 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTALDS-Net: Task-Aware Adaptive Local Descriptors Selection for Few-shot Image Classification
Dec 09, 2023Few-shot image classification aims to classify images from unseen novel classes with few samples. Recent works demonstrate that deep local descriptors exhibit enhanced representational capabilities compared to image-level features. However, most existing methods solely rely on either employing all local descriptors or directly utilizing partial descriptors, potentially resulting in the loss of crucial information. Moreover, these methods primarily emphasize the selection of query descriptors while overlooking support descriptors. In this paper, we propose a novel Task-Aware Adaptive Local Descriptors Selection Network (TALDS-Net), which exhibits the capacity for adaptive selection of task-aware support descriptors and query descriptors. Specifically, we compare the similarity of each local support descriptor with other local support descriptors to obtain the optimal support descriptor subset and then compare the query descriptors with the optimal support subset to obtain discriminative query descriptors. Extensive experiments demonstrate that our TALDS-Net outperforms state-of-the-art methods on both general and fine-grained datasets.
An Empirical Study of Frame Selection for Text-to-Video Retrieval
Nov 01, 2023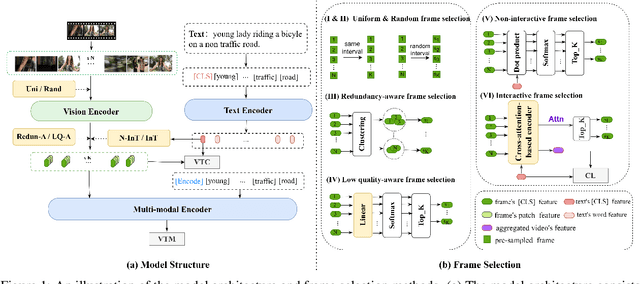
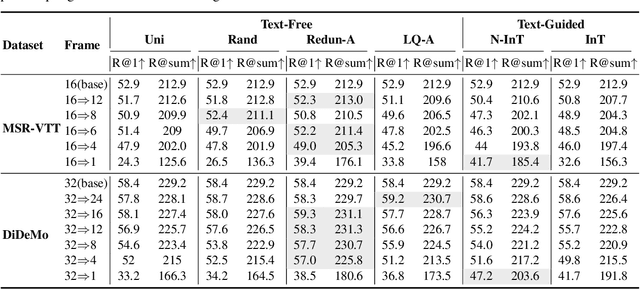
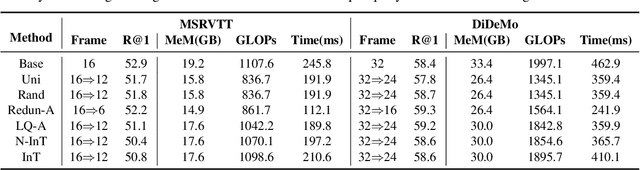

Text-to-video retrieval (TVR) aims to find the most relevant video in a large video gallery given a query text. The intricate and abundant context of the video challenges the performance and efficiency of TVR. To handle the serialized video contexts, existing methods typically select a subset of frames within a video to represent the video content for TVR. How to select the most representative frames is a crucial issue, whereby the selected frames are required to not only retain the semantic information of the video but also promote retrieval efficiency by excluding temporally redundant frames. In this paper, we make the first empirical study of frame selection for TVR. We systemically classify existing frame selection methods into text-free and text-guided ones, under which we detailedly analyze six different frame selections in terms of effectiveness and efficiency. Among them, two frame selections are first developed in this paper. According to the comprehensive analysis on multiple TVR benchmarks, we empirically conclude that the TVR with proper frame selections can significantly improve the retrieval efficiency without sacrificing the retrieval performance.
