 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn The Consistency Training for Open-Set Semi-Supervised Learning
Jan 19, 2021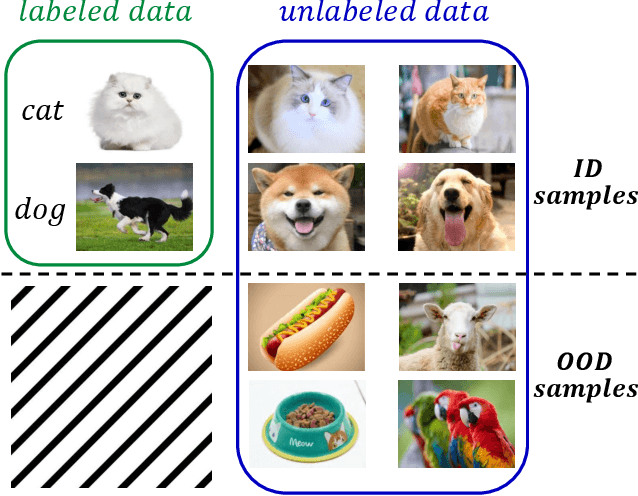
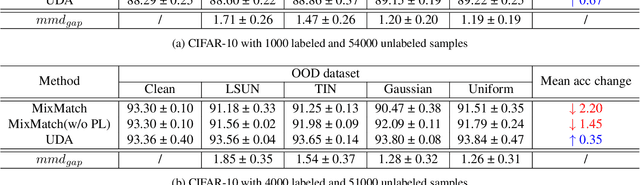
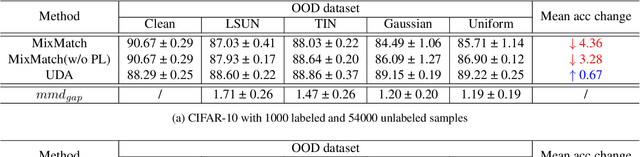

Conventional semi-supervised learning (SSL) methods, e.g., MixMatch, achieve great performance when both labeled and unlabeled dataset are drawn from the same distribution. However, these methods often suffer severe performance degradation in a more realistic setting, where unlabeled dataset contains out-of-distribution (OOD) samples. Recent approaches mitigate the negative influence of OOD samples by filtering them out from the unlabeled data. Our studies show that it is not necessary to get rid of OOD samples during training. On the contrary, the network can benefit from them if OOD samples are properly utilized. We thoroughly study how OOD samples affect DNN training in both low- and high-dimensional spaces, where two fundamental SSL methods are considered: Pseudo Labeling (PL) and Data Augmentation based Consistency Training (DACT). Conclusion is twofold: (1) unlike PL that suffers performance degradation, DACT brings improvement to model performance; (2) the improvement is closely related to class-wise distribution gap between the labeled and the unlabeled dataset. Motivated by this observation, we further improve the model performance by bridging the gap between the labeled and the unlabeled datasets (containing OOD samples). Compared to previous algorithms paying much attention to distinguishing between ID and OOD samples, our method makes better use of OOD samples and achieves state-of-the-art results.
