 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivated Gradients for Deep Neural Networks
Paper and Code
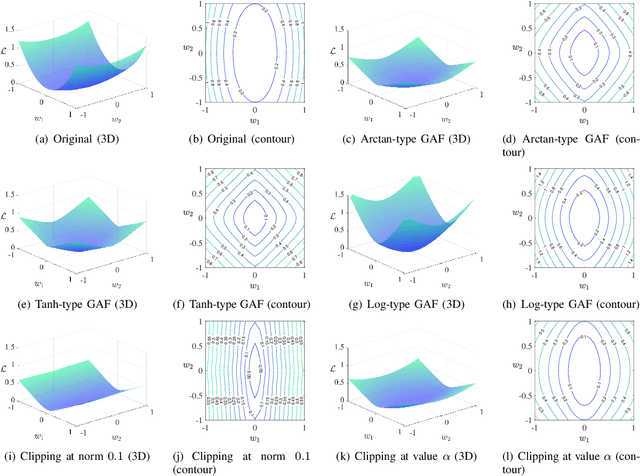
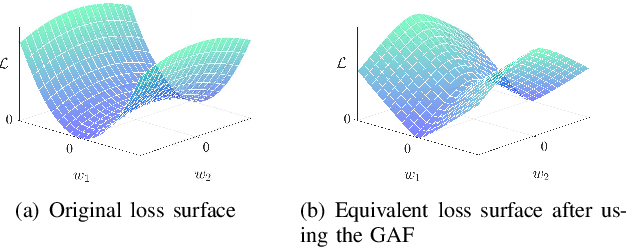
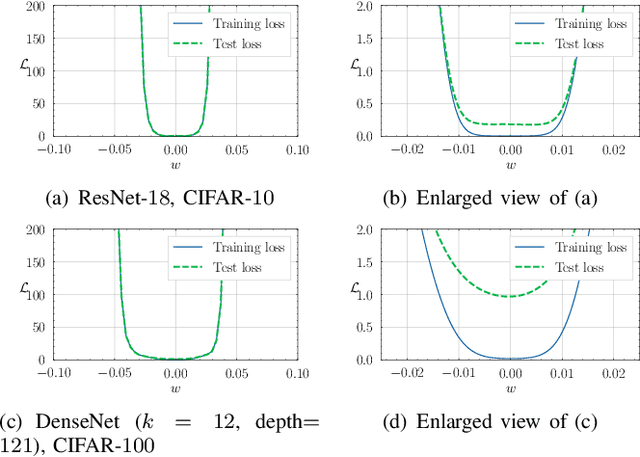
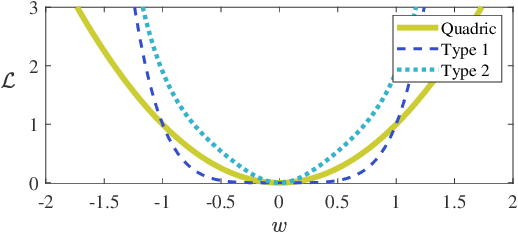
Deep neural networks often suffer from poor performance or even training failure due to the ill-conditioned problem, the vanishing/exploding gradient problem, and the saddle point problem. In this paper, a novel method by acting the gradient activation function (GAF) on the gradient is proposed to handle these challenges. Intuitively, the GAF enlarges the tiny gradients and restricts the large gradient. Theoretically, this paper gives conditions that the GAF needs to meet, and on this basis, proves that the GAF alleviates the problems mentioned above. In addition, this paper proves that the convergence rate of SGD with the GAF is faster than that without the GAF under some assumptions. Furthermore, experiments on CIFAR, ImageNet, and PASCAL visual object classes confirm the GAF's effectiveness. The experimental results also demonstrate that the proposed method is able to be adopted in various deep neural networks to improve their performance. The source code is publicly available at https://github.com/LongJin-lab/Activated-Gradients-for-Deep-Neural-Networks.