 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomalyGFM: Graph Foundation Model for Zero/Few-shot Anomaly Detection
Feb 13, 2025Graph anomaly detection (GAD) aims to identify abnormal nodes that differ from the majority of the nodes in a graph, which has been attracting significant attention in recent years. Existing generalist graph models have achieved remarkable success in different graph tasks but struggle to generalize to the GAD task. This limitation arises from their difficulty in learning generalized knowledge for capturing the inherently infrequent, irregular and heterogeneous abnormality patterns in graphs from different domains. To address this challenge, we propose AnomalyGFM, a GAD-oriented graph foundation model that supports zero-shot inference and few-shot prompt tuning for GAD in diverse graph datasets. One key insight is that graph-agnostic representations for normal and abnormal classes are required to support effective zero/few-shot GAD across different graphs. Motivated by this, AnomalyGFM is pre-trained to align data-independent, learnable normal and abnormal class prototypes with node representation residuals (i.e., representation deviation of a node from its neighbors). The residual features essentially project the node information into a unified feature space where we can effectively measure the abnormality of nodes from different graphs in a consistent way. This provides a driving force for the learning of graph-agnostic, discriminative prototypes for the normal and abnormal classes, which can be used to enable zero-shot GAD on new graphs, including very large-scale graphs. If there are few-shot labeled normal nodes available in the new graphs, AnomalyGFM can further support prompt tuning to leverage these nodes for better adaptation. Comprehensive experiments on 11 widely-used GAD datasets with real anomalies, demonstrate that AnomalyGFM significantly outperforms state-of-the-art competing methods under both zero- and few-shot GAD settings.
Hierarchical Consensus Network for Multiview Feature Learning
Feb 04, 2025



Multiview feature learning aims to learn discriminative features by integrating the distinct information in each view. However, most existing methods still face significant challenges in learning view-consistency features, which are crucial for effective multiview learning. Motivated by the theories of CCA and contrastive learning in multiview feature learning, we propose the hierarchical consensus network (HCN) in this paper. The HCN derives three consensus indices for capturing the hierarchical consensus across views, which are classifying consensus, coding consensus, and global consensus, respectively. Specifically, classifying consensus reinforces class-level correspondence between views from a CCA perspective, while coding consensus closely resembles contrastive learning and reflects contrastive comparison of individual instances. Global consensus aims to extract consensus information from two perspectives simultaneously. By enforcing the hierarchical consensus, the information within each view is better integrated to obtain more comprehensive and discriminative features. The extensive experimental results obtained on four multiview datasets demonstrate that the proposed method significantly outperforms several state-of-the-art methods.
Zero-shot Generalist Graph Anomaly Detection with Unified Neighborhood Prompts
Oct 18, 2024



Graph anomaly detection (GAD), which aims to identify nodes in a graph that significantly deviate from normal patterns, plays a crucial role in broad application domains. Existing GAD methods, whether supervised or unsupervised, are one-model-for-one-dataset approaches, i.e., training a separate model for each graph dataset. This limits their applicability in real-world scenarios where training on the target graph data is not possible due to issues like data privacy. To overcome this limitation, we propose a novel zero-shot generalist GAD approach UNPrompt that trains a one-for-all detection model, requiring the training of one GAD model on a single graph dataset and then effectively generalizing to detect anomalies in other graph datasets without any retraining or fine-tuning. The key insight in UNPrompt is that i) the predictability of latent node attributes can serve as a generalized anomaly measure and ii) highly generalized normal and abnormal graph patterns can be learned via latent node attribute prediction in a properly normalized node attribute space. UNPrompt achieves generalist GAD through two main modules: one module aligns the dimensionality and semantics of node attributes across different graphs via coordinate-wise normalization in a projected space, while another module learns generalized neighborhood prompts that support the use of latent node attribute predictability as an anomaly score across different datasets. Extensive experiments on real-world GAD datasets show that UNPrompt significantly outperforms diverse competing methods under the generalist GAD setting, and it also has strong superiority under the one-model-for-one-dataset setting.
