 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$AutoDrive\text{-}P^3$: Unified Chain of Perception-Prediction-Planning Thought via Reinforcement Fine-Tuning
Mar 30, 2026Vision-language models (VLMs) are increasingly being adopted for end-to-end autonomous driving systems due to their exceptional performance in handling long-tail scenarios. However, current VLM-based approaches suffer from two major limitations: 1) Some VLMs directly output planning results without chain-of-thought (CoT) reasoning, bypassing crucial perception and prediction stages which creates a significant domain gap and compromises decision-making capability; 2) Other VLMs can generate outputs for perception, prediction, and planning tasks but employ a fragmented decision-making approach where these modules operate separately, leading to a significant lack of synergy that undermines true planning performance. To address these limitations, we propose ${AutoDrive\text{-}P^3}$, a novel framework that seamlessly integrates $\textbf{P}$erception, $\textbf{P}$rediction, and $\textbf{P}$lanning through structured reasoning. We introduce the ${P^3\text{-}CoT}$ dataset to facilitate coherent reasoning and propose ${P^3\text{-}GRPO}$, a hierarchical reinforcement learning algorithm that provides progressive supervision across all three tasks. Specifically, ${AutoDrive\text{-}P^3}$ progressively generates CoT reasoning and answers for perception, prediction, and planning, where perception provides essential information for subsequent prediction and planning, while both perception and prediction collectively contribute to the final planning decisions, enabling safer and more interpretable autonomous driving. Additionally, to balance inference efficiency with performance, we introduce dual thinking modes: detailed thinking and fast thinking. Extensive experiments on both open-loop (nuScenes) and closed-loop (NAVSIMv1/v2) benchmarks demonstrate that our approach achieves state-of-the-art performance in planning tasks. Code is available at https://github.com/haha-yuki-haha/AutoDrive-P3.
RP-CATE: Recurrent Perceptron-based Channel Attention Transformer Encoder for Industrial Hybrid Modeling
Dec 22, 2025Nowadays, industrial hybrid modeling which integrates both mechanistic modeling and machine learning-based modeling techniques has attracted increasing interest from scholars due to its high accuracy, low computational cost, and satisfactory interpretability. Nevertheless, the existing industrial hybrid modeling methods still face two main limitations. First, current research has mainly focused on applying a single machine learning method to one specific task, failing to develop a comprehensive machine learning architecture suitable for modeling tasks, which limits their ability to effectively represent complex industrial scenarios. Second, industrial datasets often contain underlying associations (e.g., monotonicity or periodicity) that are not adequately exploited by current research, which can degrade model's predictive performance. To address these limitations, this paper proposes the Recurrent Perceptron-based Channel Attention Transformer Encoder (RP-CATE), with three distinctive characteristics: 1: We developed a novel architecture by replacing the self-attention mechanism with channel attention and incorporating our proposed Recurrent Perceptron (RP) Module into Transformer, achieving enhanced effectiveness for industrial modeling tasks compared to the original Transformer. 2: We proposed a new data type called Pseudo-Image Data (PID) tailored for channel attention requirements and developed a cyclic sliding window method for generating PID. 3: We introduced the concept of Pseudo-Sequential Data (PSD) and a method for converting industrial datasets into PSD, which enables the RP Module to capture the underlying associations within industrial dataset more effectively. An experiment aimed at hybrid modeling in chemical engineering was conducted by using RP-CATE and the experimental results demonstrate that RP-CATE achieves the best performance compared to other baseline models.
Generalized Gaussian Entropy Model for Point Cloud Attribute Compression with Dynamic Likelihood Intervals
Jun 11, 2025Gaussian and Laplacian entropy models are proved effective in learned point cloud attribute compression, as they assist in arithmetic coding of latents. However, we demonstrate through experiments that there is still unutilized information in entropy parameters estimated by neural networks in current methods, which can be used for more accurate probability estimation. Thus we introduce generalized Gaussian entropy model, which controls the tail shape through shape parameter to more accurately estimate the probability of latents. Meanwhile, to the best of our knowledge, existing methods use fixed likelihood intervals for each integer during arithmetic coding, which limits model performance. We propose Mean Error Discriminator (MED) to determine whether the entropy parameter estimation is accurate and then dynamically adjust likelihood intervals. Experiments show that our method significantly improves rate-distortion (RD) performance on three VAE-based models for point cloud attribute compression, and our method can be applied to other compression tasks, such as image and video compression.
