. Then, the original stochastic gradient descent optimizer is theoretically proved to be a flat minima filter that owns the talent to filter out the sharp minima. Furthermore, the flatter minima could be obtained by exploiting the proposed deformation functions, which is verified on CIFAR-100, with visualizations of loss landscapes near the critical points obtained by both the original optimizer and optimizer enhanced by deformation functions. The experimental results show that deformation functions do find flatter regions. Moreover, on ImageNet, CIFAR-10, and CIFAR-100, popular convolutional neural networks enhanced by deformation functions are compared with the corresponding original models, where significant improvements are observed on all of the involved models equipped with deformation functions. For example, the top-1 test accuracy of ResNet-20 on CIFAR-100 increases by 1.46%, with insignificant additional computational overhead.