 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMRABooth: Subject and Motion Representation Alignment for Customized Video Generation
Dec 13, 2025Customized video generation aims to produce videos that faithfully preserve the subject's appearance from reference images while maintaining temporally consistent motion from reference videos. Existing methods struggle to ensure both subject appearance similarity and motion pattern consistency due to the lack of object-level guidance for subject and motion. To address this, we propose SMRABooth, which leverages the self-supervised encoder and optical flow encoder to provide object-level subject and motion representations. These representations are aligned with the model during the LoRA fine-tuning process. Our approach is structured in three core stages: (1) We exploit subject representations via a self-supervised encoder to guide subject alignment, enabling the model to capture overall structure of subject and enhance high-level semantic consistency. (2) We utilize motion representations from an optical flow encoder to capture structurally coherent and object-level motion trajectories independent of appearance. (3) We propose a subject-motion association decoupling strategy that applies sparse LoRAs injection across both locations and timing, effectively reducing interference between subject and motion LoRAs. Extensive experiments show that SMRABooth excels in subject and motion customization, maintaining consistent subject appearance and motion patterns, proving its effectiveness in controllable text-to-video generation.
Do We Need to Design Specific Diffusion Models for Different Tasks? Try ONE-PIC
Dec 07, 2024Large pretrained diffusion models have demonstrated impressive generation capabilities and have been adapted to various downstream tasks. However, unlike Large Language Models (LLMs) that can learn multiple tasks in a single model based on instructed data, diffusion models always require additional branches, task-specific training strategies, and losses for effective adaptation to different downstream tasks. This task-specific fine-tuning approach brings two drawbacks. 1) The task-specific additional networks create gaps between pretraining and fine-tuning which hinders the transfer of pretrained knowledge. 2) It necessitates careful additional network design, raising the barrier to learning and implementation, and making it less user-friendly. Thus, a question arises: Can we achieve a simple, efficient, and general approach to fine-tune diffusion models? To this end, we propose ONE-PIC. It enhances the inherited generative ability in the pretrained diffusion models without introducing additional modules. Specifically, we propose In-Visual-Context Tuning, which constructs task-specific training data by arranging source images and target images into a single image. This approach makes downstream fine-tuning closer to the pertaining, allowing our model to adapt more quickly to various downstream tasks. Moreover, we propose a Masking Strategy to unify different generative tasks. This strategy transforms various downstream fine-tuning tasks into predictions of the masked portions. The extensive experimental results demonstrate that our method is simple and efficient which streamlines the adaptation process and achieves excellent performance with lower costs. Code is available at https://github.com/tobran/ONE-PIC.
BeFA: A General Behavior-driven Feature Adapter for Multimedia Recommendation
Jun 01, 2024Multimedia recommender systems focus on utilizing behavioral information and content information to model user preferences. Typically, it employs pre-trained feature encoders to extract content features, then fuses them with behavioral features. However, pre-trained feature encoders often extract features from the entire content simultaneously, including excessive preference-irrelevant details. We speculate that it may result in the extracted features not containing sufficient features to accurately reflect user preferences. To verify our hypothesis, we introduce an attribution analysis method for visually and intuitively analyzing the content features. The results indicate that certain products' content features exhibit the issues of information drift}and information omission,reducing the expressive ability of features. Building upon this finding, we propose an effective and efficient general Behavior-driven Feature Adapter (BeFA) to tackle these issues. This adapter reconstructs the content feature with the guidance of behavioral information, enabling content features accurately reflecting user preferences. Extensive experiments demonstrate the effectiveness of the adapter across all multimedia recommendation methods. The code will be publicly available upon the paper's acceptance.