SCNR Maximization for MIMO ISAC Assisted by Fluid Antenna System
Apr 02, 2025The integrated sensing and communication (ISAC) technology has been extensively researched to enhance communication rates and radar sensing capabilities. Additionally, a new technology known as fluid antenna system (FAS) has recently been proposed to obtain higher communication rates for future wireless networks by dynamically altering the antenna position to obtain a more favorable channel condition. The application of the FAS technology in ISAC scenarios holds significant research potential. In this paper, we investigate a FAS-assisted multiple-input multiple-output (MIMO) ISAC system for maximizing the radar sensing signal-clutter-noise ratio (SCNR) under communication signal-to-interference-plus-noise ratio (SINR) and antenna position constraints. We devise an iterative algorithm that tackles the optimization problem by maximizing a lower bound of SCNR with respect to the transmit precoding matrix and the antenna position. By addressing the non-convexity of the problem through this iterative approach, our method significantly improves the SCNR. Our simulation results demonstrate that the proposed scheme achieves a higher SCNR compared to the baselines.
LLM-PCGC: Large Language Model-based Point Cloud Geometry Compression
Aug 16, 2024
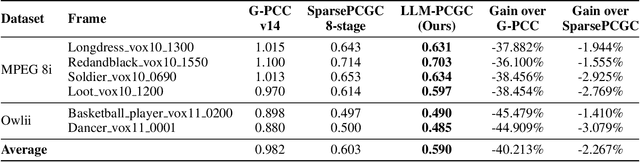
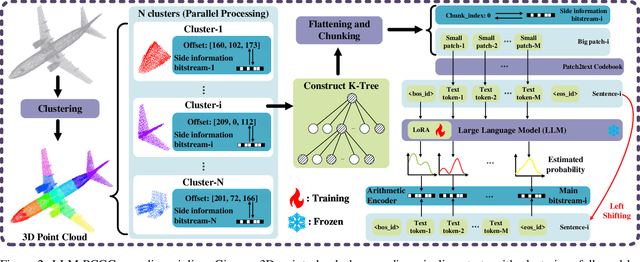

The key to effective point cloud compression is to obtain a robust context model consistent with complex 3D data structures. Recently, the advancement of large language models (LLMs) has highlighted their capabilities not only as powerful generators for in-context learning and generation but also as effective compressors. These dual attributes of LLMs make them particularly well-suited to meet the demands of data compression. Therefore, this paper explores the potential of using LLM for compression tasks, focusing on lossless point cloud geometry compression (PCGC) experiments. However, applying LLM directly to PCGC tasks presents some significant challenges, i.e., LLM does not understand the structure of the point cloud well, and it is a difficult task to fill the gap between text and point cloud through text description, especially for large complicated and small shapeless point clouds. To address these problems, we introduce a novel architecture, namely the Large Language Model-based Point Cloud Geometry Compression (LLM-PCGC) method, using LLM to compress point cloud geometry information without any text description or aligning operation. By utilizing different adaptation techniques for cross-modality representation alignment and semantic consistency, including clustering, K-tree, token mapping invariance, and Low Rank Adaptation (LoRA), the proposed method can translate LLM to a compressor/generator for point cloud. To the best of our knowledge, this is the first structure to employ LLM as a compressor for point cloud data. Experiments demonstrate that the LLM-PCGC outperforms the other existing methods significantly, by achieving -40.213% bit rate reduction compared to the reference software of MPEG Geometry-based Point Cloud Compression (G-PCC) standard, and by achieving -2.267% bit rate reduction compared to the state-of-the-art learning-based method.
