 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyramid Feature Attention Network for Monocular Depth Prediction
Mar 03, 2024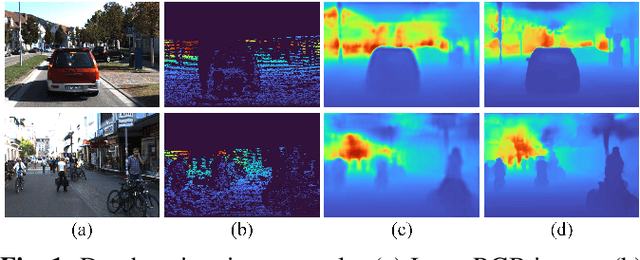
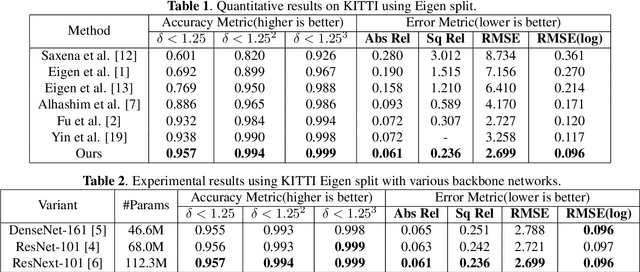
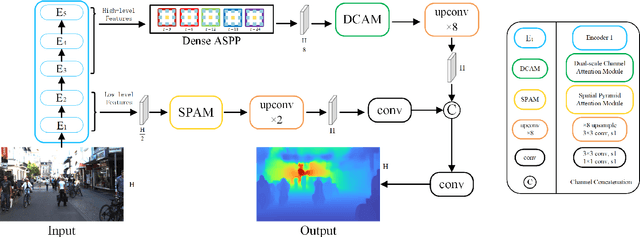
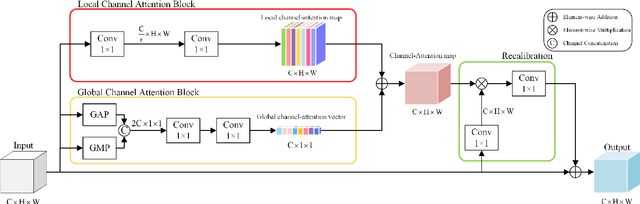
Deep convolutional neural networks (DCNNs) have achieved great success in monocular depth estimation (MDE). However, few existing works take the contributions for MDE of different levels feature maps into account, leading to inaccurate spatial layout, ambiguous boundaries and discontinuous object surface in the prediction. To better tackle these problems, we propose a Pyramid Feature Attention Network (PFANet) to improve the high-level context features and low-level spatial features. In the proposed PFANet, we design a Dual-scale Channel Attention Module (DCAM) to employ channel attention in different scales, which aggregate global context and local information from the high-level feature maps. To exploit the spatial relationship of visual features, we design a Spatial Pyramid Attention Module (SPAM) which can guide the network attention to multi-scale detailed information in the low-level feature maps. Finally, we introduce scale-invariant gradient loss to increase the penalty on errors in depth-wise discontinuous regions. Experimental results show that our method outperforms state-of-the-art methods on the KITTI dataset.
X-MLP: A Patch Embedding-Free MLP Architecture for Vision
Jul 02, 2023


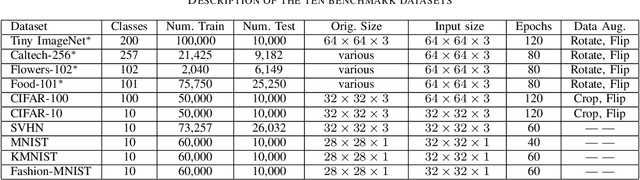
Convolutional neural networks (CNNs) and vision transformers (ViT) have obtained great achievements in computer vision. Recently, the research of multi-layer perceptron (MLP) architectures for vision have been popular again. Vision MLPs are designed to be independent from convolutions and self-attention operations. However, existing vision MLP architectures always depend on convolution for patch embedding. Thus we propose X-MLP, an architecture constructed absolutely upon fully connected layers and free from patch embedding. It decouples the features extremely and utilizes MLPs to interact the information across the dimension of width, height and channel independently and alternately. X-MLP is tested on ten benchmark datasets, all obtaining better performance than other vision MLP models. It even surpasses CNNs by a clear margin on various dataset. Furthermore, through mathematically restoring the spatial weights, we visualize the information communication between any couples of pixels in the feature map and observe the phenomenon of capturing long-range dependency.
