 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTOOLCAD: Exploring Tool-Using Large Language Models in Text-to-CAD Generation with Reinforcement Learning
Apr 09, 2026Computer-Aided Design (CAD) is an expert-level task that relies on long-horizon reasoning and coherent modeling actions. Large Language Models (LLMs) have shown remarkable advancements in enabling language agents to tackle real-world tasks. Notably, there has been no investigation into how tool-using LLMs optimally interact with CAD engines, hindering the emergence of LLM-based agentic text-to-CAD modeling systems. We propose ToolCAD, a novel agentic CAD framework deploying LLMs as tool-using agents for text-to-CAD generation. Furthermore, we introduce an interactive CAD modeling gym to rollout reasoning and tool-augmented interaction trajectories with the CAD engine, incorporating hybrid feedback and human supervision. Meanwhile, an end-to-end post-training strategy is presented to enable the LLM agent to elicit refined CAD Modeling Chain of Thought (CAD-CoT) and evolve into proficient CAD tool-using agents via online curriculum reinforcement learning. Our findings demonstrate ToolCAD fills the gap in adopting and training open-source LLMs for CAD tool-using agents, enabling them to perform comparably to proprietary models, paving the way for more accessible and robust autonomous text-to-CAD modeling systems.
Learning Canonical View Representation for 3D Shape Recognition with Arbitrary Views
Aug 17, 2021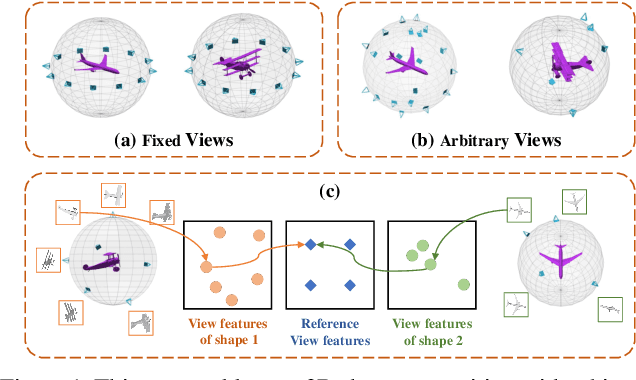

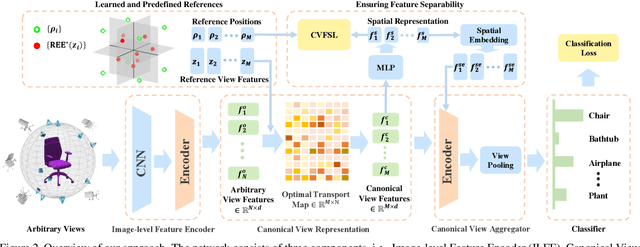

In this paper, we focus on recognizing 3D shapes from arbitrary views, i.e., arbitrary numbers and positions of viewpoints. It is a challenging and realistic setting for view-based 3D shape recognition. We propose a canonical view representation to tackle this challenge. We first transform the original features of arbitrary views to a fixed number of view features, dubbed canonical view representation, by aligning the arbitrary view features to a set of learnable reference view features using optimal transport. In this way, each 3D shape with arbitrary views is represented by a fixed number of canonical view features, which are further aggregated to generate a rich and robust 3D shape representation for shape recognition. We also propose a canonical view feature separation constraint to enforce that the view features in canonical view representation can be embedded into scattered points in a Euclidean space. Experiments on the ModelNet40, ScanObjectNN, and RGBD datasets show that our method achieves competitive results under the fixed viewpoint settings, and significantly outperforms the applicable methods under the arbitrary view setting.