A Survey on Multilingual Large Language Models: Corpora, Alignment, and Bias
Apr 01, 2024Based on the foundation of Large Language Models (LLMs), Multilingual Large Language Models (MLLMs) have been developed to address the challenges of multilingual natural language processing tasks, hoping to achieve knowledge transfer from high-resource to low-resource languages. However, significant limitations and challenges still exist, such as language imbalance, multilingual alignment, and inherent bias. In this paper, we aim to provide a comprehensive analysis of MLLMs, delving deeply into discussions surrounding these critical issues. First of all, we start by presenting an overview of MLLMs, covering their evolution, key techniques, and multilingual capacities. Secondly, we explore widely utilized multilingual corpora for MLLMs' training and multilingual datasets oriented for downstream tasks that are crucial for enhancing the cross-lingual capability of MLLMs. Thirdly, we survey the existing studies on multilingual representations and investigate whether the current MLLMs can learn a universal language representation. Fourthly, we discuss bias on MLLMs including its category and evaluation metrics, and summarize the existing debiasing techniques. Finally, we discuss existing challenges and point out promising research directions. By demonstrating these aspects, this paper aims to facilitate a deeper understanding of MLLMs and their potentiality in various domains.
Fluid Antenna-Assisted MIMO Transmission Exploiting Statistical CSI
Dec 13, 2023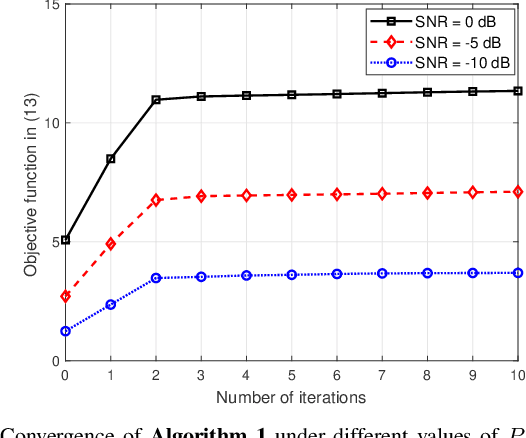
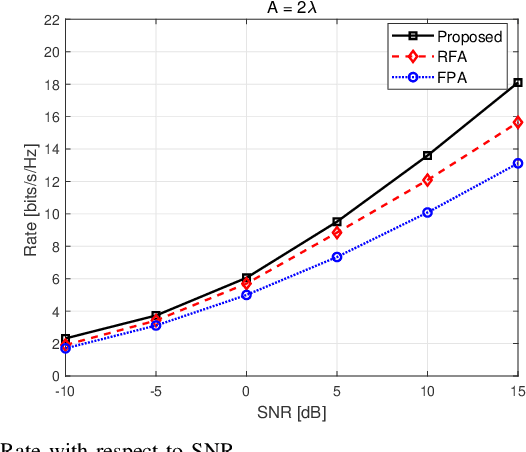
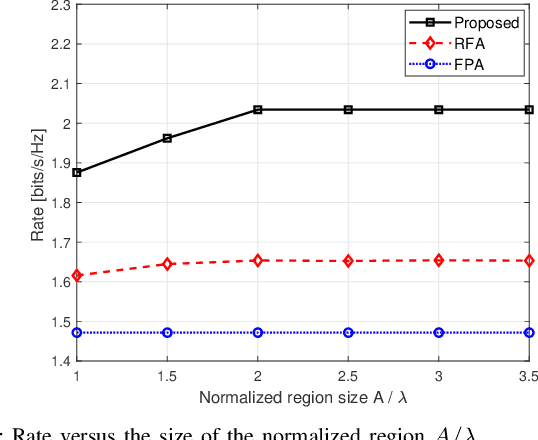
In conventional multiple-input multiple-output (MIMO) communication systems, the positions of antennas are fixed. To take full advantage of spatial degrees of freedom, a new technology called fluid antenna (FA) is proposed to obtain higher achievable rate and diversity gain. Most existing works on FA exploit instantaneous channel state information (CSI). However, in FA-assisted systems, it is difficult to obtain instantaneous CSI since changes in the antenna position will lead to channel variation. In this letter, we investigate a FA-assisted MIMO system using relatively slow-varying statistical CSI. Specifically, in the criterion of rate maximization, we propose an algorithmic framework for transmit precoding and transmit/receive FAs position designs with statistical CSI. Simulation results show that our proposed algorithm in FA-assisted systems significantly outperforms baselines in terms of rate performance.