Pruning Filter in Filter
Oct 18, 2020


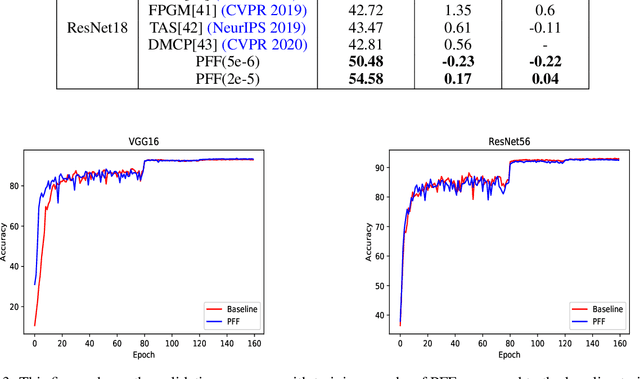
Pruning has become a very powerful and effective technique to compress and accelerate modern neural networks. Existing pruning methods can be grouped into two categories: filter pruning (FP) and weight pruning (WP). FP wins at hardware compatibility but loses at the compression ratio compared with WP. To converge the strength of both methods, we propose to prune the filter in the filter. Specifically, we treat a filter $F \in \mathbb{R}^{C\times K\times K}$ as $K \times K$ stripes, \emph{i.e.}, $1\times 1$ filters $\in \mathbb{R}^{C}$, then by pruning the stripes instead of the whole filter, we can achieve finer granularity than traditional FP while being hardware friendly. We term our method as SWP (\emph{Stripe-Wise Pruning}). SWP is implemented by introducing a novel learnable matrix called Filter Skeleton, whose values reflect the shape of each filter. As some recent work has shown that the pruned architecture is more crucial than the inherited important weights, we argue that the architecture of a single filter, \emph{i.e.}, the shape, also matters. Through extensive experiments, we demonstrate that SWP is more effective compared to the previous FP-based methods and achieves the state-of-art pruning ratio on CIFAR-10 and ImageNet datasets without obvious accuracy drop. Code is available at https://github.com/fxmeng/Pruning-Filter-in-Filter
DGD: Densifying the Knowledge of Neural Networks with Filter Grafting and Knowledge Distillation
Apr 26, 2020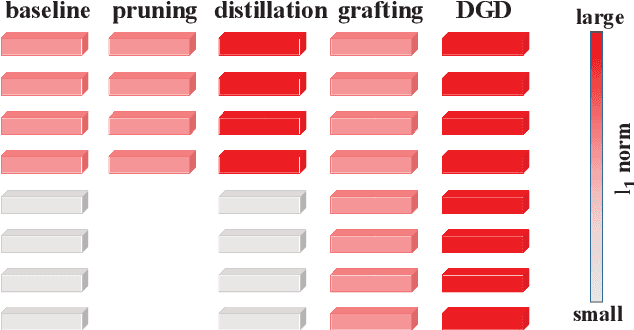
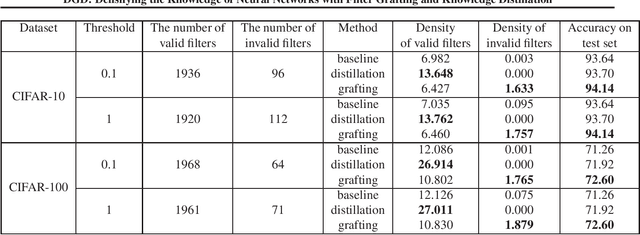
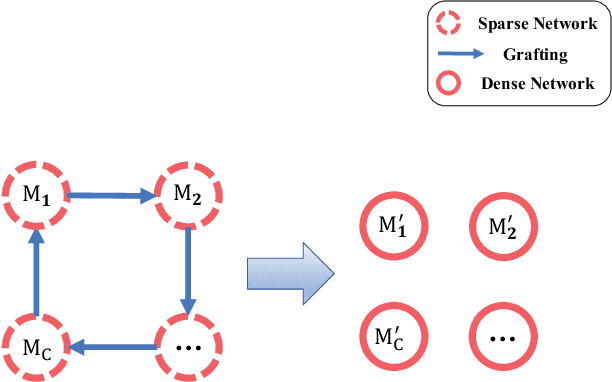
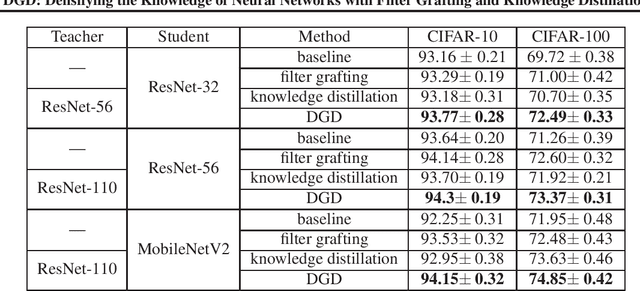
With a fixed model structure, knowledge distillation and filter grafting are two effective ways to boost single model accuracy. However, the working mechanism and the differences between distillation and grafting have not been fully unveiled. In this paper, we evaluate the effect of distillation and grafting in the filter level, and find that the impacts of the two techniques are surprisingly complementary: distillation mostly enhances the knowledge of valid filters while grafting mostly reactivates invalid filters. This observation guides us to design a unified training framework called DGD, where distillation and grafting are naturally combined to increase the knowledge density inside the filters given a fixed model structure. Through extensive experiments, we show that the knowledge densified network in DGD shares both advantages of distillation and grafting, lifting the model accuracy to a higher level.