Part2Whole: Iteratively Enrich Detail for Cross-Modal Retrieval with Partial Query
Mar 02, 2021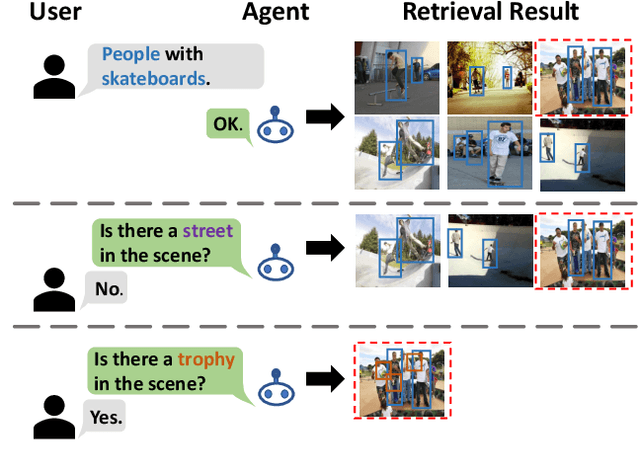

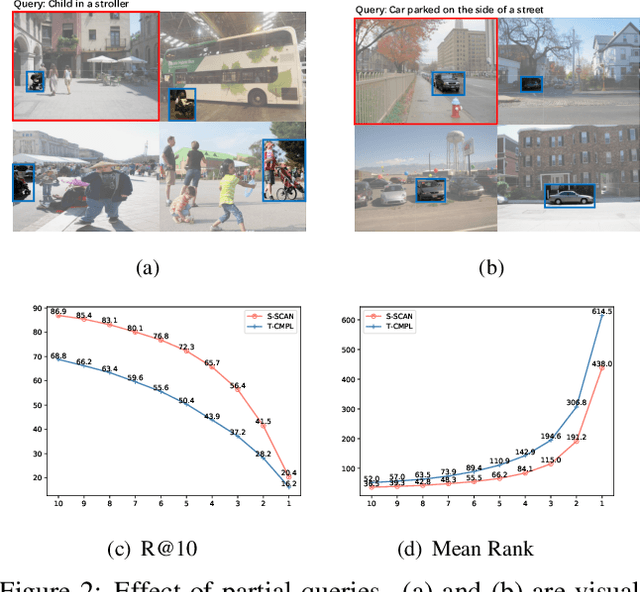
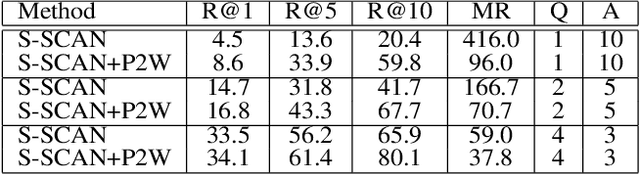
Text-based image retrieval has seen considerable progress in recent years. However, the performance of existing methods suffers in real life since the user is likely to provide an incomplete description of a complex scene, which often leads to results filled with false positives that fit the incomplete description. In this work, we introduce the partial-query problem and extensively analyze its influence on text-based image retrieval. We then propose an interactive retrieval framework called Part2Whole to tackle this problem by iteratively enriching the missing details. Specifically, an Interactive Retrieval Agent is trained to build an optimal policy to refine the initial query based on a user-friendly interaction and statistical characteristics of the gallery. Compared to other dialog-based methods that rely heavily on the user to feed back differentiating information, we let AI take over the optimal feedback searching process and hint the user with confirmation-based questions about details. Furthermore, since fully-supervised training is often infeasible due to the difficulty of obtaining human-machine dialog data, we present a weakly-supervised reinforcement learning method that needs no human-annotated data other than the text-image dataset. Experiments show that our framework significantly improves the performance of text-based image retrieval under complex scenes.