StoryImager: A Unified and Efficient Framework for Coherent Story Visualization and Completion
Apr 09, 2024
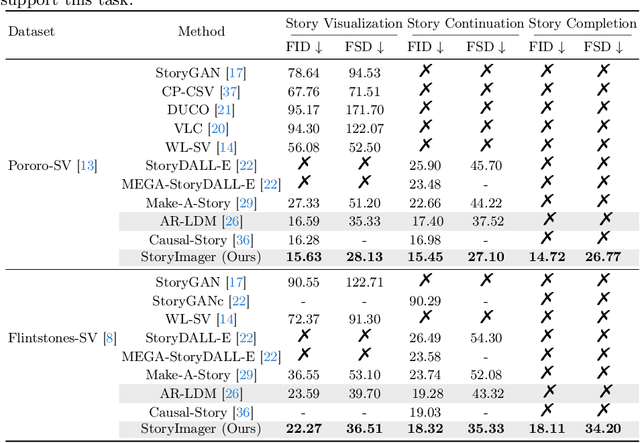

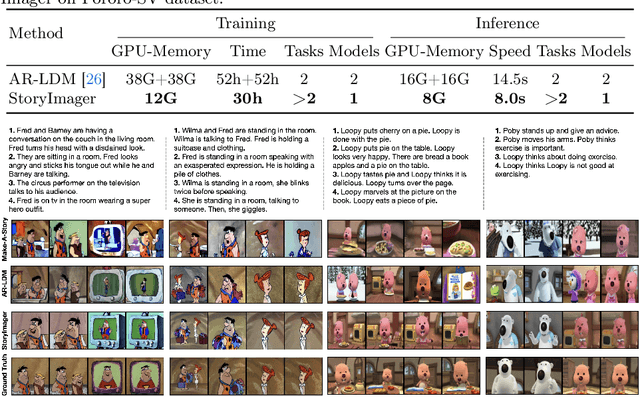
Story visualization aims to generate a series of realistic and coherent images based on a storyline. Current models adopt a frame-by-frame architecture by transforming the pre-trained text-to-image model into an auto-regressive manner. Although these models have shown notable progress, there are still three flaws. 1) The unidirectional generation of auto-regressive manner restricts the usability in many scenarios. 2) The additional introduced story history encoders bring an extremely high computational cost. 3) The story visualization and continuation models are trained and inferred independently, which is not user-friendly. To these ends, we propose a bidirectional, unified, and efficient framework, namely StoryImager. The StoryImager enhances the storyboard generative ability inherited from the pre-trained text-to-image model for a bidirectional generation. Specifically, we introduce a Target Frame Masking Strategy to extend and unify different story image generation tasks. Furthermore, we propose a Frame-Story Cross Attention Module that decomposes the cross attention for local fidelity and global coherence. Moreover, we design a Contextual Feature Extractor to extract contextual information from the whole storyline. The extensive experimental results demonstrate the excellent performance of our StoryImager. The code is available at https://github.com/tobran/StoryImager.
LD4MRec: Simplifying and Powering Diffusion Model for Multimedia Recommendation
Sep 27, 2023



Multimedia recommendation aims to predict users' future behaviors based on historical behavioral data and item's multimodal information. However, noise inherent in behavioral data, arising from unintended user interactions with uninteresting items, detrimentally impacts recommendation performance. Recently, diffusion models have achieved high-quality information generation, in which the reverse process iteratively infers future information based on the corrupted state. It meets the need of predictive tasks under noisy conditions, and inspires exploring their application to predicting user behaviors. Nonetheless, several challenges must be addressed: 1) Classical diffusion models require excessive computation, which does not meet the efficiency requirements of recommendation systems. 2) Existing reverse processes are mainly designed for continuous data, whereas behavioral information is discrete in nature. Therefore, an effective method is needed for the generation of discrete behavioral information. To tackle the aforementioned issues, we propose a Light Diffusion model for Multimedia Recommendation. First, to reduce computational complexity, we simplify the formula of the reverse process, enabling one-step inference instead of multi-step inference. Second, to achieve effective behavioral information generation, we propose a novel Conditional neural Network. It maps the discrete behavior data into a continuous latent space, and generates behaviors with the guidance of collaborative signals and user multimodal preference. Additionally, considering that completely clean behavior data is inaccessible, we introduce a soft behavioral reconstruction constraint during model training, facilitating behavior prediction with noisy data. Empirical studies conducted on three public datasets demonstrate the effectiveness of LD4MRec.
