 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline GentleAdaBoost -- Technical Report
Sep 09, 2023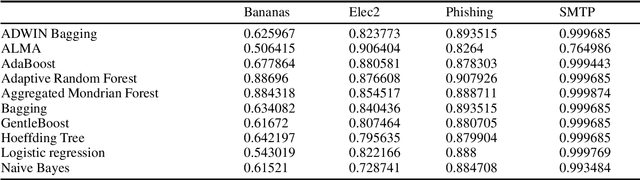
We study the online variant of GentleAdaboost, where we combine a weak learner to a strong learner in an online fashion. We provide an approach to extend the batch approach to an online approach with theoretical justifications through application of line search. Finally we compare our online boosting approach with other online approaches across a variety of benchmark datasets.
Regularize! Don't Mix: Multi-Agent Reinforcement Learning without Explicit Centralized Structures
Sep 19, 2021

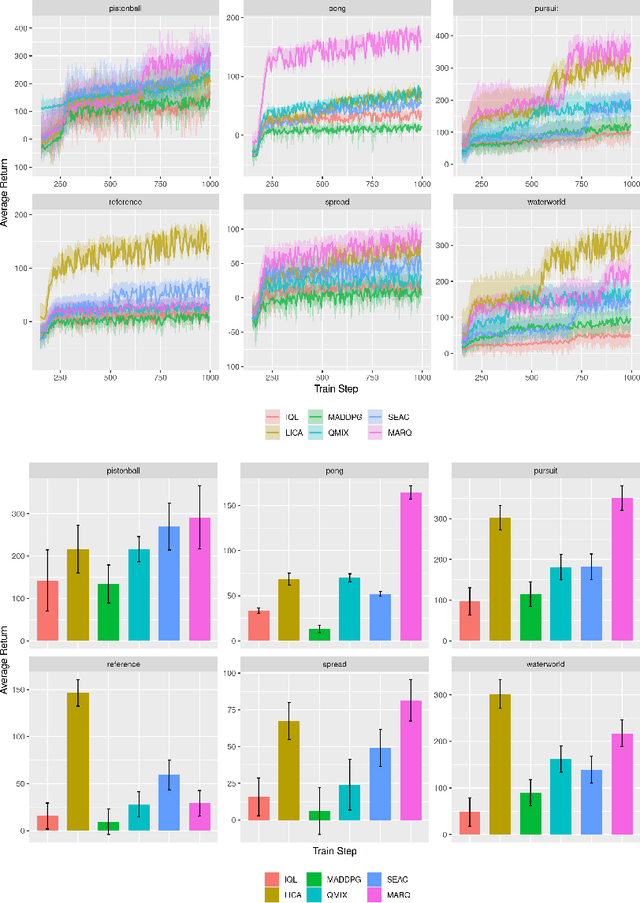
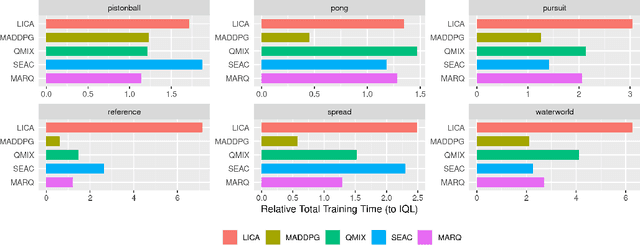
We propose using regularization for Multi-Agent Reinforcement Learning rather than learning explicit cooperative structures called {\em Multi-Agent Regularized Q-learning} (MARQ). Many MARL approaches leverage centralized structures in order to exploit global state information or removing communication constraints when the agents act in a decentralized manner. Instead of learning redundant structures which is removed during agent execution, we propose instead to leverage shared experiences of the agents to regularize the individual policies in order to promote structured exploration. We examine several different approaches to how MARQ can either explicitly or implicitly regularize our policies in a multi-agent setting. MARQ aims to address these limitations in the MARL context through applying regularization constraints which can correct bias in off-policy out-of-distribution agent experiences and promote diverse exploration. Our algorithm is evaluated on several benchmark multi-agent environments and we show that MARQ consistently outperforms several baselines and state-of-the-art algorithms; learning in fewer steps and converging to higher returns.
