 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fast Attention Network for Joint Intent Detection and Slot Filling on Edge Devices
Paper and Code
May 16, 2022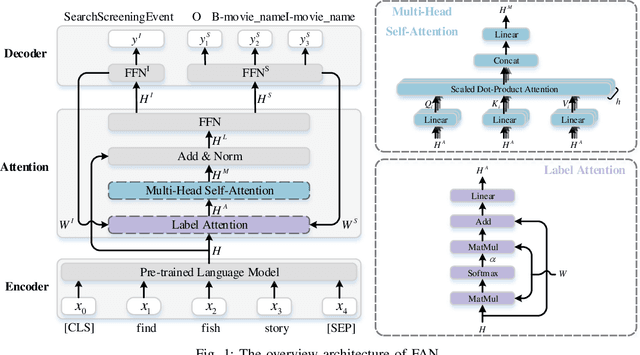



Intent detection and slot filling are two main tasks in natural language understanding and play an essential role in task-oriented dialogue systems. The joint learning of both tasks can improve inference accuracy and is popular in recent works. However, most joint models ignore the inference latency and cannot meet the need to deploy dialogue systems at the edge. In this paper, we propose a Fast Attention Network (FAN) for joint intent detection and slot filling tasks, guaranteeing both accuracy and latency. Specifically, we introduce a clean and parameter-refined attention module to enhance the information exchange between intent and slot, improving semantic accuracy by more than 2%. FAN can be implemented on different encoders and delivers more accurate models at every speed level. Our experiments on the Jetson Nano platform show that FAN inferences fifteen utterances per second with a small accuracy drop, showing its effectiveness and efficiency on edge devices.