 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreedy UnMixing for Q-Learning in Multi-Agent Reinforcement Learning
Paper and Code
Sep 19, 2021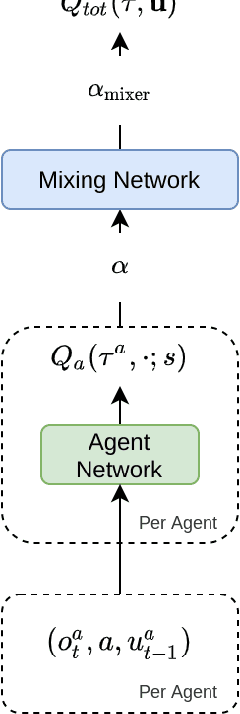

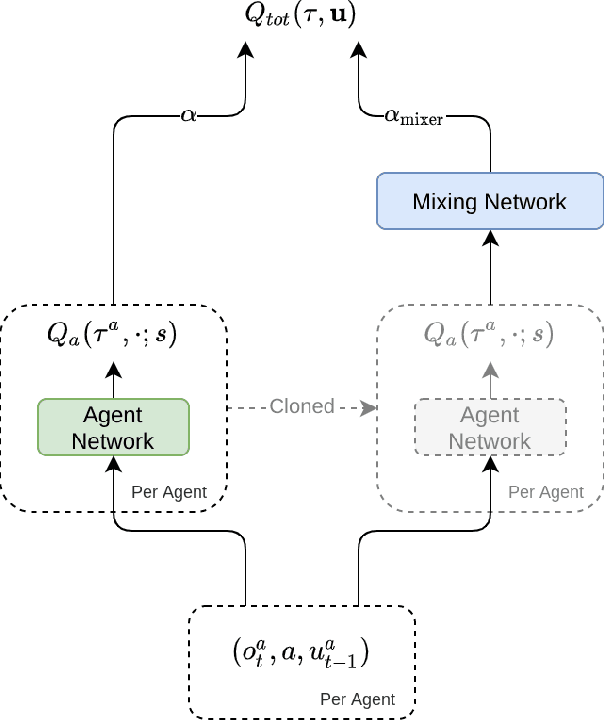
This paper introduces Greedy UnMix (GUM) for cooperative multi-agent reinforcement learning (MARL). Greedy UnMix aims to avoid scenarios where MARL methods fail due to overestimation of values as part of the large joint state-action space. It aims to address this through a conservative Q-learning approach through restricting the state-marginal in the dataset to avoid unobserved joint state action spaces, whilst concurrently attempting to unmix or simplify the problem space under the centralized training with decentralized execution paradigm. We demonstrate the adherence to Q-function lower bounds in the Q-learning for MARL scenarios, and demonstrate superior performance to existing Q-learning MARL approaches as well as more general MARL algorithms over a set of benchmark MARL tasks, despite its relative simplicity compared with state-of-the-art approaches.