 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Fusion and Query Refinement Network for Video Moment Retrieval and Highlight Detection
Jan 18, 2025



Given a video and a linguistic query, video moment retrieval and highlight detection (MR&HD) aim to locate all the relevant spans while simultaneously predicting saliency scores. Most existing methods utilize RGB images as input, overlooking the inherent multi-modal visual signals like optical flow and depth. In this paper, we propose a Multi-modal Fusion and Query Refinement Network (MRNet) to learn complementary information from multi-modal cues. Specifically, we design a multi-modal fusion module to dynamically combine RGB, optical flow, and depth map. Furthermore, to simulate human understanding of sentences, we introduce a query refinement module that merges text at different granularities, containing word-, phrase-, and sentence-wise levels. Comprehensive experiments on QVHighlights and Charades datasets indicate that MRNet outperforms current state-of-the-art methods, achieving notable improvements in MR-mAP@Avg (+3.41) and HD-HIT@1 (+3.46) on QVHighlights.
GPTSee: Enhancing Moment Retrieval and Highlight Detection via Description-Based Similarity Features
Mar 10, 2024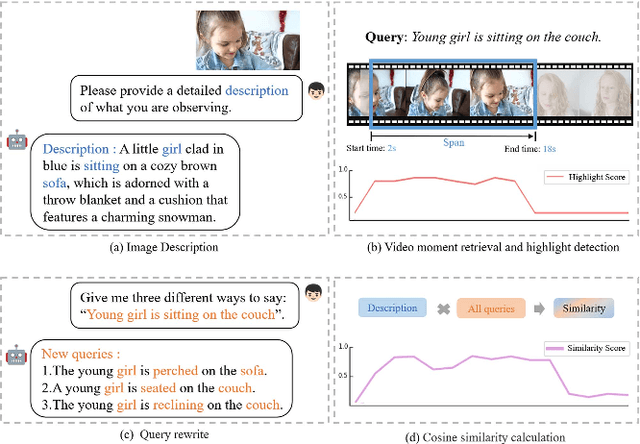
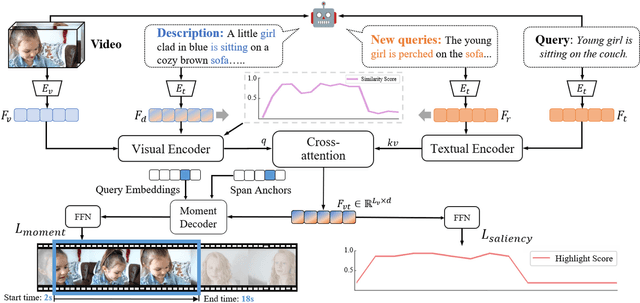
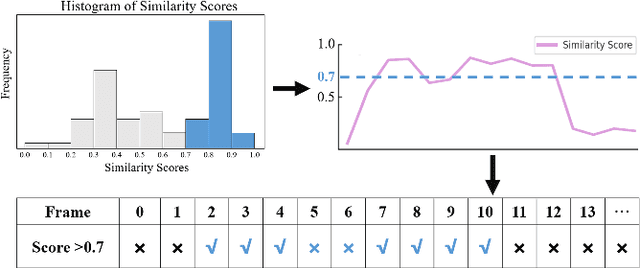
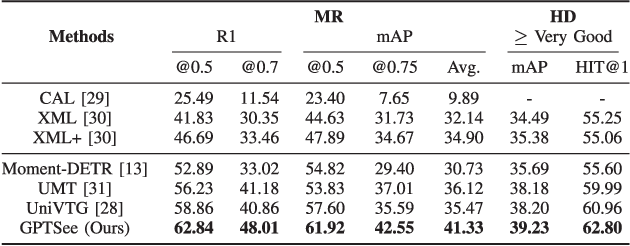
Moment retrieval (MR) and highlight detection (HD) aim to identify relevant moments and highlights in video from corresponding natural language query. Large language models (LLMs) have demonstrated proficiency in various computer vision tasks. However, existing methods for MR\&HD have not yet been integrated with LLMs. In this letter, we propose a novel two-stage model that takes the output of LLMs as the input to the second-stage transformer encoder-decoder. First, MiniGPT-4 is employed to generate the detailed description of the video frame and rewrite the query statement, fed into the encoder as new features. Then, semantic similarity is computed between the generated description and the rewritten queries. Finally, continuous high-similarity video frames are converted into span anchors, serving as prior position information for the decoder. Experiments demonstrate that our approach achieves a state-of-the-art result, and by using only span anchors and similarity scores as outputs, positioning accuracy outperforms traditional methods, like Moment-DETR.
VTG-GPT: Tuning-Free Zero-Shot Video Temporal Grounding with GPT
Mar 04, 2024
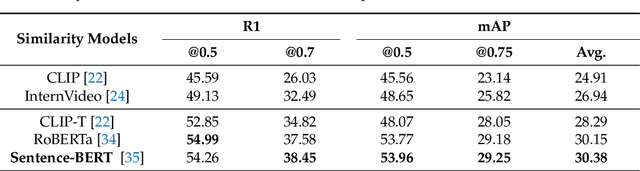

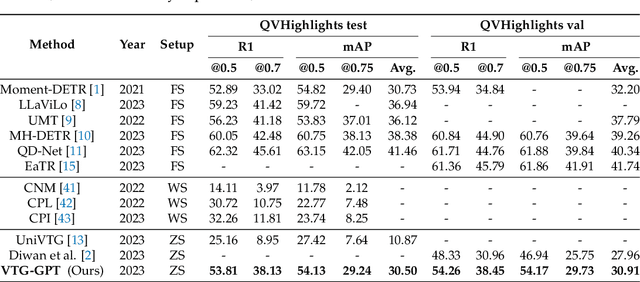
Video temporal grounding (VTG) aims to locate specific temporal segments from an untrimmed video based on a linguistic query. Most existing VTG models are trained on extensive annotated video-text pairs, a process that not only introduces human biases from the queries but also incurs significant computational costs. To tackle these challenges, we propose VTG-GPT, a GPT-based method for zero-shot VTG without training or fine-tuning. To reduce prejudice in the original query, we employ Baichuan2 to generate debiased queries. To lessen redundant information in videos, we apply MiniGPT-v2 to transform visual content into more precise captions. Finally, we devise the proposal generator and post-processing to produce accurate segments from debiased queries and image captions. Extensive experiments demonstrate that VTG-GPT significantly outperforms SOTA methods in zero-shot settings and surpasses unsupervised approaches. More notably, it achieves competitive performance comparable to supervised methods. The code is available on https://github.com/YoucanBaby/VTG-GPT