 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMamba-VMR: Multimodal Query Augmentation via Generated Videos for Precise Temporal Grounding
Mar 23, 2026Text-driven video moment retrieval (VMR) remains challenging due to limited capture of hidden temporal dynamics in untrimmed videos, leading to imprecise grounding in long sequences. Traditional methods rely on natural language queries (NLQs) or static image augmentations, overlooking motion sequences and suffering from high computational costs in Transformer-based architectures. Existing approaches fail to integrate subtitle contexts and generated temporal priors effectively, we therefore propose a novel two-stage framework for enhanced temporal grounding. In the first stage, LLM-guided subtitle matching identifies relevant textual cues from video subtitles, fused with the query to generate auxiliary short videos via text-to-video models, capturing implicit motion information as temporal priors. In the second stage, augmented queries are processed through a multi-modal controlled Mamba network, extending text-controlled selection with video-guided gating for efficient fusion of generated priors and long sequences while filtering noise. Our framework is agnostic to base retrieval models and widely applicable for multimodal VMR. Experimental evaluations on the TVR benchmark demonstrate significant improvements over state-of-the-art methods, including reduced computational overhead and higher recall in long-sequence grounding.
FaceSnap: Enhanced ID-fidelity Network for Tuning-free Portrait Customization
Jan 31, 2026Benefiting from the significant advancements in text-to-image diffusion models, research in personalized image generation, particularly customized portrait generation, has also made great strides recently. However, existing methods either require time-consuming fine-tuning and lack generalizability or fail to achieve high fidelity in facial details. To address these issues, we propose FaceSnap, a novel method based on Stable Diffusion (SD) that requires only a single reference image and produces extremely consistent results in a single inference stage. This method is plug-and-play and can be easily extended to different SD models. Specifically, we design a new Facial Attribute Mixer that can extract comprehensive fused information from both low-level specific features and high-level abstract features, providing better guidance for image generation. We also introduce a Landmark Predictor that maintains reference identity across landmarks with different poses, providing diverse yet detailed spatial control conditions for image generation. Then we use an ID-preserving module to inject these into the UNet. Experimental results demonstrate that our approach performs remarkably in personalized and customized portrait generation, surpassing other state-of-the-art methods in this domain.
Diff-PC: Identity-preserving and 3D-aware Controllable Diffusion for Zero-shot Portrait Customization
Jan 31, 2026Portrait customization (PC) has recently garnered significant attention due to its potential applications. However, existing PC methods lack precise identity (ID) preservation and face control. To address these tissues, we propose Diff-PC, a diffusion-based framework for zero-shot PC, which generates realistic portraits with high ID fidelity, specified facial attributes, and diverse backgrounds. Specifically, our approach employs the 3D face predictor to reconstruct the 3D-aware facial priors encompassing the reference ID, target expressions, and poses. To capture fine-grained face details, we design ID-Encoder that fuses local and global facial features. Subsequently, we devise ID-Ctrl using the 3D face to guide the alignment of ID features. We further introduce ID-Injector to enhance ID fidelity and facial controllability. Finally, training on our collected ID-centric dataset improves face similarity and text-to-image (T2I) alignment. Extensive experiments demonstrate that Diff-PC surpasses state-of-the-art methods in ID preservation, facial control, and T2I consistency. Furthermore, our method is compatible with multi-style foundation models.
HiFi-Portrait: Zero-shot Identity-preserved Portrait Generation with High-fidelity Multi-face Fusion
Dec 16, 2025



Recent advancements in diffusion-based technologies have made significant strides, particularly in identity-preserved portrait generation (IPG). However, when using multiple reference images from the same ID, existing methods typically produce lower-fidelity portraits and struggle to customize face attributes precisely. To address these issues, this paper presents HiFi-Portrait, a high-fidelity method for zero-shot portrait generation. Specifically, we first introduce the face refiner and landmark generator to obtain fine-grained multi-face features and 3D-aware face landmarks. The landmarks include the reference ID and the target attributes. Then, we design HiFi-Net to fuse multi-face features and align them with landmarks, which improves ID fidelity and face control. In addition, we devise an automated pipeline to construct an ID-based dataset for training HiFi-Portrait. Extensive experimental results demonstrate that our method surpasses the SOTA approaches in face similarity and controllability. Furthermore, our method is also compatible with previous SDXL-based works.
ViDA-UGC: Detailed Image Quality Analysis via Visual Distortion Assessment for UGC Images
Aug 18, 2025Recent advances in Multimodal Large Language Models (MLLMs) have introduced a paradigm shift for Image Quality Assessment (IQA) from unexplainable image quality scoring to explainable IQA, demonstrating practical applications like quality control and optimization guidance. However, current explainable IQA methods not only inadequately use the same distortion criteria to evaluate both User-Generated Content (UGC) and AI-Generated Content (AIGC) images, but also lack detailed quality analysis for monitoring image quality and guiding image restoration. In this study, we establish the first large-scale Visual Distortion Assessment Instruction Tuning Dataset for UGC images, termed ViDA-UGC, which comprises 11K images with fine-grained quality grounding, detailed quality perception, and reasoning quality description data. This dataset is constructed through a distortion-oriented pipeline, which involves human subject annotation and a Chain-of-Thought (CoT) assessment framework. This framework guides GPT-4o to generate quality descriptions by identifying and analyzing UGC distortions, which helps capturing rich low-level visual features that inherently correlate with distortion patterns. Moreover, we carefully select 476 images with corresponding 6,149 question answer pairs from ViDA-UGC and invite a professional team to ensure the accuracy and quality of GPT-generated information. The selected and revised data further contribute to the first UGC distortion assessment benchmark, termed ViDA-UGC-Bench. Experimental results demonstrate the effectiveness of the ViDA-UGC and CoT framework for consistently enhancing various image quality analysis abilities across multiple base MLLMs on ViDA-UGC-Bench and Q-Bench, even surpassing GPT-4o.
Multi-modal Fusion and Query Refinement Network for Video Moment Retrieval and Highlight Detection
Jan 18, 2025