Dual Behavior Regularized Reinforcement Learning
Sep 19, 2021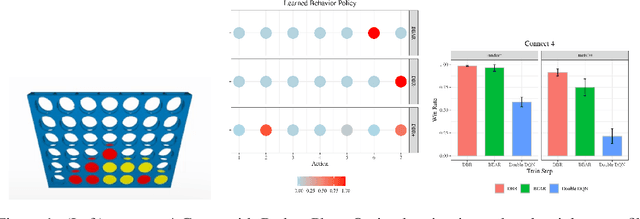
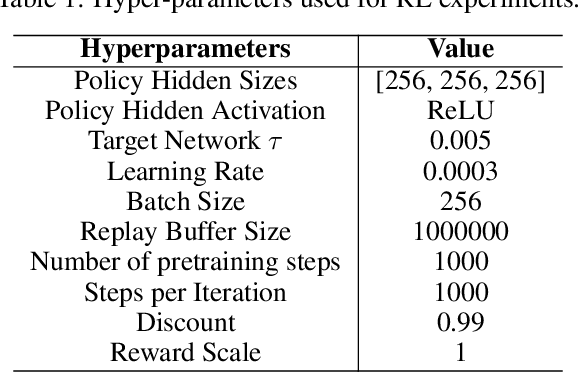
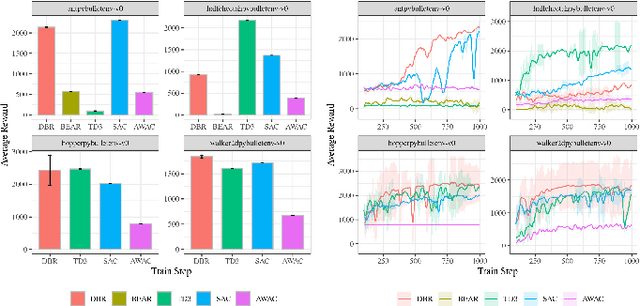
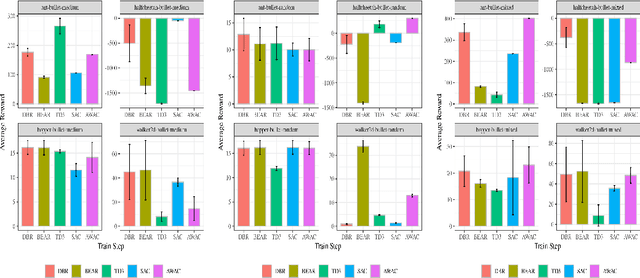
Reinforcement learning has been shown to perform a range of complex tasks through interaction with an environment or collected leveraging experience. However, many of these approaches presume optimal or near optimal experiences or the presence of a consistent environment. In this work we propose dual, advantage-based behavior policy based on counterfactual regret minimization. We demonstrate the flexibility of this approach and how it can be adapted to online contexts where the environment is available to collect experiences and a variety of other contexts. We demonstrate this new algorithm can outperform several strong baseline models in different contexts based on a range of continuous environments. Additional ablations provide insights into how our dual behavior regularized reinforcement learning approach is designed compared with other plausible modifications and demonstrates its ability to generalize.
Greedy UnMixing for Q-Learning in Multi-Agent Reinforcement Learning
Sep 19, 2021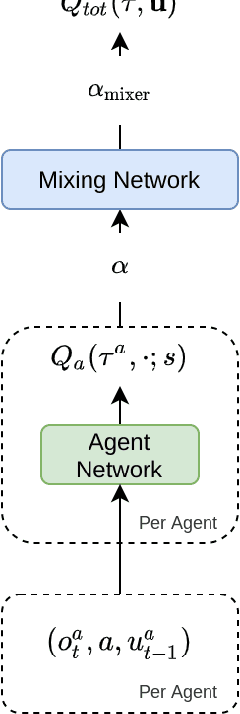

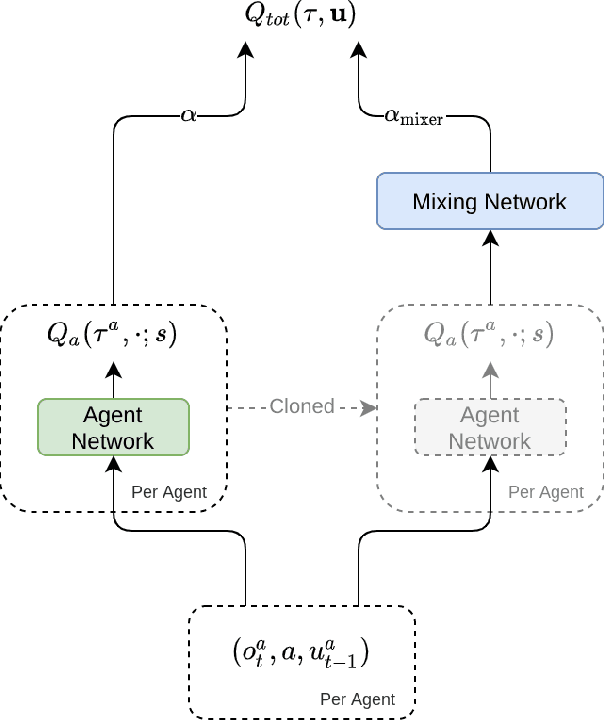
This paper introduces Greedy UnMix (GUM) for cooperative multi-agent reinforcement learning (MARL). Greedy UnMix aims to avoid scenarios where MARL methods fail due to overestimation of values as part of the large joint state-action space. It aims to address this through a conservative Q-learning approach through restricting the state-marginal in the dataset to avoid unobserved joint state action spaces, whilst concurrently attempting to unmix or simplify the problem space under the centralized training with decentralized execution paradigm. We demonstrate the adherence to Q-function lower bounds in the Q-learning for MARL scenarios, and demonstrate superior performance to existing Q-learning MARL approaches as well as more general MARL algorithms over a set of benchmark MARL tasks, despite its relative simplicity compared with state-of-the-art approaches.