Contextual Non-Local Alignment over Full-Scale Representation for Text-Based Person Search
Jan 08, 2021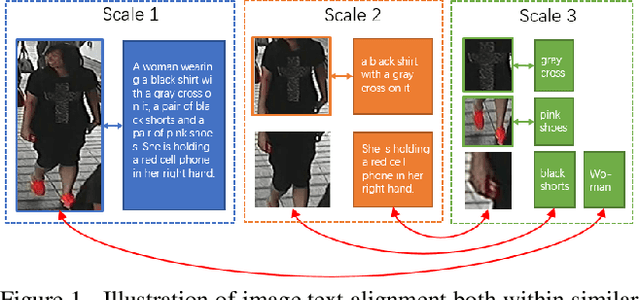
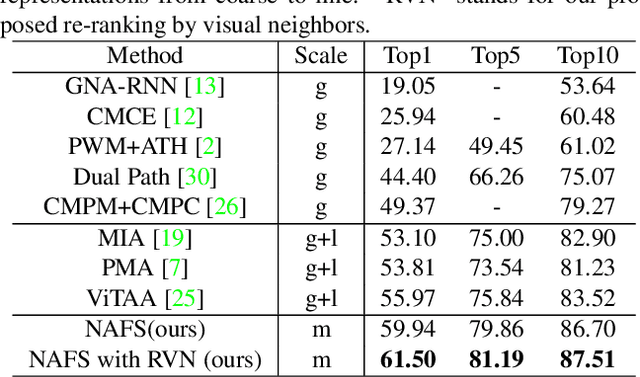
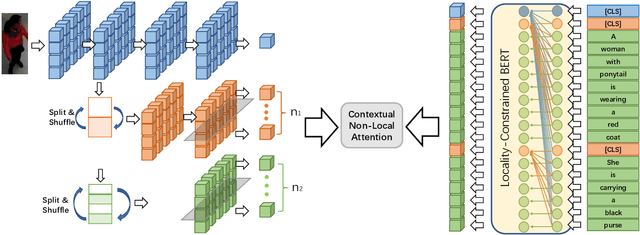
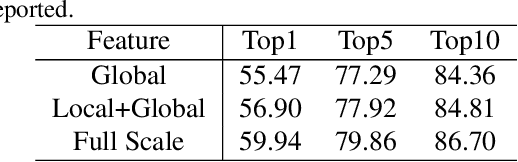
Text-based person search aims at retrieving target person in an image gallery using a descriptive sentence of that person. It is very challenging since modal gap makes effectively extracting discriminative features more difficult. Moreover, the inter-class variance of both pedestrian images and descriptions is small. So comprehensive information is needed to align visual and textual clues across all scales. Most existing methods merely consider the local alignment between images and texts within a single scale (e.g. only global scale or only partial scale) then simply construct alignment at each scale separately. To address this problem, we propose a method that is able to adaptively align image and textual features across all scales, called NAFS (i.e.Non-local Alignment over Full-Scale representations). Firstly, a novel staircase network structure is proposed to extract full-scale image features with better locality. Secondly, a BERT with locality-constrained attention is proposed to obtain representations of descriptions at different scales. Then, instead of separately aligning features at each scale, a novel contextual non-local attention mechanism is applied to simultaneously discover latent alignments across all scales. The experimental results show that our method outperforms the state-of-the-art methods by 5.53% in terms of top-1 and 5.35% in terms of top-5 on text-based person search dataset. The code is available at https://github.com/TencentYoutuResearch/PersonReID-NAFS
Learning with Instance-Dependent Label Noise: A Sample Sieve Approach
Oct 05, 2020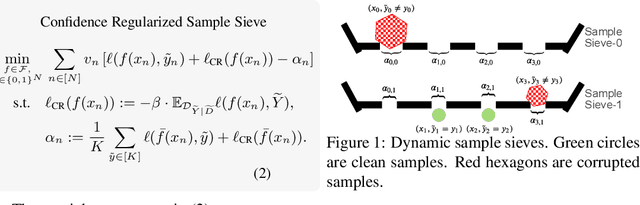

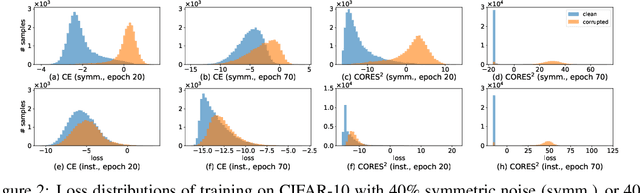
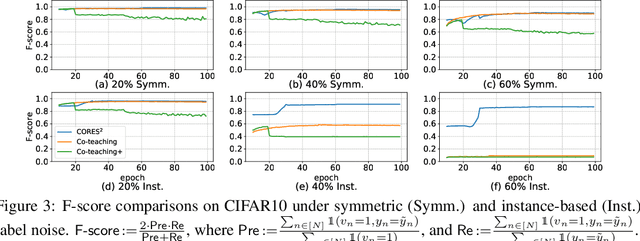
Human-annotated labels are often prone to noise, and the presence of such noise will degrade the performance of the resulting deep neural network (DNN) models. Much of the literature (with several recent exceptions) of learning with noisy labels focuses on the case when the label noise is independent from features. Practically, annotations errors tend to be instance-dependent and often depend on the difficulty levels of recognizing a certain task. Applying