Given a video and a linguistic query, video moment retrieval and highlight detection (MR&HD) aim to locate all the relevant spans while simultaneously predicting saliency scores. Most existing methods utilize RGB images as input, overlooking the inherent multi-modal visual signals like optical flow and depth. In this paper, we propose a Multi-modal Fusion and Query Refinement Network (MRNet) to learn complementary information from multi-modal cues. Specifically, we design a multi-modal fusion module to dynamically combine RGB, optical flow, and depth map. Furthermore, to simulate human understanding of sentences, we introduce a query refinement module that merges text at different granularities, containing word-, phrase-, and sentence-wise levels. Comprehensive experiments on QVHighlights and Charades datasets indicate that MRNet outperforms current state-of-the-art methods, achieving notable improvements in MR-mAP@Avg (+3.41) and HD-HIT@1 (+3.46) on QVHighlights.
Zero-shot Video Moment Retrieval via Off-the-shelf Multimodal Large Language Models
Jan 14, 2025



The target of video moment retrieval (VMR) is predicting temporal spans within a video that semantically match a given linguistic query. Existing VMR methods based on multimodal large language models (MLLMs) overly rely on expensive high-quality datasets and time-consuming fine-tuning. Although some recent studies introduce a zero-shot setting to avoid fine-tuning, they overlook inherent language bias in the query, leading to erroneous localization. To tackle the aforementioned challenges, this paper proposes Moment-GPT, a tuning-free pipeline for zero-shot VMR utilizing frozen MLLMs. Specifically, we first employ LLaMA-3 to correct and rephrase the query to mitigate language bias. Subsequently, we design a span generator combined with MiniGPT-v2 to produce candidate spans adaptively. Finally, to leverage the video comprehension capabilities of MLLMs, we apply VideoChatGPT and span scorer to select the most appropriate spans. Our proposed method substantially outperforms the state-ofthe-art MLLM-based and zero-shot models on several public datasets, including QVHighlights, ActivityNet-Captions, and Charades-STA.
NTIRE 2024 Challenge on Short-form UGC Video Quality Assessment: Methods and Results
Apr 17, 2024