Residual Networks Behave Like Boosting Algorithms
Sep 25, 2019



We show that Residual Networks (ResNet) is equivalent to boosting feature representation, without any modification to the underlying ResNet training algorithm. A regret bound based on Online Gradient Boosting theory is proved and suggests that ResNet could achieve Online Gradient Boosting regret bounds through neural network architectural changes with the addition of a shrinkage parameter in the identity skip-connections and using residual modules with max-norm bounds. Through this relation between ResNet and Online Boosting, novel feature representation boosting algorithms can be constructed based on altering residual modules. We demonstrate this through proposing decision tree residual modules to construct a new boosted decision tree algorithm and demonstrating generalization error bounds for both approaches; relaxing constraints within BoostResNet algorithm to allow it to be trained in an out-of-core manner. We evaluate convolution ResNet with and without shrinkage modifications to demonstrate its efficacy, and demonstrate that our online boosted decision tree algorithm is comparable to state-of-the-art offline boosted decision tree algorithms without the drawback of offline approaches.
TreeGrad: Transferring Tree Ensembles to Neural Networks
Apr 25, 2019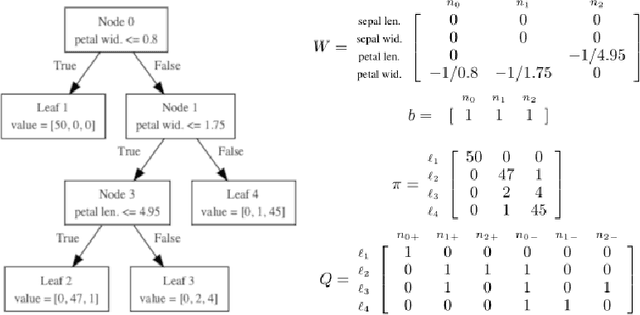
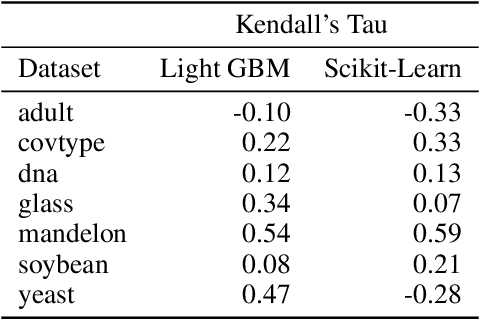
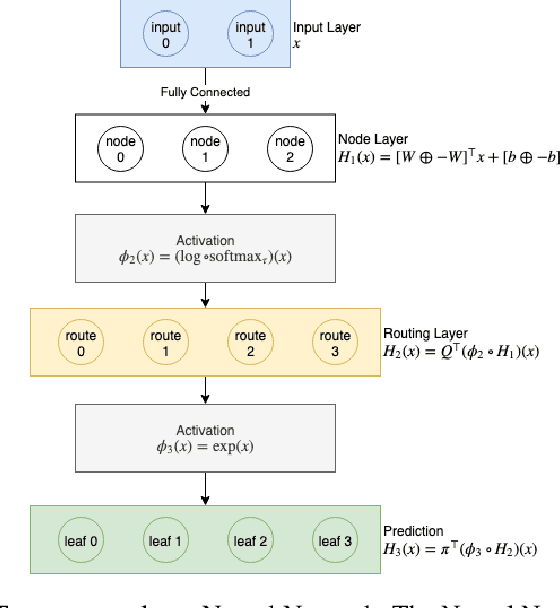

Gradient Boosting Decision Tree (GBDT) are popular machine learning algorithms with implementations such as LightGBM and in popular machine learning toolkits like Scikit-Learn. Many implementations can only produce trees in an offline manner and in a greedy manner. We explore ways to convert existing GBDT implementations to known neural network architectures with minimal performance loss in order to allow decision splits to be updated in an online manner and provide extensions to allow splits points to be altered as a neural architecture search problem. We provide learning bounds for our neural network.
