 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularize! Don't Mix: Multi-Agent Reinforcement Learning without Explicit Centralized Structures
Sep 19, 2021

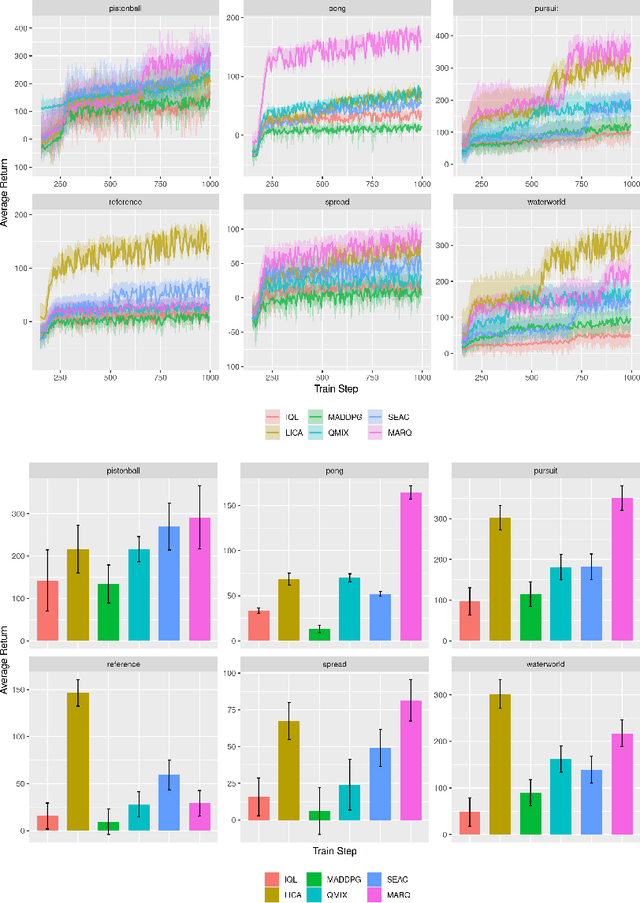
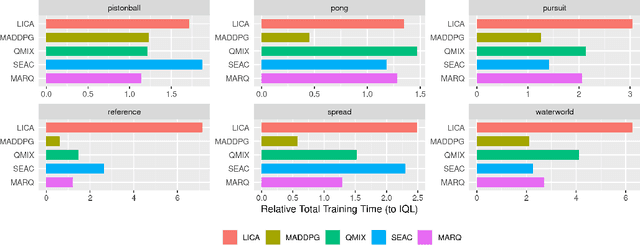
We propose using regularization for Multi-Agent Reinforcement Learning rather than learning explicit cooperative structures called {\em Multi-Agent Regularized Q-learning} (MARQ). Many MARL approaches leverage centralized structures in order to exploit global state information or removing communication constraints when the agents act in a decentralized manner. Instead of learning redundant structures which is removed during agent execution, we propose instead to leverage shared experiences of the agents to regularize the individual policies in order to promote structured exploration. We examine several different approaches to how MARQ can either explicitly or implicitly regularize our policies in a multi-agent setting. MARQ aims to address these limitations in the MARL context through applying regularization constraints which can correct bias in off-policy out-of-distribution agent experiences and promote diverse exploration. Our algorithm is evaluated on several benchmark multi-agent environments and we show that MARQ consistently outperforms several baselines and state-of-the-art algorithms; learning in fewer steps and converging to higher returns.