An Empirical Study of CLIP for Text-based Person Search
Aug 19, 2023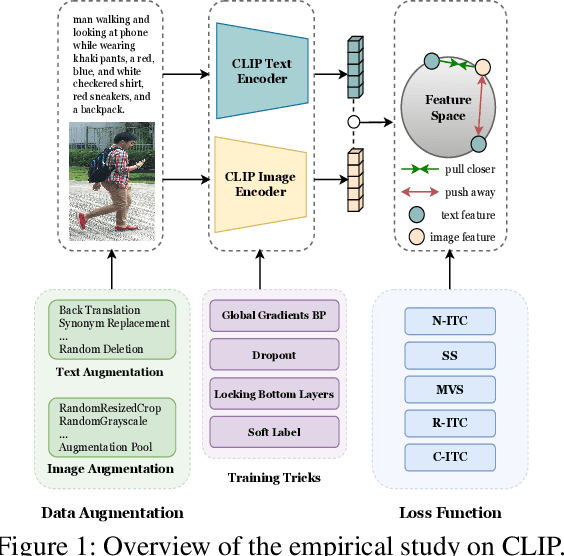
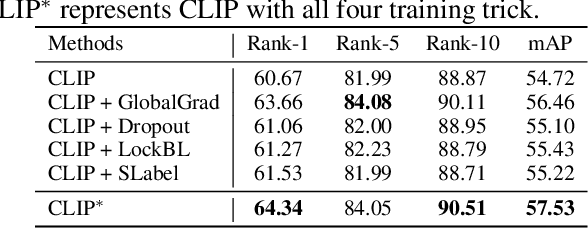
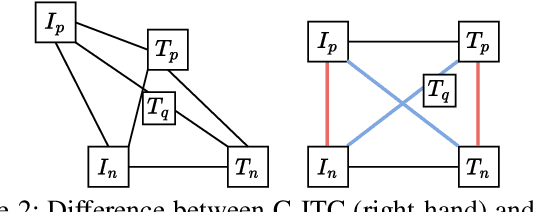
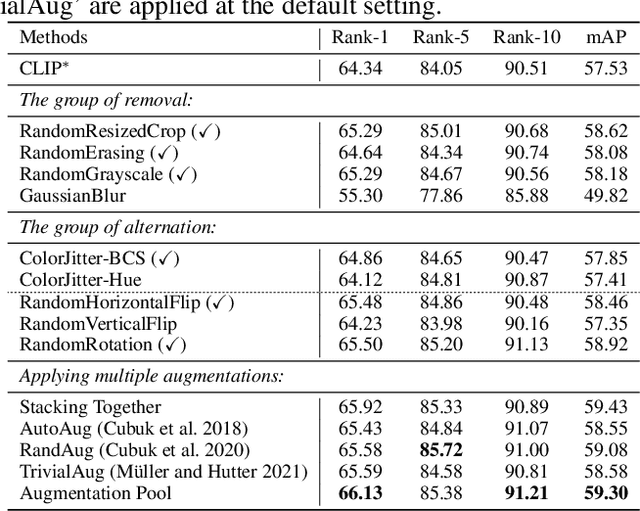
Text-based Person Search (TBPS) aims to retrieve the person images using natural language descriptions. Recently, Contrastive Language Image Pretraining (CLIP), a universal large cross-modal vision-language pre-training model, has remarkably performed over various cross-modal downstream tasks due to its powerful cross-modal semantic learning capacity. TPBS, as a fine-grained cross-modal retrieval task, is also facing the rise of research on the CLIP-based TBPS. In order to explore the potential of the visual-language pre-training model for downstream TBPS tasks, this paper makes the first attempt to conduct a comprehensive empirical study of CLIP for TBPS and thus contribute a straightforward, incremental, yet strong TBPS-CLIP baseline to the TBPS community. We revisit critical design considerations under CLIP, including data augmentation and loss function. The model, with the aforementioned designs and practical training tricks, can attain satisfactory performance without any sophisticated modules. Also, we conduct the probing experiments of TBPS-CLIP in model generalization and model compression, demonstrating the effectiveness of TBPS-CLIP from various aspects. This work is expected to provide empirical insights and highlight future CLIP-based TBPS research.
Small but Mighty: Enhancing 3D Point Clouds Semantic Segmentation with U-Next Framework
Apr 03, 2023



We study the problem of semantic segmentation of large-scale 3D point clouds. In recent years, significant research efforts have been directed toward local feature aggregation, improved loss functions and sampling strategies. While the fundamental framework of point cloud semantic segmentation has been largely overlooked, with most existing approaches rely on the U-Net architecture by default. In this paper, we propose U-Next, a small but mighty framework designed for point cloud semantic segmentation. The key to this framework is to learn multi-scale hierarchical representations from semantically similar feature maps. Specifically, we build our U-Next by stacking multiple U-Net $L^1$ codecs in a nested and densely arranged manner to minimize the semantic gap, while simultaneously fusing the feature maps across scales to effectively recover the fine-grained details. We also devised a multi-level deep supervision mechanism to further smooth gradient propagation and facilitate network optimization. Extensive experiments conducted on three large-scale benchmarks including S3DIS, Toronto3D, and SensatUrban demonstrate the superiority and the effectiveness of the proposed U-Next architecture. Our U-Next architecture shows consistent and visible performance improvements across different tasks and baseline models, indicating its great potential to serve as a general framework for future research.