Automatic Induction of Neural Network Decision Tree Algorithms
Nov 26, 2018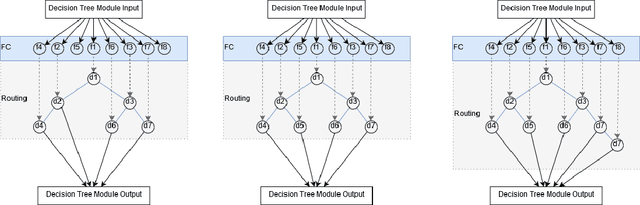
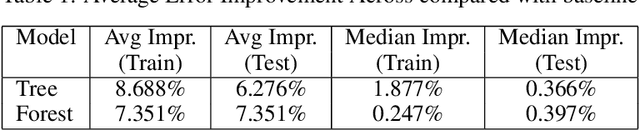
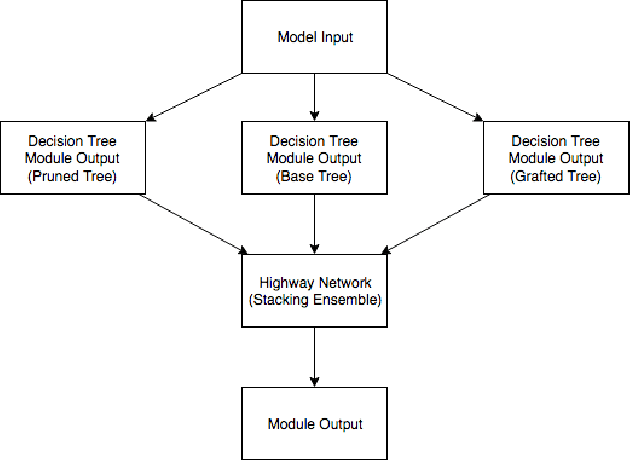

This work presents an approach to automatically induction for non-greedy decision trees constructed from neural network architecture. This construction can be used to transfer weights when growing or pruning a decision tree, allowing non-greedy decision tree algorithms to automatically learn and adapt to the ideal architecture. In this work, we examine the underpinning ideas within ensemble modelling and Bayesian model averaging which allow our neural network to asymptotically approach the ideal architecture through weights transfer. Experimental results demonstrate that this approach improves models over fixed set of hyperparameters for decision tree models and decision forest models.
Diverse Online Feature Selection
Jun 12, 2018Online feature selection has been an active research area in recent years. We propose a novel diverse online feature selection method based on Determinantal Point Processes (DPP). Our model aims to provide diverse features which can be composed in either a supervised or unsupervised framework. The framework aims to promote diversity based on the kernel produced on a feature level, through at most three stages: feature sampling, local criteria and global criteria for feature selection. In the feature sampling, we sample incoming stream of features using conditional DPP. The local criteria is used to assess and select streamed features (i.e. only when they arrive), we use unsupervised scale invariant methods to remove redundant features and optionally supervised methods to introduce label information to assess relevant features. Lastly, the global criteria uses regularization methods to select a global optimal subset of features. This three stage procedure continues until there are no more features arriving or some predefined stopping condition is met. We demonstrate based on experiments conducted on that this approach yields better compactness, is comparable and in some instances outperforms other state-of-the-art online feature selection methods.