 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplit-Layer: Enhancing Implicit Neural Representation by Maximizing the Dimensionality of Feature Space
Nov 13, 2025Implicit neural representation (INR) models signals as continuous functions using neural networks, offering efficient and differentiable optimization for inverse problems across diverse disciplines. However, the representational capacity of INR defined by the range of functions the neural network can characterize, is inherently limited by the low-dimensional feature space in conventional multilayer perceptron (MLP) architectures. While widening the MLP can linearly increase feature space dimensionality, it also leads to a quadratic growth in computational and memory costs. To address this limitation, we propose the split-layer, a novel reformulation of MLP construction. The split-layer divides each layer into multiple parallel branches and integrates their outputs via Hadamard product, effectively constructing a high-degree polynomial space. This approach significantly enhances INR's representational capacity by expanding the feature space dimensionality without incurring prohibitive computational overhead. Extensive experiments demonstrate that the split-layer substantially improves INR performance, surpassing existing methods across multiple tasks, including 2D image fitting, 2D CT reconstruction, 3D shape representation, and 5D novel view synthesis.
FLEX: Continuous Agent Evolution via Forward Learning from Experience
Nov 09, 2025Autonomous agents driven by Large Language Models (LLMs) have revolutionized reasoning and problem-solving but remain static after training, unable to grow with experience as intelligent beings do during deployment. We introduce Forward Learning with EXperience (FLEX), a gradient-free learning paradigm that enables LLM agents to continuously evolve through accumulated experience. Specifically, FLEX cultivates scalable and inheritable evolution by constructing a structured experience library through continual reflection on successes and failures during interaction with the environment. FLEX delivers substantial improvements on mathematical reasoning, chemical retrosynthesis, and protein fitness prediction (up to 23% on AIME25, 10% on USPTO50k, and 14% on ProteinGym). We further identify a clear scaling law of experiential growth and the phenomenon of experience inheritance across agents, marking a step toward scalable and inheritable continuous agent evolution. Project Page: https://flex-gensi-thuair.github.io.
Enigmata: Scaling Logical Reasoning in Large Language Models with Synthetic Verifiable Puzzles
May 26, 2025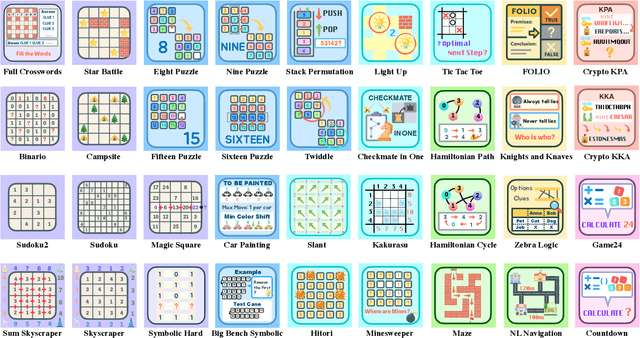
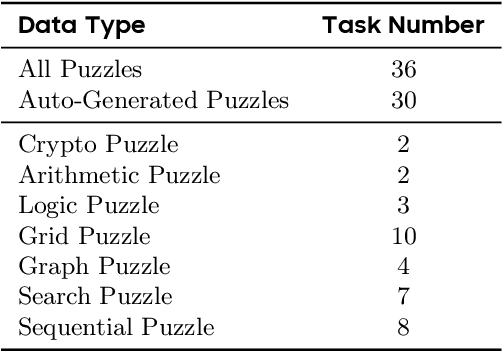

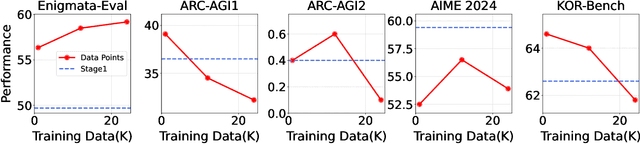
Large Language Models (LLMs), such as OpenAI's o1 and DeepSeek's R1, excel at advanced reasoning tasks like math and coding via Reinforcement Learning with Verifiable Rewards (RLVR), but still struggle with puzzles solvable by humans without domain knowledge. We introduce Enigmata, the first comprehensive suite tailored for improving LLMs with puzzle reasoning skills. It includes 36 tasks across seven categories, each with 1) a generator that produces unlimited examples with controllable difficulty and 2) a rule-based verifier for automatic evaluation. This generator-verifier design supports scalable, multi-task RL training, fine-grained analysis, and seamless RLVR integration. We further propose Enigmata-Eval, a rigorous benchmark, and develop optimized multi-task RLVR strategies. Our trained model, Qwen2.5-32B-Enigmata, consistently surpasses o3-mini-high and o1 on the puzzle reasoning benchmarks like Enigmata-Eval, ARC-AGI (32.8%), and ARC-AGI 2 (0.6%). It also generalizes well to out-of-domain puzzle benchmarks and mathematical reasoning, with little multi-tasking trade-off. When trained on larger models like Seed1.5-Thinking (20B activated parameters and 200B total parameters), puzzle data from Enigmata further boosts SoTA performance on advanced math and STEM reasoning tasks such as AIME (2024-2025), BeyondAIME and GPQA (Diamond), showing nice generalization benefits of Enigmata. This work offers a unified, controllable framework for advancing logical reasoning in LLMs. Resources of this work can be found at https://seed-enigmata.github.io.
Towards the Spectral bias Alleviation by Normalizations in Coordinate Networks
Jul 25, 2024



