 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDE-Net: Dynamic Text-guided Image Editing Adversarial Networks
Paper and Code
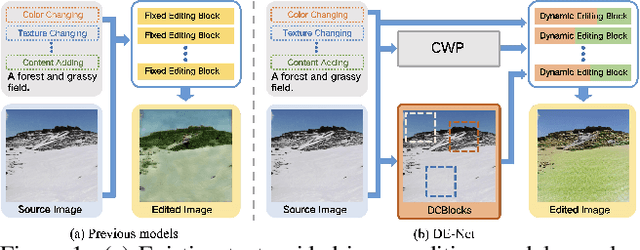
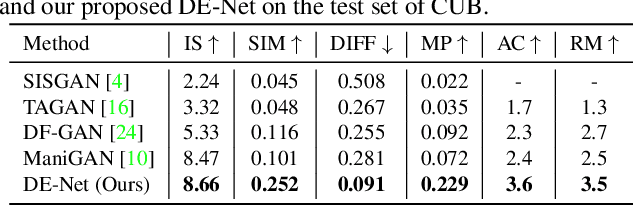
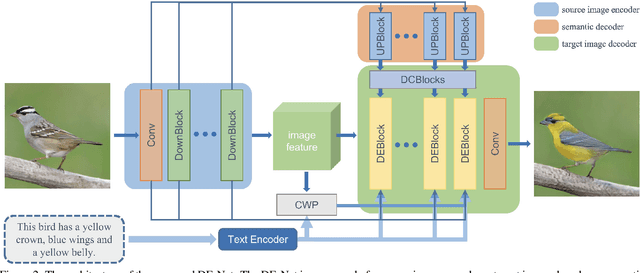
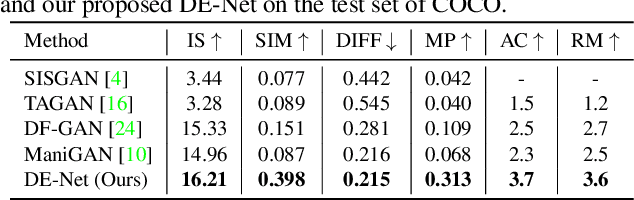
Text-guided image editing models have shown remarkable results. However, there remain two problems. First, they employ fixed manipulation modules for various editing requirements (e.g., color changing, texture changing, content adding and removing), which result in over-editing or insufficient editing. Second, they do not clearly distinguish between text-required parts and text-irrelevant parts, which leads to inaccurate editing. To solve these limitations, we propose: (i) a Dynamic Editing Block (DEBlock) which combines spatial- and channel-wise manipulations dynamically for various editing requirements. (ii) a Combination Weights Predictor (CWP) which predicts the combination weights for DEBlock according to the inference on text and visual features. (iii) a Dynamic text-adaptive Convolution Block (DCBlock) which queries source image features to distinguish text-required parts and text-irrelevant parts. Extensive experiments demonstrate that our DE-Net achieves excellent performance and manipulates source images more effectively and accurately. Code is available at \url{https://github.com/tobran/DE-Net}.