 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Semantic Composition with Syntactic Hypergraph for Video Question Answering
Paper and Code

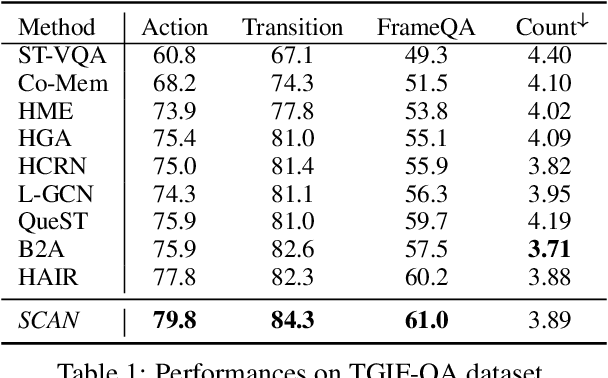
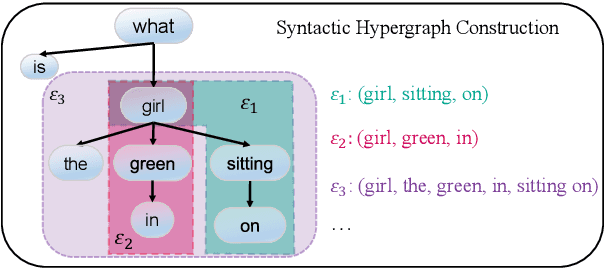
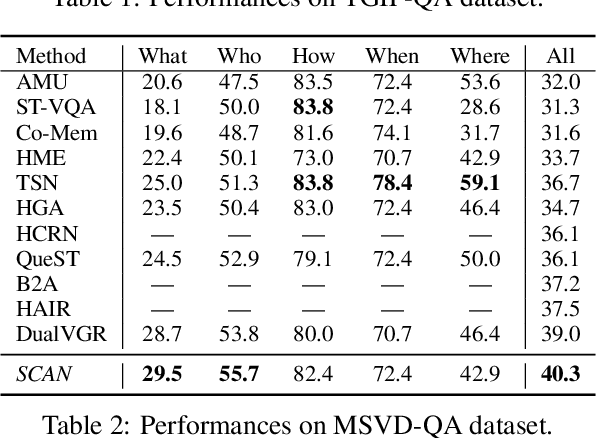
A key challenge in video question answering is how to realize the cross-modal semantic alignment between textual concepts and corresponding visual objects. Existing methods mostly seek to align the word representations with the video regions. However, word representations are often not able to convey a complete description of textual concepts, which are in general described by the compositions of certain words. To address this issue, we propose to first build a syntactic dependency tree for each question with an off-the-shelf tool and use it to guide the extraction of meaningful word compositions. Based on the extracted compositions, a hypergraph is further built by viewing the words as nodes and the compositions as hyperedges. Hypergraph convolutional networks (HCN) are then employed to learn the initial representations of word compositions. Afterwards, an optimal transport based method is proposed to perform cross-modal semantic alignment for the textual and visual semantic space. To reflect the cross-modal influences, the cross-modal information is incorporated into the initial representations, leading to a model named cross-modality-aware syntactic HCN. Experimental results on three benchmarks show that our method outperforms all strong baselines. Further analyses demonstrate the effectiveness of each component, and show that our model is good at modeling different levels of semantic compositions and filtering out irrelevant information.