Representing signals using coordinate networks dominates the area of inverse problems recently, and is widely applied in various scientific computing tasks. Still, there exists an issue of spectral bias in coordinate networks, limiting the capacity to learn high-frequency components. This problem is caused by the pathological distribution of the neural tangent kernel's (NTK's) eigenvalues of coordinate networks. We find that, this pathological distribution could be improved using classical normalization techniques (batch normalization and layer normalization), which are commonly used in convolutional neural networks but rarely used in coordinate networks. We prove that normalization techniques greatly reduces the maximum and variance of NTK's eigenvalues while slightly modifies the mean value, considering the max eigenvalue is much larger than the most, this variance change results in a shift of eigenvalues' distribution from a lower one to a higher one, therefore the spectral bias could be alleviated. Furthermore, we propose two new normalization techniques by combining these two techniques in different ways. The efficacy of these normalization techniques is substantiated by the significant improvements and new state-of-the-arts achieved by applying normalization-based coordinate networks to various tasks, including the image compression, computed tomography reconstruction, shape representation, magnetic resonance imaging, novel view synthesis and multi-view stereo reconstruction.
Conv-INR: Convolutional Implicit Neural Representation for Multimodal Visual Signals
Jun 06, 2024



Implicit neural representation (INR) has recently emerged as a promising paradigm for signal representations. Typically, INR is parameterized by a multiplayer perceptron (MLP) which takes the coordinates as the inputs and generates corresponding attributes of a signal. However, MLP-based INRs face two critical issues: i) individually considering each coordinate while ignoring the connections; ii) suffering from the spectral bias thus failing to learn high-frequency components. While target visual signals usually exhibit strong local structures and neighborhood dependencies, and high-frequency components are significant in these signals, the issues harm the representational capacity of INRs. This paper proposes Conv-INR, the first INR model fully based on convolution. Due to the inherent attributes of convolution, Conv-INR can simultaneously consider adjacent coordinates and learn high-frequency components effectively. Compared to existing MLP-based INRs, Conv-INR has better representational capacity and trainability without requiring primary function expansion. We conduct extensive experiments on four tasks, including image fitting, CT/MRI reconstruction, and novel view synthesis, Conv-INR all significantly surpasses existing MLP-based INRs, validating the effectiveness. Finally, we raise three reparameterization methods that can further enhance the performance of the vanilla Conv-INR without introducing any extra inference cost.
Encoding Semantic Priors into the Weights of Implicit Neural Representation
Jun 06, 2024
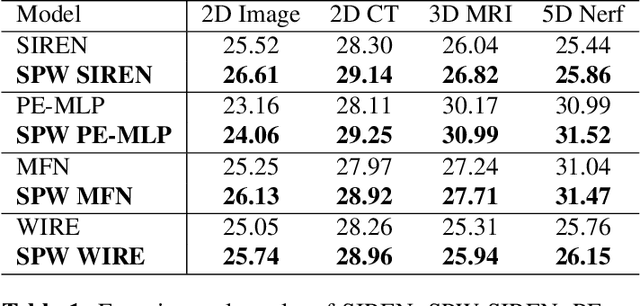


Implicit neural representation (INR) has recently emerged as a promising paradigm for signal representations, which takes coordinates as inputs and generates corresponding signal values. Since these coordinates contain no semantic features, INR fails to take any semantic information into consideration. However, semantic information has been proven critical in many vision tasks, especially for visual signal representation. This paper proposes a reparameterization method termed as SPW, which encodes the semantic priors to the weights of INR, thus making INR contain semantic information implicitly and enhancing its representational capacity. Specifically, SPW uses the Semantic Neural Network (SNN) to extract both low- and high-level semantic information of the target visual signal and generates the semantic vector, which is input into the Weight Generation Network (WGN) to generate the weights of INR model. Finally, INR uses the generated weights with semantic priors to map the coordinates to the signal values. After training, we only retain the generated weights while abandoning both SNN and WGN, thus SPW introduces no extra costs in inference. Experimental results show that SPW can improve the performance of various INR models significantly on various tasks, including image fitting, CT reconstruction, MRI reconstruction, and novel view synthesis. Further experiments illustrate that model with SPW has lower weight redundancy and learns more novel representations, validating the effectiveness of SPW.
RefConv: Re-parameterized Refocusing Convolution for Powerful ConvNets
Oct 16, 2023We propose Re-parameterized Refocusing Convolution (RefConv) as a replacement for regular convolutional layers, which is a plug-and-play module to improve the performance without any inference costs. Specifically, given a pre-trained model, RefConv applies a trainable Refocusing Transformation to the basis kernels inherited from the pre-trained model to establish connections among the parameters. For example, a depth-wise RefConv can relate the parameters of a specific channel of convolution kernel to the parameters of the other kernel, i.e., make them refocus on the other parts of the model they have never attended to, rather than focus on the input features only. From another perspective, RefConv augments the priors of existing model structures by utilizing the representations encoded in the pre-trained parameters as the priors and refocusing on them to learn novel representations, thus further enhancing the representational capacity of the pre-trained model. Experimental results validated that RefConv can improve multiple CNN-based models by a clear margin on image classification (up to 1.47% higher top-1 accuracy on ImageNet), object detection and semantic segmentation without introducing any extra inference costs or altering the original model structure. Further studies demonstrated that RefConv can reduce the redundancy of channels and smooth the loss landscape, which explains its effectiveness.
X-MLP: A Patch Embedding-Free MLP Architecture for Vision
Jul 02, 2023


