 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Moment Retrieval from Text Queries via Single Frame Annotation
Apr 26, 2022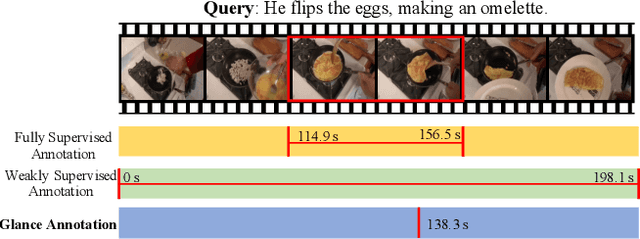
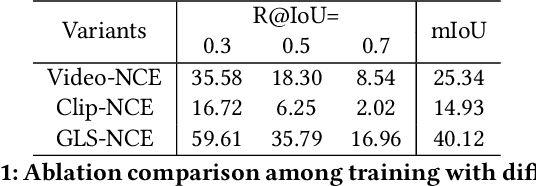
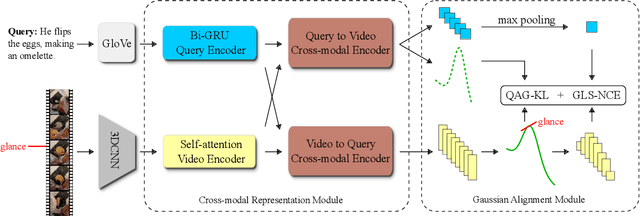
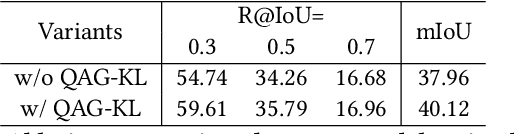
Video moment retrieval aims at finding the start and end timestamps of a moment (part of a video) described by a given natural language query. Fully supervised methods need complete temporal boundary annotations to achieve promising results, which is costly since the annotator needs to watch the whole moment. Weakly supervised methods only rely on the paired video and query, but the performance is relatively poor. In this paper, we look closer into the annotation process and propose a new paradigm called "glance annotation". This paradigm requires the timestamp of only one single random frame, which we refer to as a "glance", within the temporal boundary of the fully supervised counterpart. We argue this is beneficial because comparing to weak supervision, trivial cost is added yet more potential in performance is provided. Under the glance annotation setting, we propose a method named as Video moment retrieval via Glance Annotation (ViGA) based on contrastive learning. ViGA cuts the input video into clips and contrasts between clips and queries, in which glance guided Gaussian distributed weights are assigned to all clips. Our extensive experiments indicate that ViGA achieves better results than the state-of-the-art weakly supervised methods by a large margin, even comparable to fully supervised methods in some cases.