This paper reviews the NTIRE 2024 Challenge on Shortform UGC Video Quality Assessment (S-UGC VQA), where various excellent solutions are submitted and evaluated on the collected dataset KVQ from popular short-form video platform, i.e., Kuaishou/Kwai Platform. The KVQ database is divided into three parts, including 2926 videos for training, 420 videos for validation, and 854 videos for testing. The purpose is to build new benchmarks and advance the development of S-UGC VQA. The competition had 200 participants and 13 teams submitted valid solutions for the final testing phase. The proposed solutions achieved state-of-the-art performances for S-UGC VQA. The project can be found at https://github.com/lixinustc/KVQChallenge-CVPR-NTIRE2024.
GPTSee: Enhancing Moment Retrieval and Highlight Detection via Description-Based Similarity Features
Mar 10, 2024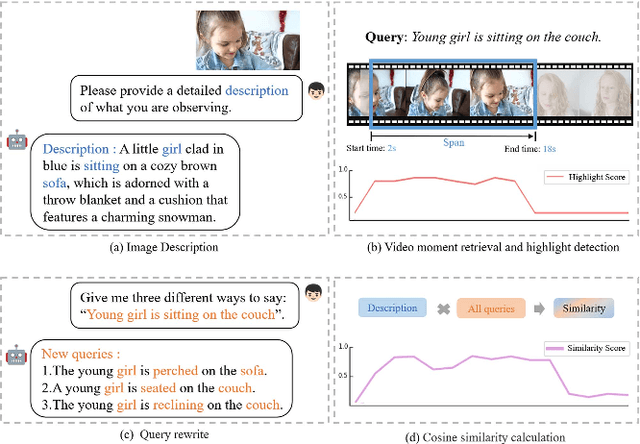
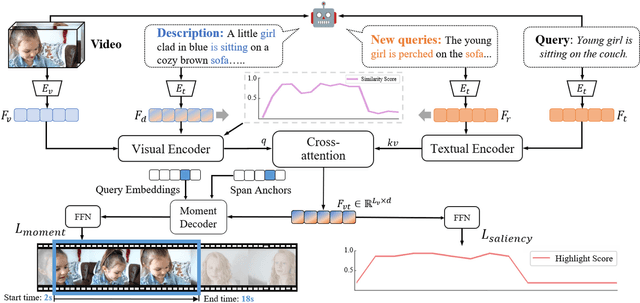
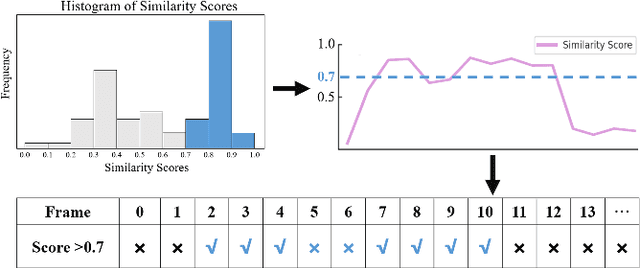
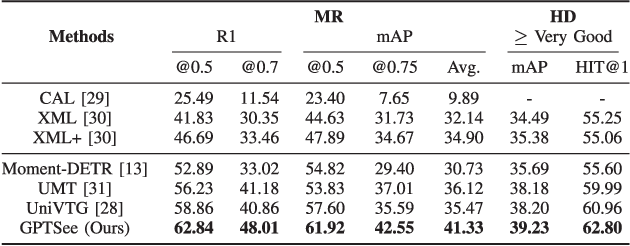
Moment retrieval (MR) and highlight detection (HD) aim to identify relevant moments and highlights in video from corresponding natural language query. Large language models (LLMs) have demonstrated proficiency in various computer vision tasks. However, existing methods for MR\&HD have not yet been integrated with LLMs. In this letter, we propose a novel two-stage model that takes the output of LLMs as the input to the second-stage transformer encoder-decoder. First, MiniGPT-4 is employed to generate the detailed description of the video frame and rewrite the query statement, fed into the encoder as new features. Then, semantic similarity is computed between the generated description and the rewritten queries. Finally, continuous high-similarity video frames are converted into span anchors, serving as prior position information for the decoder. Experiments demonstrate that our approach achieves a state-of-the-art result, and by using only span anchors and similarity scores as outputs, positioning accuracy outperforms traditional methods, like Moment-DETR.
VTG-GPT: Tuning-Free Zero-Shot Video Temporal Grounding with GPT
Mar 04, 2024
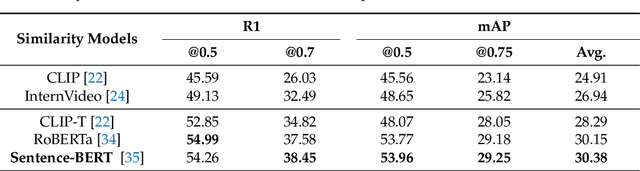

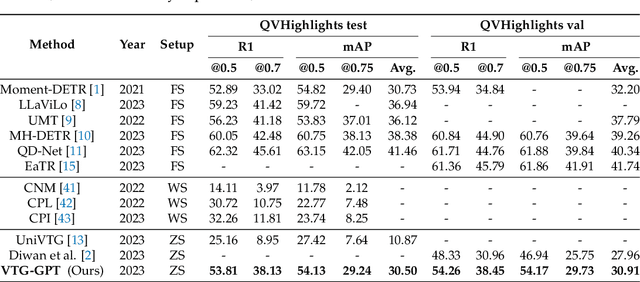
Video temporal grounding (VTG) aims to locate specific temporal segments from an untrimmed video based on a linguistic query. Most existing VTG models are trained on extensive annotated video-text pairs, a process that not only introduces human biases from the queries but also incurs significant computational costs. To tackle these challenges, we propose VTG-GPT, a GPT-based method for zero-shot VTG without training or fine-tuning. To reduce prejudice in the original query, we employ Baichuan2 to generate debiased queries. To lessen redundant information in videos, we apply MiniGPT-v2 to transform visual content into more precise captions. Finally, we devise the proposal generator and post-processing to produce accurate segments from debiased queries and image captions. Extensive experiments demonstrate that VTG-GPT significantly outperforms SOTA methods in zero-shot settings and surpasses unsupervised approaches. More notably, it achieves competitive performance comparable to supervised methods. The code is available on https://github.com/YoucanBaby/VTG-GPT