Learn to Enhance the Negative Information in Convolutional Neural Network
Jun 18, 2023This paper proposes a learnable nonlinear activation mechanism specifically for convolutional neural network (CNN) termed as LENI, which learns to enhance the negative information in CNNs. In sharp contrast to ReLU which cuts off the negative neurons and suffers from the issue of ''dying ReLU'', LENI enjoys the capacity to reconstruct the dead neurons and reduce the information loss. Compared to improved ReLUs, LENI introduces a learnable approach to process the negative phase information more properly. In this way, LENI can enhance the model representational capacity significantly while maintaining the original advantages of ReLU. As a generic activation mechanism, LENI possesses the property of portability and can be easily utilized in any CNN models through simply replacing the activation layers with LENI block. Extensive experiments validate that LENI can improve the performance of various baseline models on various benchmark datasets by a clear margin (up to 1.24% higher top-1 accuracy on ImageNet-1k) with negligible extra parameters. Further experiments show that LENI can act as a channel compensation mechanism, offering competitive or even better performance but with fewer learned parameters than baseline models. In addition, LENI introduces the asymmetry to the model structure which contributes to the enhancement of representational capacity. Through visualization experiments, we validate that LENI can retain more information and learn more representations.
Reborn Mechanism: Rethinking the Negative Phase Information Flow in Convolutional Neural Network
Jul 07, 2021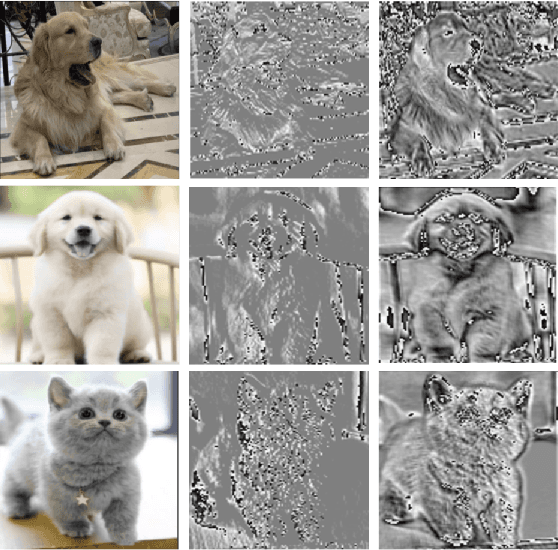
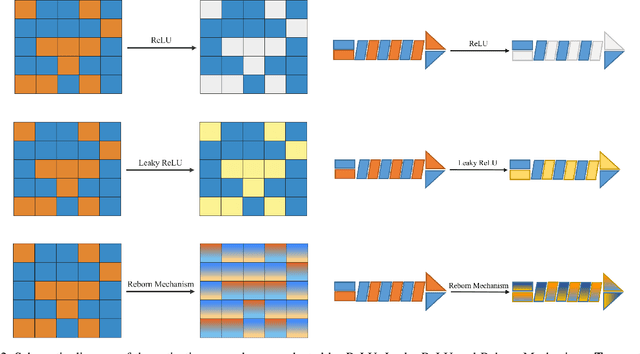

This paper proposes a novel nonlinear activation mechanism typically for convolutional neural network (CNN), named as reborn mechanism. In sharp contrast to ReLU which cuts off the negative phase value, the reborn mechanism enjoys the capacity to reborn and reconstruct dead neurons. Compared to other improved ReLU functions, reborn mechanism introduces a more proper way to utilize the negative phase information. Extensive experiments validate that this activation mechanism is able to enhance the model representation ability more significantly and make the better use of the input data information while maintaining the advantages of the original ReLU function. Moreover, reborn mechanism enables a non-symmetry that is hardly achieved by traditional CNNs and can act as a channel compensation method, offering competitive or even better performance but with fewer learned parameters than traditional methods. Reborn mechanism was tested on various benchmark datasets, all obtaining better performance than previous nonlinear activation functions.
