 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Non-negative Matrix Factorization for Short Texts Topic Modeling with Mutual Information
Paper and Code
May 26, 2022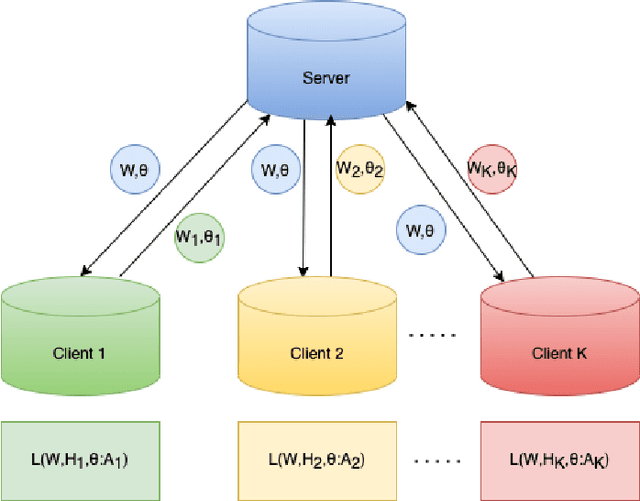
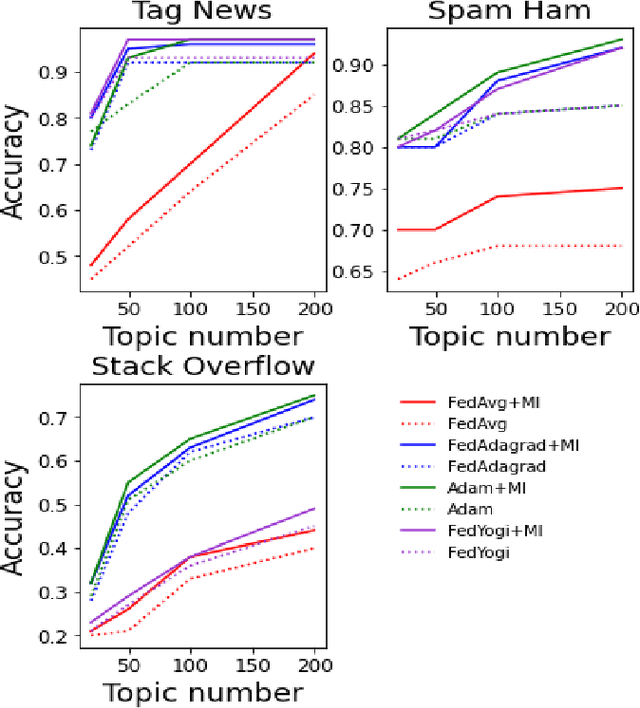
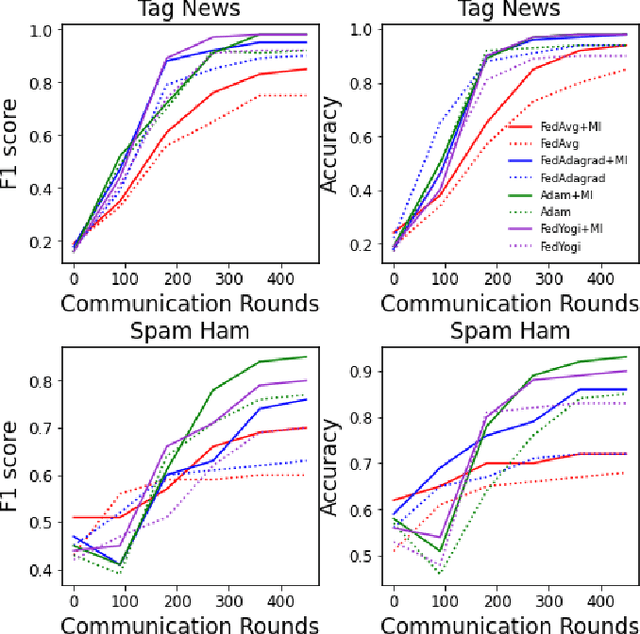
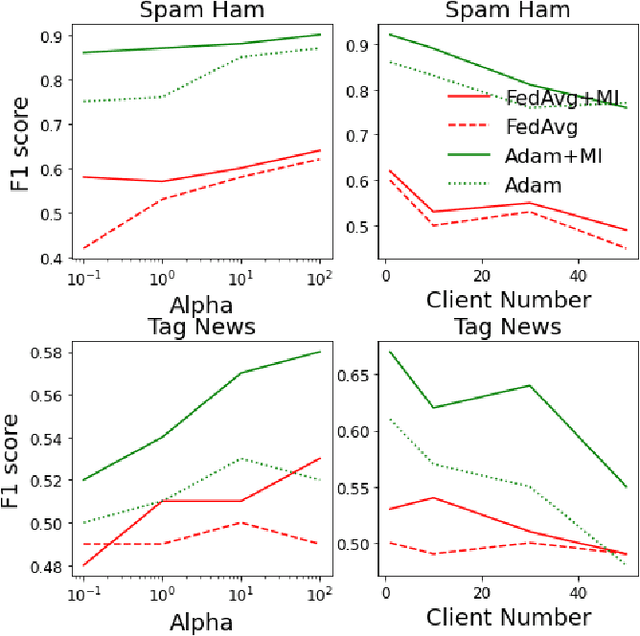
Non-negative matrix factorization (NMF) based topic modeling is widely used in natural language processing (NLP) to uncover hidden topics of short text documents. Usually, training a high-quality topic model requires large amount of textual data. In many real-world scenarios, customer textual data should be private and sensitive, precluding uploading to data centers. This paper proposes a Federated NMF (FedNMF) framework, which allows multiple clients to collaboratively train a high-quality NMF based topic model with locally stored data. However, standard federated learning will significantly undermine the performance of topic models in downstream tasks (e.g., text classification) when the data distribution over clients is heterogeneous. To alleviate this issue, we further propose FedNMF+MI, which simultaneously maximizes the mutual information (MI) between the count features of local texts and their topic weight vectors to mitigate the performance degradation. Experimental results show that our FedNMF+MI methods outperform Federated Latent Dirichlet Allocation (FedLDA) and the FedNMF without MI methods for short texts by a significant margin on both coherence score and classification F1 score.