Replay-and-Forget-Free Graph Class-Incremental Learning: A Task Profiling and Prompting Approach
Oct 14, 2024Class-incremental learning (CIL) aims to continually learn a sequence of tasks, with each task consisting of a set of unique classes. Graph CIL (GCIL) follows the same setting but needs to deal with graph tasks (e.g., node classification in a graph). The key characteristic of CIL lies in the absence of task identifiers (IDs) during inference, which causes a significant challenge in separating classes from different tasks (i.e., inter-task class separation). Being able to accurately predict the task IDs can help address this issue, but it is a challenging problem. In this paper, we show theoretically that accurate task ID prediction on graph data can be achieved by a Laplacian smoothing-based graph task profiling approach, in which each graph task is modeled by a task prototype based on Laplacian smoothing over the graph. It guarantees that the task prototypes of the same graph task are nearly the same with a large smoothing step, while those of different tasks are distinct due to differences in graph structure and node attributes. Further, to avoid the catastrophic forgetting of the knowledge learned in previous graph tasks, we propose a novel graph prompting approach for GCIL which learns a small discriminative graph prompt for each task, essentially resulting in a separate classification model for each task. The prompt learning requires the training of a single graph neural network (GNN) only once on the first task, and no data replay is required thereafter, thereby obtaining a GCIL model being both replay-free and forget-free. Extensive experiments on four GCIL benchmarks show that i) our task prototype-based method can achieve 100% task ID prediction accuracy on all four datasets, ii) our GCIL model significantly outperforms state-of-the-art competing methods by at least 18% in average CIL accuracy, and iii) our model is fully free of forgetting on the four datasets.
Graph Continual Learning with Debiased Lossless Memory Replay
Apr 17, 2024Real-life graph data often expands continually, rendering the learning of graph neural networks (GNNs) on static graph data impractical. Graph continual learning (GCL) tackles this problem by continually adapting GNNs to the expanded graph of the current task while maintaining the performance over the graph of previous tasks. Memory replay-based methods, which aim to replay data of previous tasks when learning new tasks, have been explored as one principled approach to mitigate the forgetting of the knowledge learned from the previous tasks. In this paper we extend this methodology with a novel framework, called Debiased Lossless Memory replay (DeLoMe). Unlike existing methods that sample nodes/edges of previous graphs to construct the memory, DeLoMe learns small lossless synthetic node representations as the memory. The learned memory can not only preserve the graph data privacy but also capture the holistic graph information, for which the sampling-based methods are not viable. Further, prior methods suffer from bias toward the current task due to the data imbalance between the classes in the memory data and the current data. A debiased GCL loss function is devised in DeLoMe to effectively alleviate this bias. Extensive experiments on four graph datasets show the effectiveness of DeLoMe under both class- and task-incremental learning settings.
Graph-level Anomaly Detection via Hierarchical Memory Networks
Jul 03, 2023Graph-level anomaly detection aims to identify abnormal graphs that exhibit deviant structures and node attributes compared to the majority in a graph set. One primary challenge is to learn normal patterns manifested in both fine-grained and holistic views of graphs for identifying graphs that are abnormal in part or in whole. To tackle this challenge, we propose a novel approach called Hierarchical Memory Networks (HimNet), which learns hierarchical memory modules -- node and graph memory modules -- via a graph autoencoder network architecture. The node-level memory module is trained to model fine-grained, internal graph interactions among nodes for detecting locally abnormal graphs, while the graph-level memory module is dedicated to the learning of holistic normal patterns for detecting globally abnormal graphs. The two modules are jointly optimized to detect both locally- and globally-anomalous graphs. Extensive empirical results on 16 real-world graph datasets from various domains show that i) HimNet significantly outperforms the state-of-art methods and ii) it is robust to anomaly contamination. Codes are available at: https://github.com/Niuchx/HimNet.
Affinity Uncertainty-based Hard Negative Mining in Graph Contrastive Learning
Jan 31, 2023Hard negative mining has shown effective in enhancing self-supervised contrastive learning (CL) on diverse data types, including graph contrastive learning (GCL). Existing hardness-aware CL methods typically treat negative instances that are most similar to the anchor instance as hard negatives, which helps improve the CL performance, especially on image data. However, this approach often fails to identify the hard negatives but leads to many false negatives on graph data. This is mainly due to that the learned graph representations are not sufficiently discriminative due to over-smooth representations and/or non-i.i.d. issues in graph data. To tackle this problem, this paper proposes a novel approach that builds a discriminative model on collective affinity information (i.e, two sets of pairwise affinities between the negative instances and the anchor instance) to mine hard negatives in GCL. In particular, the proposed approach evaluates how confident/uncertain the discriminative model is about the affinity of each negative instance to an anchor instance to determine its hardness weight relative to the anchor instance. This uncertainty information is then incorporated into existing GCL loss functions via a weighting term to enhance their performance. The enhanced GCL is theoretically grounded that the resulting GCL loss is equivalent to a triplet loss with an adaptive margin being exponentially proportional to the learned uncertainty of each negative instance. Extensive experiments on 10 graph datasets show that our approach i) consistently enhances different state-of-the-art GCL methods in both graph and node classification tasks, and ii) significantly improves their robustness against adversarial attacks.