Jitter: Random Jittering Loss Function
Jul 07, 2021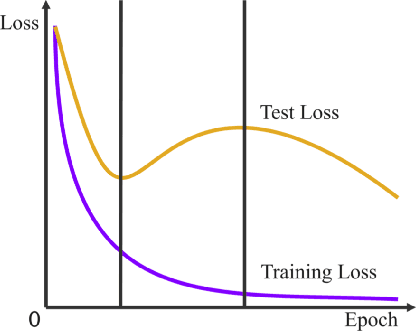
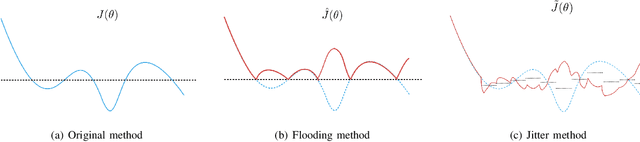
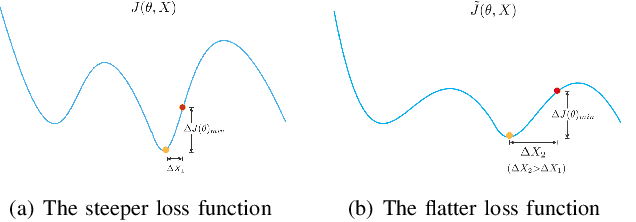
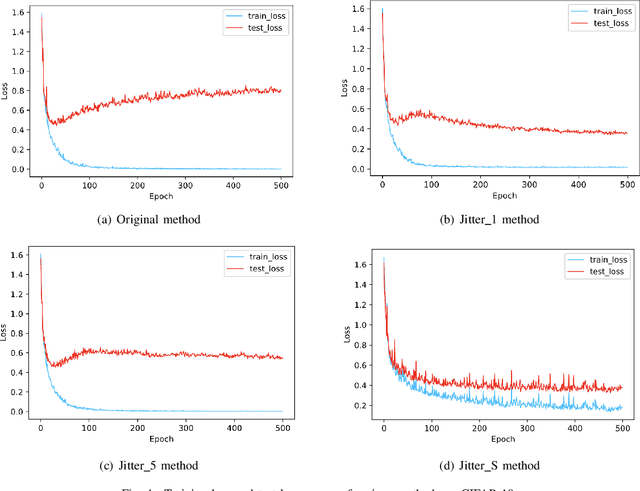
Regularization plays a vital role in machine learning optimization. One novel regularization method called flooding makes the training loss fluctuate around the flooding level. It intends to make the model continue to random walk until it comes to a flat loss landscape to enhance generalization. However, the hyper-parameter flooding level of the flooding method fails to be selected properly and uniformly. We propose a novel method called Jitter to improve it. Jitter is essentially a kind of random loss function. Before training, we randomly sample the Jitter Point from a specific probability distribution. The flooding level should be replaced by Jitter point to obtain a new target function and train the model accordingly. As Jitter point acting as a random factor, we actually add some randomness to the loss function, which is consistent with the fact that there exists innumerable random behaviors in the learning process of the machine learning model and is supposed to make the model more robust. In addition, Jitter performs random walk randomly which divides the loss curve into small intervals and then flipping them over, ideally making the loss curve much flatter and enhancing generalization ability. Moreover, Jitter can be a domain-, task-, and model-independent regularization method and train the model effectively after the training error reduces to zero. Our experimental results show that Jitter method can improve model performance more significantly than the previous flooding method and make the test loss curve descend twice.