 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCloudMatch: Weak-to-Strong Consistency Learning for Semi-Supervised Cloud Detection
Jan 07, 2026Due to the high cost of annotating accurate pixel-level labels, semi-supervised learning has emerged as a promising approach for cloud detection. In this paper, we propose CloudMatch, a semi-supervised framework that effectively leverages unlabeled remote sensing imagery through view-consistency learning combined with scene-mixing augmentations. An observation behind CloudMatch is that cloud patterns exhibit structural diversity and contextual variability across different scenes and within the same scene category. Our key insight is that enforcing prediction consistency across diversely augmented views, incorporating both inter-scene and intra-scene mixing, enables the model to capture the structural diversity and contextual richness of cloud patterns. Specifically, CloudMatch generates one weakly augmented view along with two complementary strongly augmented views for each unlabeled image: one integrates inter-scene patches to simulate contextual variety, while the other employs intra-scene mixing to preserve semantic coherence. This approach guides pseudolabel generation and enhances generalization. Extensive experiments show that CloudMatch achieves good performance, demonstrating its capability to utilize unlabeled data efficiently and advance semi-supervised cloud detection.
CD-Mamba: Cloud detection with long-range spatial dependency modeling
Sep 05, 2025
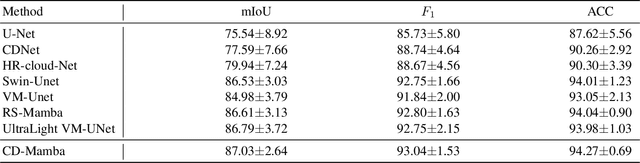
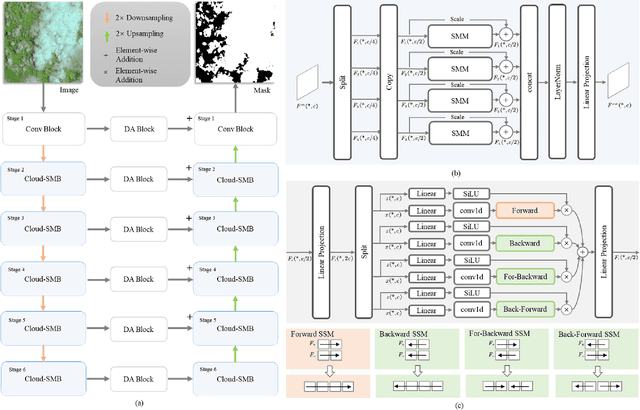
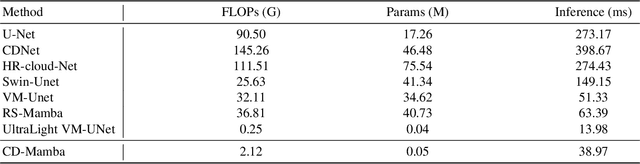
Remote sensing images are frequently obscured by cloud cover, posing significant challenges to data integrity and reliability. Effective cloud detection requires addressing both short-range spatial redundancies and long-range atmospheric similarities among cloud patches. Convolutional neural networks are effective at capturing local spatial dependencies, while Mamba has strong capabilities in modeling long-range dependencies. To fully leverage both local spatial relations and long-range dependencies, we propose CD-Mamba, a hybrid model that integrates convolution and Mamba's state-space modeling into a unified cloud detection network. CD-Mamba is designed to comprehensively capture pixelwise textural details and long term patchwise dependencies for cloud detection. This design enables CD-Mamba to manage both pixel-wise interactions and extensive patch-wise dependencies simultaneously, improving detection accuracy across diverse spatial scales. Extensive experiments validate the effectiveness of CD-Mamba and demonstrate its superior performance over existing methods.
Zero-shot Generalist Graph Anomaly Detection with Unified Neighborhood Prompts
Oct 18, 2024



Graph anomaly detection (GAD), which aims to identify nodes in a graph that significantly deviate from normal patterns, plays a crucial role in broad application domains. Existing GAD methods, whether supervised or unsupervised, are one-model-for-one-dataset approaches, i.e., training a separate model for each graph dataset. This limits their applicability in real-world scenarios where training on the target graph data is not possible due to issues like data privacy. To overcome this limitation, we propose a novel zero-shot generalist GAD approach UNPrompt that trains a one-for-all detection model, requiring the training of one GAD model on a single graph dataset and then effectively generalizing to detect anomalies in other graph datasets without any retraining or fine-tuning. The key insight in UNPrompt is that i) the predictability of latent node attributes can serve as a generalized anomaly measure and ii) highly generalized normal and abnormal graph patterns can be learned via latent node attribute prediction in a properly normalized node attribute space. UNPrompt achieves generalist GAD through two main modules: one module aligns the dimensionality and semantics of node attributes across different graphs via coordinate-wise normalization in a projected space, while another module learns generalized neighborhood prompts that support the use of latent node attribute predictability as an anomaly score across different datasets. Extensive experiments on real-world GAD datasets show that UNPrompt significantly outperforms diverse competing methods under the generalist GAD setting, and it also has strong superiority under the one-model-for-one-dataset setting.
Generative approach to unsupervised deep local learning
Jun 28, 2019Most existing feature learning methods optimize inflexible handcrafted features and the affinity matrix is constructed by shallow linear embedding methods. Different from these conventional methods, we pretrain a generative neural network by stacking convolutional autoencoders to learn the latent data representation and then construct an affinity graph with them as a prior. Based on the pretrained model and the constructed graph, we add a self-expressive layer to complete the generative model and then fine-tune it with a new loss function, including the reconstruction loss and a deliberately defined locality-preserving loss. The locality-preserving loss designed by the constructed affinity graph serves as prior to preserve the local structure during the fine-tuning stage, which in turn improves the quality of feature representation effectively. Furthermore, the self-expressive layer between the encoder and decoder is based on the assumption that each latent feature is a linear combination of other latent features, so the weighted combination coefficients of the self-expressive layer are used to construct a new refined affinity graph for representing the data structure. We conduct experiments on four datasets to demonstrate the superiority of the representation ability of our proposed model over the state-of-the-art methods.