Mutual Teaching for Graph Convolutional Networks
Sep 02, 2020

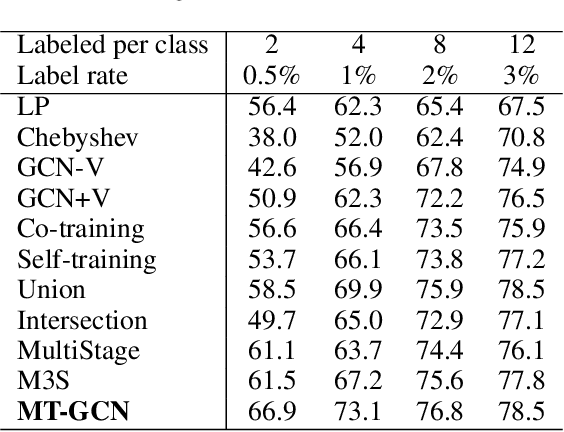
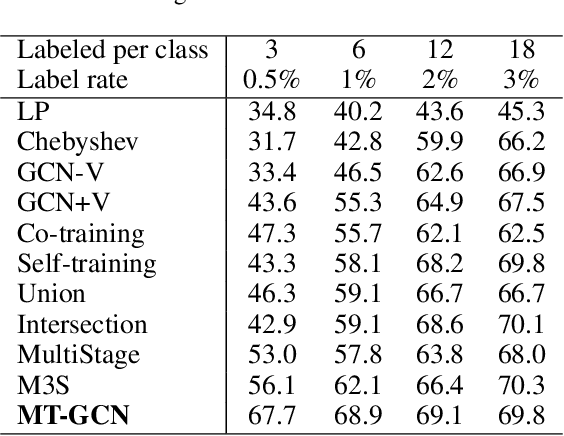
Graph convolutional networks produce good predictions of unlabeled samples due to its transductive label propagation. Since samples have different predicted confidences, we take high-confidence predictions as pseudo labels to expand the label set so that more samples are selected for updating models. We propose a new training method named as mutual teaching, i.e., we train dual models and let them teach each other during each batch. First, each network feeds forward all samples and selects samples with high-confidence predictions. Second, each model is updated by samples selected by its peer network. We view the high-confidence predictions as useful knowledge, and the useful knowledge of one network teaches the peer network with model updating in each batch. In mutual teaching, the pseudo-label set of a network is from its peer network. Since we use the new strategy of network training, performance improves significantly. Extensive experimental results demonstrate that our method achieves superior performance over state-of-the-art methods under very low label rates.
* GCN, 8 pages, 1 figures
Generative approach to unsupervised deep local learning
Jun 28, 2019Most existing feature learning methods optimize inflexible handcrafted features and the affinity matrix is constructed by shallow linear embedding methods. Different from these conventional methods, we pretrain a generative neural network by stacking convolutional autoencoders to learn the latent data representation and then construct an affinity graph with them as a prior. Based on the pretrained model and the constructed graph, we add a self-expressive layer to complete the generative model and then fine-tune it with a new loss function, including the reconstruction loss and a deliberately defined locality-preserving loss. The locality-preserving loss designed by the constructed affinity graph serves as prior to preserve the local structure during the fine-tuning stage, which in turn improves the quality of feature representation effectively. Furthermore, the self-expressive layer between the encoder and decoder is based on the assumption that each latent feature is a linear combination of other latent features, so the weighted combination coefficients of the self-expressive layer are used to construct a new refined affinity graph for representing the data structure. We conduct experiments on four datasets to demonstrate the superiority of the representation ability of our proposed model over the state-of-the-art methods.