Dual Behavior Regularized Reinforcement Learning
Sep 19, 2021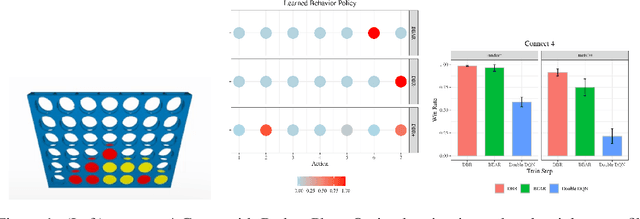
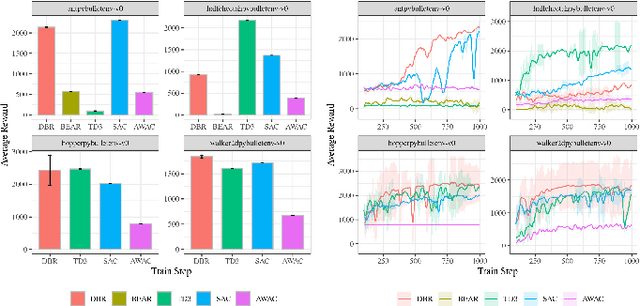
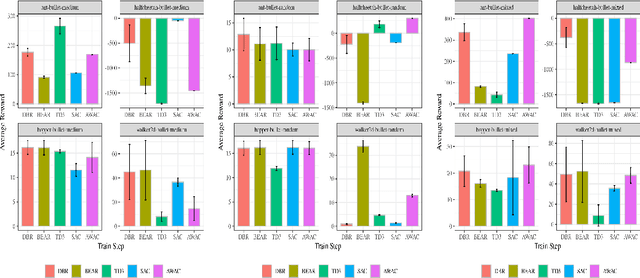
Reinforcement learning has been shown to perform a range of complex tasks through interaction with an environment or collected leveraging experience. However, many of these approaches presume optimal or near optimal experiences or the presence of a consistent environment. In this work we propose dual, advantage-based behavior policy based on counterfactual regret minimization. We demonstrate the flexibility of this approach and how it can be adapted to online contexts where the environment is available to collect experiences and a variety of other contexts. We demonstrate this new algorithm can outperform several strong baseline models in different contexts based on a range of continuous environments. Additional ablations provide insights into how our dual behavior regularized reinforcement learning approach is designed compared with other plausible modifications and demonstrates its ability to generalize.
Greedy UnMixing for Q-Learning in Multi-Agent Reinforcement Learning
Sep 19, 2021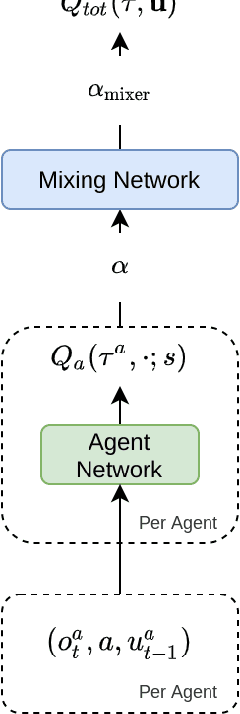

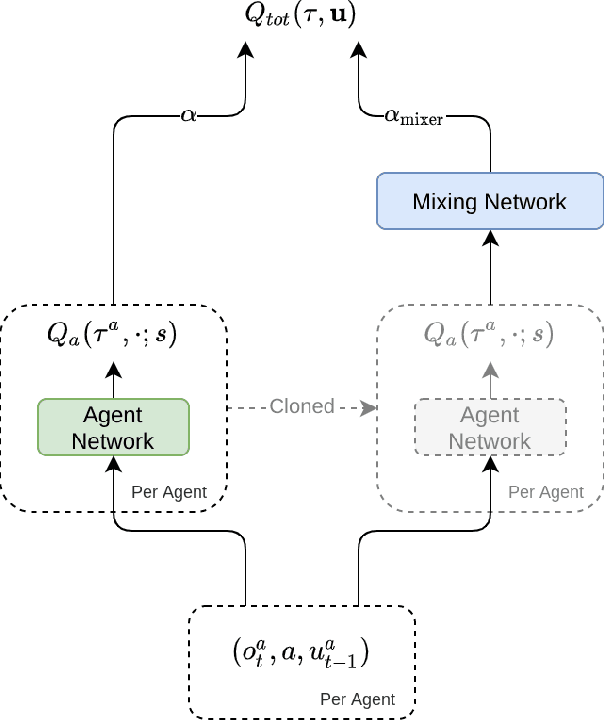
This paper introduces Greedy UnMix (GUM) for cooperative multi-agent reinforcement learning (MARL). Greedy UnMix aims to avoid scenarios where MARL methods fail due to overestimation of values as part of the large joint state-action space. It aims to address this through a conservative Q-learning approach through restricting the state-marginal in the dataset to avoid unobserved joint state action spaces, whilst concurrently attempting to unmix or simplify the problem space under the centralized training with decentralized execution paradigm. We demonstrate the adherence to Q-function lower bounds in the Q-learning for MARL scenarios, and demonstrate superior performance to existing Q-learning MARL approaches as well as more general MARL algorithms over a set of benchmark MARL tasks, despite its relative simplicity compared with state-of-the-art approaches.