 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Behavior Regularized Reinforcement Learning
Paper and Code
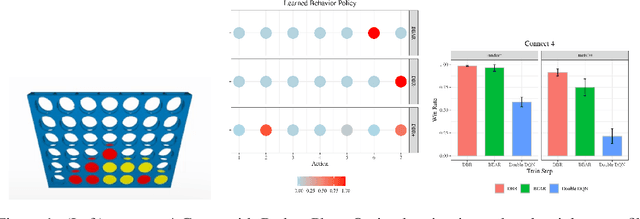
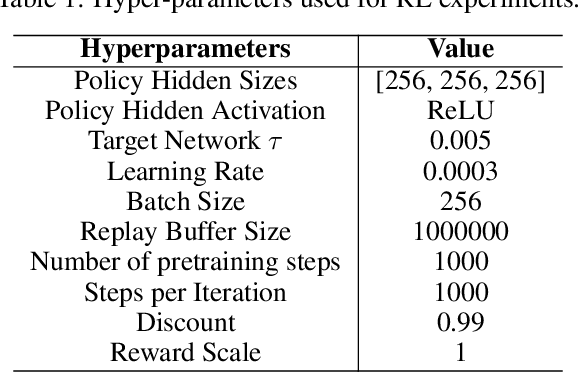
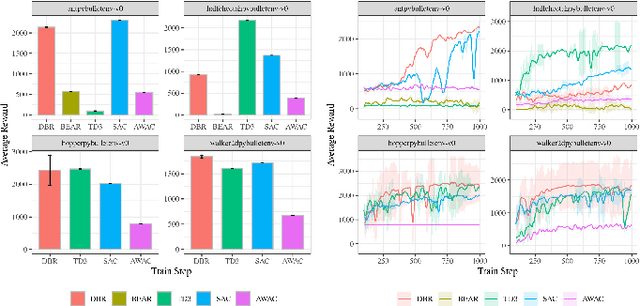
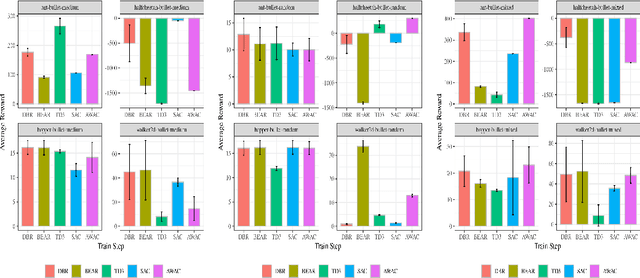
Reinforcement learning has been shown to perform a range of complex tasks through interaction with an environment or collected leveraging experience. However, many of these approaches presume optimal or near optimal experiences or the presence of a consistent environment. In this work we propose dual, advantage-based behavior policy based on counterfactual regret minimization. We demonstrate the flexibility of this approach and how it can be adapted to online contexts where the environment is available to collect experiences and a variety of other contexts. We demonstrate this new algorithm can outperform several strong baseline models in different contexts based on a range of continuous environments. Additional ablations provide insights into how our dual behavior regularized reinforcement learning approach is designed compared with other plausible modifications and demonstrates its ability to generalize.