LACV-Net: Semantic Segmentation of Large-Scale Point Cloud Scene via Local Adaptive and Comprehensive VLAD
Oct 12, 2022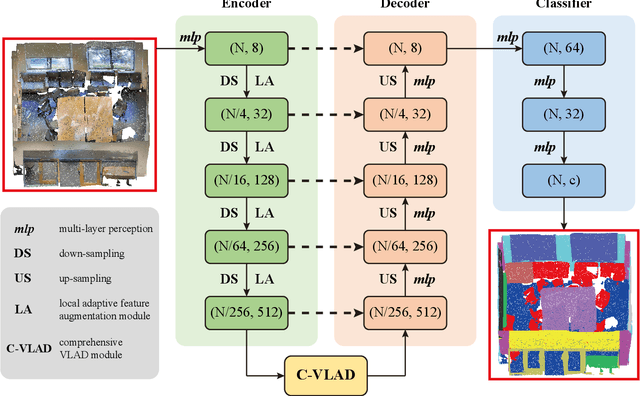
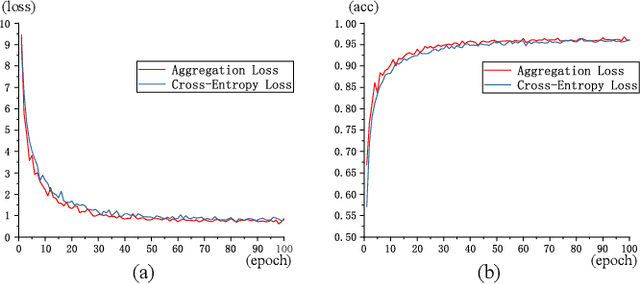
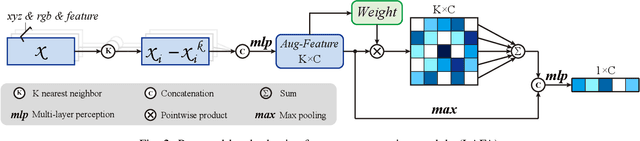
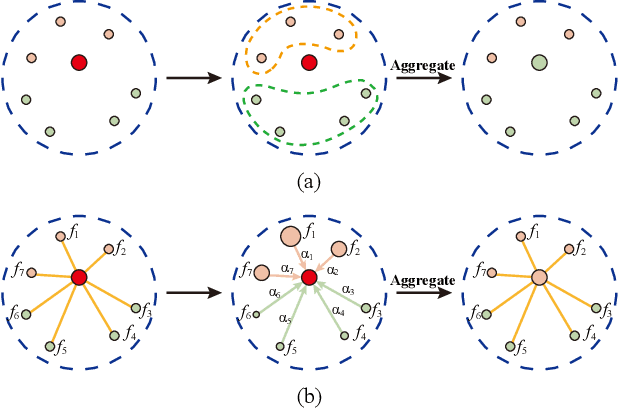
Large-scale point cloud semantic segmentation is an important task in 3D computer vision, which is widely applied in autonomous driving, robotics, and virtual reality. Current large-scale point cloud semantic segmentation methods usually use down-sampling operations to improve computation efficiency and acquire point clouds with multi-resolution. However, this may cause the problem of missing local information. Meanwhile, it is difficult for networks to capture global information in large-scale distributed contexts. To capture local and global information effectively, we propose an end-to-end deep neural network called LACV-Net for large-scale point cloud semantic segmentation. The proposed network contains three main components: 1) a local adaptive feature augmentation module (LAFA) to adaptively learn the similarity of centroids and neighboring points to augment the local context; 2) a comprehensive VLAD module (C-VLAD) that fuses local features with multi-layer, multi-scale, and multi-resolution to represent a comprehensive global description vector; and 3) an aggregation loss function to effectively optimize the segmentation boundaries by constraining the adaptive weight from the LAFA module. Compared to state-of-the-art networks on several large-scale benchmark datasets, including S3DIS, Toronto3D, and SensatUrban, we demonstrated the effectiveness of the proposed network.