 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Training Data Attribution for Large Language Models with Fitting Error Consideration
Paper and Code


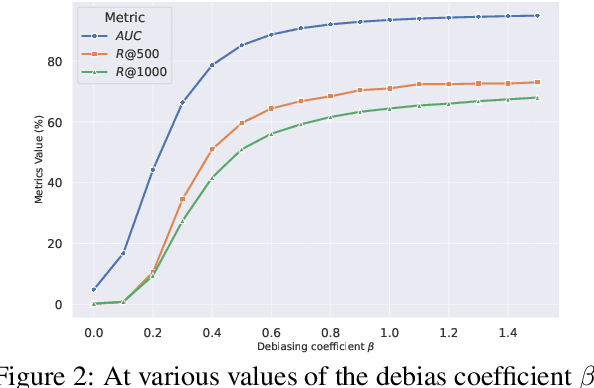
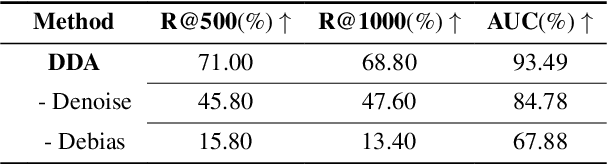
The black-box nature of large language models (LLMs) poses challenges in interpreting results, impacting issues such as data intellectual property protection and hallucination tracing. Training data attribution (TDA) methods are considered effective solutions to address these challenges. Most recent TDA methods rely on influence functions, assuming the model achieves minimized empirical risk. However, achieving this criterion is difficult, and sourcing accuracy can be compromised by fitting errors during model training. In this paper, we introduce a novel TDA method called Debias and Denoise Attribution (DDA), which enhances influence functions by addressing fitting errors. Specifically, the debias strategy seeks to improve the performance of influence functions by eliminating the knowledge bias present in the base model before fine-tuning, while the denoise strategy aims to reduce discrepancies in influence scores arising from varying degrees of fitting during the training process through smoothing techniques. Experimental results demonstrate that our method significantly outperforms existing approaches, achieving an averaged AUC of 91.64%. Moreover, DDA exhibits strong generality and scalability across various sources and different-scale models like LLaMA2, QWEN2, and Mistral.