 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualVGR: A Dual-Visual Graph Reasoning Unit for Video Question Answering
Paper and Code

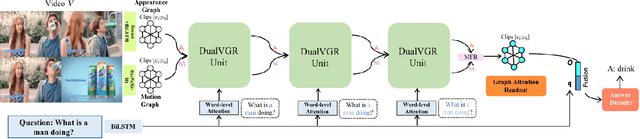
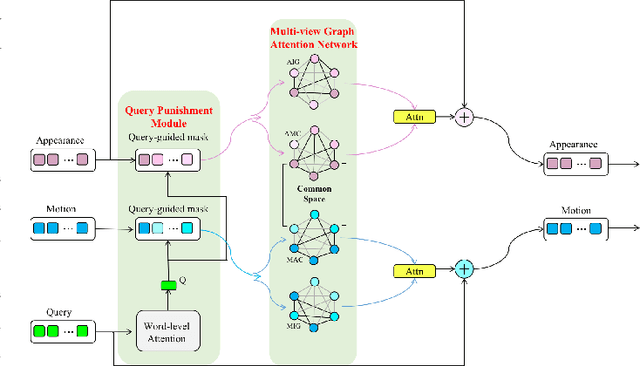
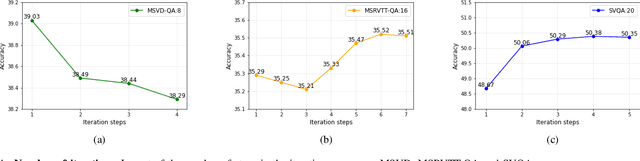
Video question answering is a challenging task, which requires agents to be able to understand rich video contents and perform spatial-temporal reasoning. However, existing graph-based methods fail to perform multi-step reasoning well, neglecting two properties of VideoQA: (1) Even for the same video, different questions may require different amount of video clips or objects to infer the answer with relational reasoning; (2) During reasoning, appearance and motion features have complicated interdependence which are correlated and complementary to each other. Based on these observations, we propose a Dual-Visual Graph Reasoning Unit (DualVGR) which reasons over videos in an end-to-end fashion. The first contribution of our DualVGR is the design of an explainable Query Punishment Module, which can filter out irrelevant visual features through multiple cycles of reasoning. The second contribution is the proposed Video-based Multi-view Graph Attention Network, which captures the relations between appearance and motion features. Our DualVGR network achieves state-of-the-art performance on the benchmark MSVD-QA and SVQA datasets, and demonstrates competitive results on benchmark MSRVTT-QA datasets. Our code is available at https://github.com/MMIR/DualVGR-VideoQA.