Multi-View Graph Convolutional Network for Multimedia Recommendation
Aug 07, 2023Multimedia recommendation has received much attention in recent years. It models user preferences based on both behavior information and item multimodal information. Though current GCN-based methods achieve notable success, they suffer from two limitations: (1) Modality noise contamination to the item representations. Existing methods often mix modality features and behavior features in a single view (e.g., user-item view) for propagation, the noise in the modality features may be amplified and coupled with behavior features. In the end, it leads to poor feature discriminability; (2) Incomplete user preference modeling caused by equal treatment of modality features. Users often exhibit distinct modality preferences when purchasing different items. Equally fusing each modality feature ignores the relative importance among different modalities, leading to the suboptimal user preference modeling. To tackle the above issues, we propose a novel Multi-View Graph Convolutional Network for the multimedia recommendation. Specifically, to avoid modality noise contamination, the modality features are first purified with the aid of item behavior information. Then, the purified modality features of items and behavior features are enriched in separate views, including the user-item view and the item-item view. In this way, the distinguishability of features is enhanced. Meanwhile, a behavior-aware fuser is designed to comprehensively model user preferences by adaptively learning the relative importance of different modality features. Furthermore, we equip the fuser with a self-supervised auxiliary task. This task is expected to maximize the mutual information between the fused multimodal features and behavior features, so as to capture complementary and supplementary preference information simultaneously. Extensive experiments on three public datasets demonstrate the effectiveness of our methods.
GALIP: Generative Adversarial CLIPs for Text-to-Image Synthesis
Jan 30, 2023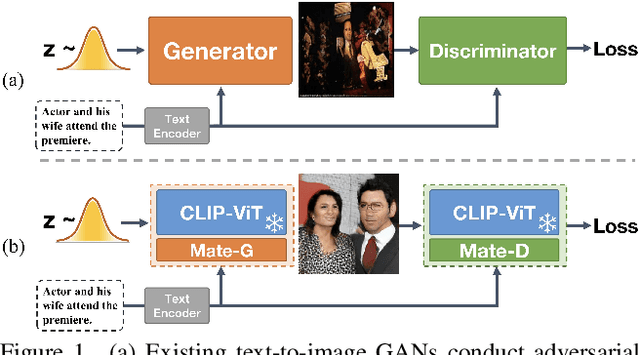
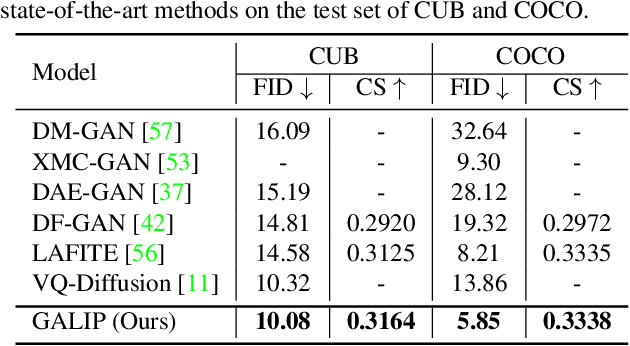
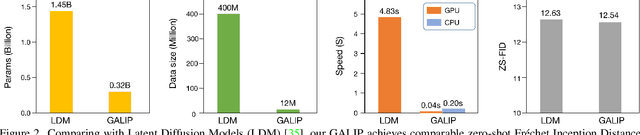
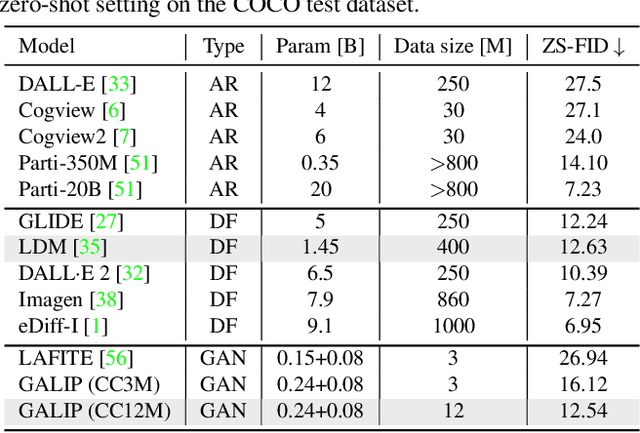