existing results from instance-independent settings would require a significant amount of estimation of noise rates. Therefore, learning with instance-dependent label noise remains a challenge. In this paper, we propose CORES^2 (COnfidence REgularized Sample Sieve), which progressively sieves out corrupted samples. The implementation of CORES^2 does not require specifying noise rates and yet we are able to provide theoretical guarantees of CORES^2 in filtering out the corrupted examples. This high-quality sample sieve allows us to treat clean examples and the corrupted ones separately in training a DNN solution, and such a separation is shown to be advantageous in the instance-dependent noise setting. We demonstrate the performance of CORES^2 on CIFAR10 and CIFAR100 datasets with synthetic instance-dependent label noise and Clothing1M with real-world human noise. As of independent interests, our sample sieve provides a generic machinery for anatomizing noisy datasets and provides a flexible interface for various robust training techniques to further improve the performance.
Devil's in the Detail: Graph-based Key-point Alignment and Embedding for Person Re-ID
Sep 11, 2020

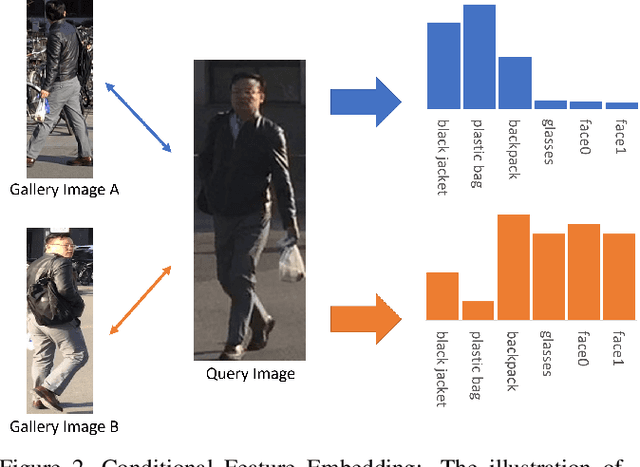
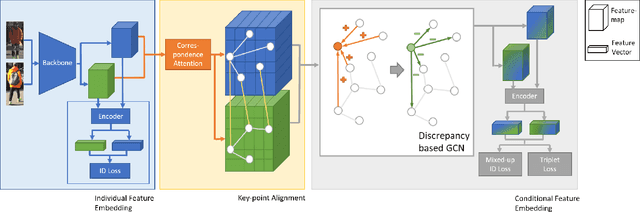
Although Person Re-Identification has made impressive progress, difficult cases like occlusion, change of view-point and similar clothing still bring great challenges. Besides overall visual features, matching and comparing detailed local information is also essential for tackling these challenges. This paper proposes two key recognition patterns to better utilize the local information of pedestrian images. From the spatial perspective, the model should be able to select and align key-points from the image pairs for comparison (i.e. key-points alignment). From the perspective of feature channels, the feature of a query image should be dynamically adjusted based on the gallery image it needs to match (i.e. conditional feature embedding). Most of the existing methods are unable to satisfy both key-point alignment and conditional feature embedding. By introducing novel techniques including correspondence attention module and discrepancy-based GCN, we propose an end-to-end ReID method that integrates both patterns into a unified framework, called Siamese-GCN. The experiments show that Siamese-GCN achieves state-of-the-art performance on three public datasets.