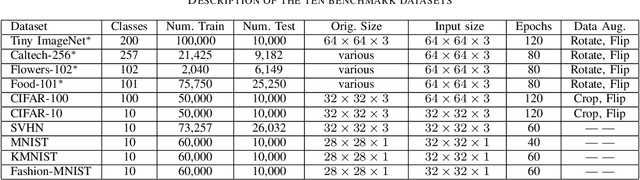
Convolutional neural networks (CNNs) and vision transformers (ViT) have obtained great achievements in computer vision. Recently, the research of multi-layer perceptron (MLP) architectures for vision have been popular again. Vision MLPs are designed to be independent from convolutions and self-attention operations. However, existing vision MLP architectures always depend on convolution for patch embedding. Thus we propose X-MLP, an architecture constructed absolutely upon fully connected layers and free from patch embedding. It decouples the features extremely and utilizes MLPs to interact the information across the dimension of width, height and channel independently and alternately. X-MLP is tested on ten benchmark datasets, all obtaining better performance than other vision MLP models. It even surpasses CNNs by a clear margin on various dataset. Furthermore, through mathematically restoring the spatial weights, we visualize the information communication between any couples of pixels in the feature map and observe the phenomenon of capturing long-range dependency.
Learn to Enhance the Negative Information in Convolutional Neural Network
Jun 18, 2023This paper proposes a learnable nonlinear activation mechanism specifically for convolutional neural network (CNN) termed as LENI, which learns to enhance the negative information in CNNs. In sharp contrast to ReLU which cuts off the negative neurons and suffers from the issue of ''dying ReLU'', LENI enjoys the capacity to reconstruct the dead neurons and reduce the information loss. Compared to improved ReLUs, LENI introduces a learnable approach to process the negative phase information more properly. In this way, LENI can enhance the model representational capacity significantly while maintaining the original advantages of ReLU. As a generic activation mechanism, LENI possesses the property of portability and can be easily utilized in any CNN models through simply replacing the activation layers with LENI block. Extensive experiments validate that LENI can improve the performance of various baseline models on various benchmark datasets by a clear margin (up to 1.24% higher top-1 accuracy on ImageNet-1k) with negligible extra parameters. Further experiments show that LENI can act as a channel compensation mechanism, offering competitive or even better performance but with fewer learned parameters than baseline models. In addition, LENI introduces the asymmetry to the model structure which contributes to the enhancement of representational capacity. Through visualization experiments, we validate that LENI can retain more information and learn more representations.
FalconNet: Factorization for the Light-weight ConvNets
Jun 10, 2023Designing light-weight CNN models with little parameters and Flops is a prominent research concern. However, three significant issues persist in the current light-weight CNNs: i) the lack of architectural consistency leads to redundancy and hindered capacity comparison, as well as the ambiguity in causation between architectural choices and performance enhancement; ii) the utilization of a single-branch depth-wise convolution compromises the model representational capacity; iii) the depth-wise convolutions account for large proportions of parameters and Flops, while lacking efficient method to make them light-weight. To address these issues, we factorize the four vital components of light-weight CNNs from coarse to fine and redesign them: i) we design a light-weight overall architecture termed LightNet, which obtains better performance by simply implementing the basic blocks of other light-weight CNNs; ii) we abstract a Meta Light Block, which consists of spatial operator and channel operator and uniformly describes current basic blocks; iii) we raise RepSO which constructs multiple spatial operator branches to enhance the representational ability; iv) we raise the concept of receptive range, guided by which we raise RefCO to sparsely factorize the channel operator. Based on above four vital components, we raise a novel light-weight CNN model termed as FalconNet. Experimental results validate that FalconNet can achieve higher accuracy with lower number of parameters and Flops compared to existing light-weight CNNs.