Synthesizing high-fidelity complex images from text is challenging. Based on large pretraining, the autoregressive and diffusion models can synthesize photo-realistic images. Although these large models have shown notable progress, there remain three flaws. 1) These models require tremendous training data and parameters to achieve good performance. 2) The multi-step generation design slows the image synthesis process heavily. 3) The synthesized visual features are difficult to control and require delicately designed prompts. To enable high-quality, efficient, fast, and controllable text-to-image synthesis, we propose Generative Adversarial CLIPs, namely GALIP. GALIP leverages the powerful pretrained CLIP model both in the discriminator and generator. Specifically, we propose a CLIP-based discriminator. The complex scene understanding ability of CLIP enables the discriminator to accurately assess the image quality. Furthermore, we propose a CLIP-empowered generator that induces the visual concepts from CLIP through bridge features and prompts. The CLIP-integrated generator and discriminator boost training efficiency, and as a result, our model only requires about 3% training data and 6% learnable parameters, achieving comparable results to large pretrained autoregressive and diffusion models. Moreover, our model achieves 120 times faster synthesis speed and inherits the smooth latent space from GAN. The extensive experimental results demonstrate the excellent performance of our GALIP. Code is available at https://github.com/tobran/GALIP.
DE-Net: Dynamic Text-guided Image Editing Adversarial Networks
Jun 02, 2022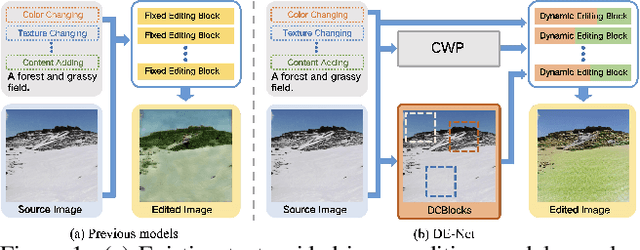
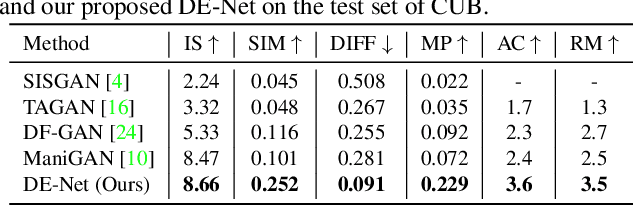
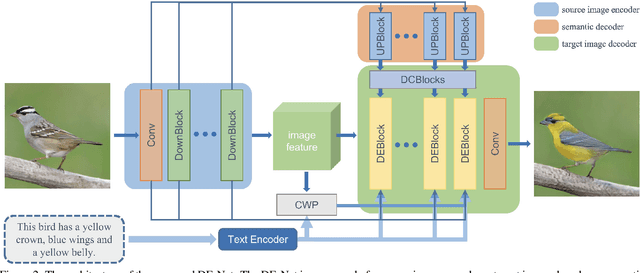
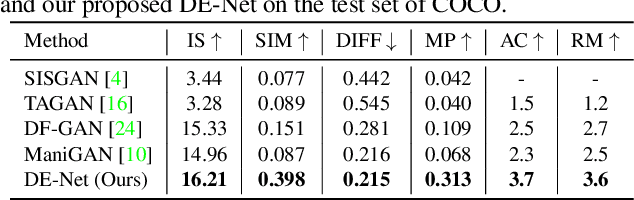
Text-guided image editing models have shown remarkable results. However, there remain two problems. First, they employ fixed manipulation modules for various editing requirements (e.g., color changing, texture changing, content adding and removing), which result in over-editing or insufficient editing. Second, they do not clearly distinguish between text-required parts and text-irrelevant parts, which leads