Rethinking Temporal Fusion for Video-based Person Re-identification on Semantic and Time Aspect
Nov 28, 2019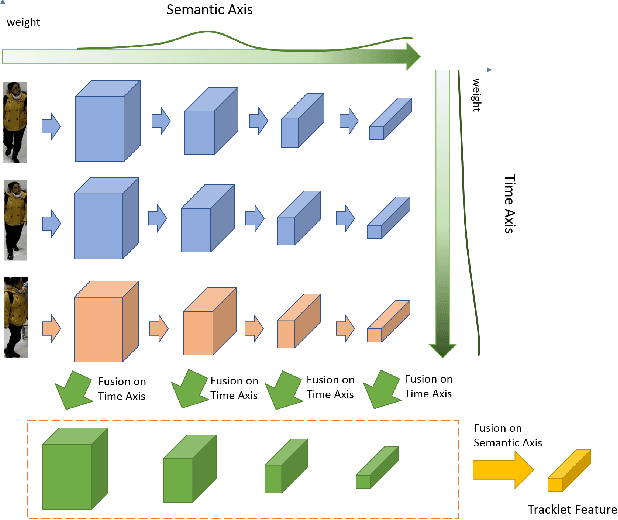
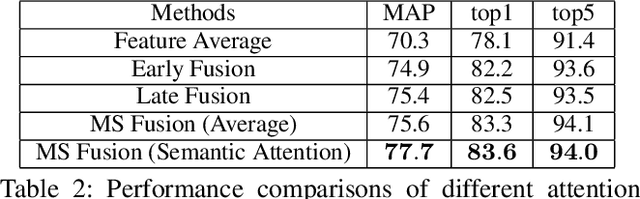
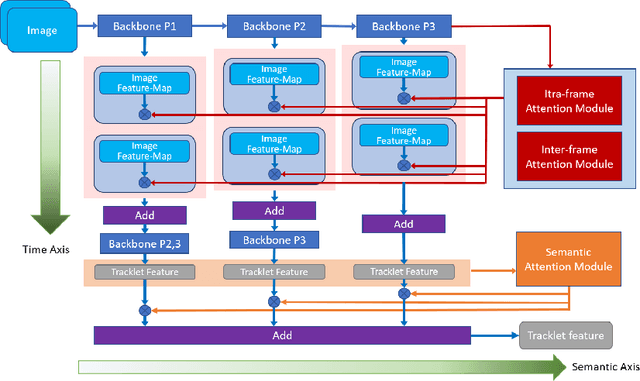
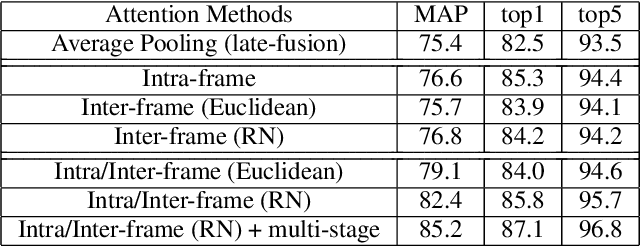
Recently, the research interest of person re-identification (ReID) has gradually turned to video-based methods, which acquire a person representation by aggregating frame features of an entire video. However, existing video-based ReID methods do not consider the semantic difference brought by the outputs of different network stages, which potentially compromises the information richness of the person features. Furthermore, traditional methods ignore important relationship among frames, which causes information redundancy in fusion along the time axis. To address these issues, we propose a novel general temporal fusion framework to aggregate frame features on both semantic aspect and time aspect. As for the semantic aspect, a multi-stage fusion network is explored to fuse richer frame features at multiple semantic levels, which can effectively reduce the information loss caused by the traditional single-stage fusion. While, for the time axis, the existing intra-frame attention method is improved by adding a novel inter-frame attention module, which effectively reduces the information redundancy in temporal fusion by taking the relationship among frames into consideration. The experimental results show that our approach can effectively improve the video-based re-identification accuracy, achieving the state-of-the-art performance.