to inaccurate editing. To solve these limitations, we propose: (i) a Dynamic Editing Block (DEBlock) which combines spatial- and channel-wise manipulations dynamically for various editing requirements. (ii) a Combination Weights Predictor (CWP) which predicts the combination weights for DEBlock according to the inference on text and visual features. (iii) a Dynamic text-adaptive Convolution Block (DCBlock) which queries source image features to distinguish text-required parts and text-irrelevant parts. Extensive experiments demonstrate that our DE-Net achieves excellent performance and manipulates source images more effectively and accurately. Code is available at \url{https://github.com/tobran/DE-Net}.
DualVGR: A Dual-Visual Graph Reasoning Unit for Video Question Answering
Jul 10, 2021
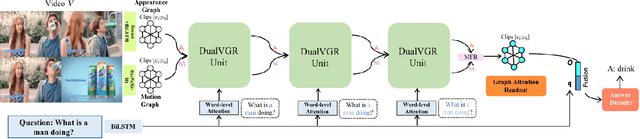
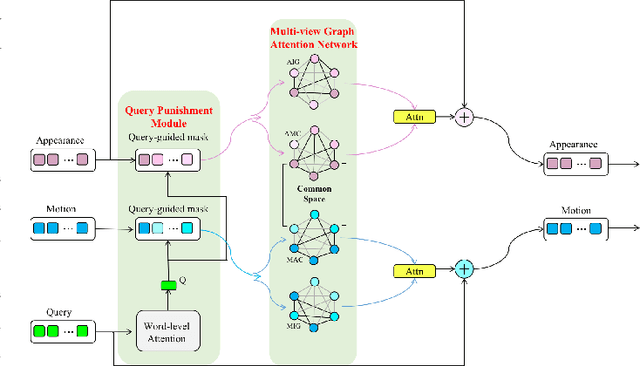
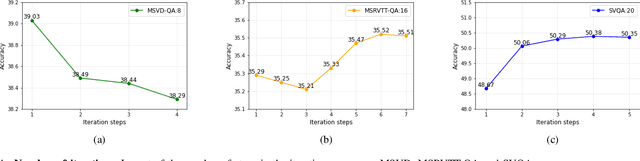
Video question answering is a challenging task, which requires agents to be able to understand rich video contents and perform spatial-temporal reasoning. However, existing graph-based methods fail to perform multi-step reasoning well, neglecting two properties of VideoQA: (1) Even for the same video, different questions may require different amount of video clips or objects to infer the answer with relational reasoning; (2) During reasoning, appearance and motion features have complicated interdependence which are correlated and complementary to each other. Based on these observations, we propose a Dual-Visual Graph Reasoning Unit (DualVGR) which reasons over videos in an end-to-end fashion. The first contribution of our DualVGR is the design of an explainable Query Punishment Module, which can filter out irrelevant visual features through multiple cycles of reasoning. The second contribution is the proposed Video-based Multi-view Graph Attention Network, which captures the relations between appearance and motion features. Our DualVGR network achieves state-of-the-art performance on the benchmark MSVD-QA and SVQA datasets, and demonstrates competitive results on benchmark MSRVTT-QA datasets. Our code is available at https://github.com/MMIR/DualVGR-VideoQA.
* 12 pages, 12 figures